JOIN
JOIN은 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현해 줍니다. 이러한 JOIN은 보통 SELECT 문과 함께 자주 사용됩니다. → TCP School JOIN
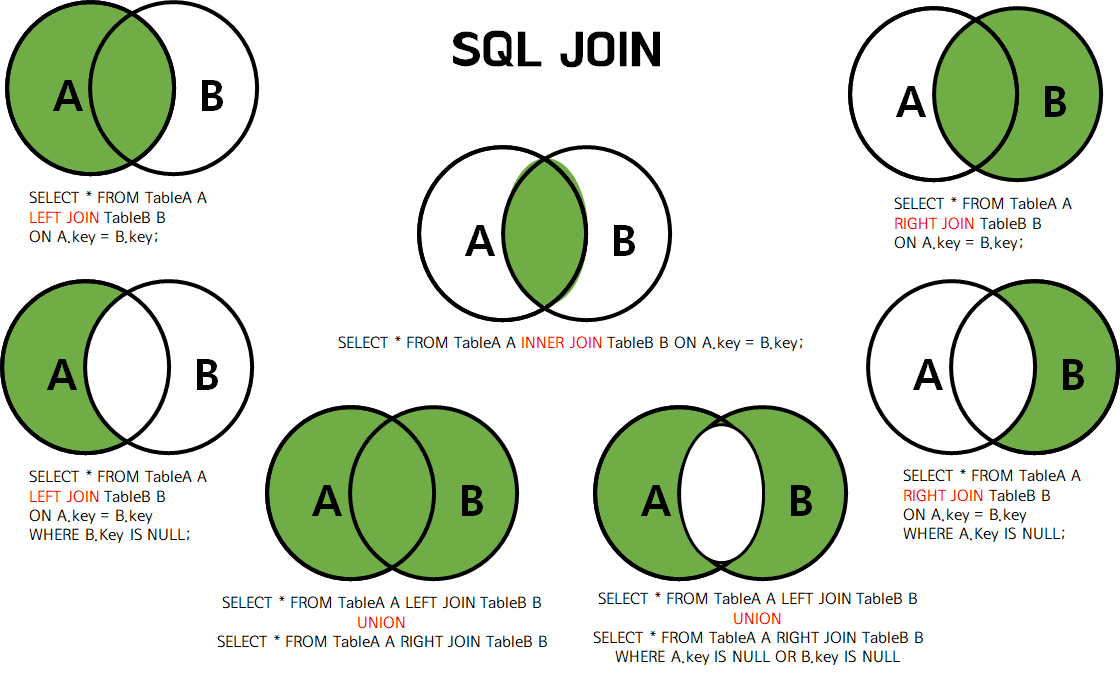
SQL을 접하면서 DB를 설계하고 사용할 때 JOIN은 가장 자주 사용하게 되는 개념이라고 할 수 있을 정도로 많이 쓰인다. 항상 성능에 대해서 고민하게 되는 친구지만, 나름 RDBS(관계형데이터베이스)의 꽃이라고 생각되는 JOIN에 대해서 정리해 보려고 한다.
1. 조인과 관계대수
관계대수란 릴레이션(테이블)에서 데이터를 추출하는데 사용되는 언어라고 할 수 있다. 관계형 데이터베이스 이론의 코드 박사(codd)는 이렇게 정의했다.
- 관계 대수: 원하는 정보를 어떻게(How) 찾는지를 명시하는 절차적 언어
- 관계 해석: 어떤(what) 데이터를 찾는지 만 명시하는 선언적 언어
SQL 언어는 관계해석을 기반으로 하며 관계 대수 개념이 혼합되어 있고, DBMS 내부에서는 관계 대수에 기반을 둔 연산을 수행한다. 관계 대수를 정리해보면 다음 과 같다.
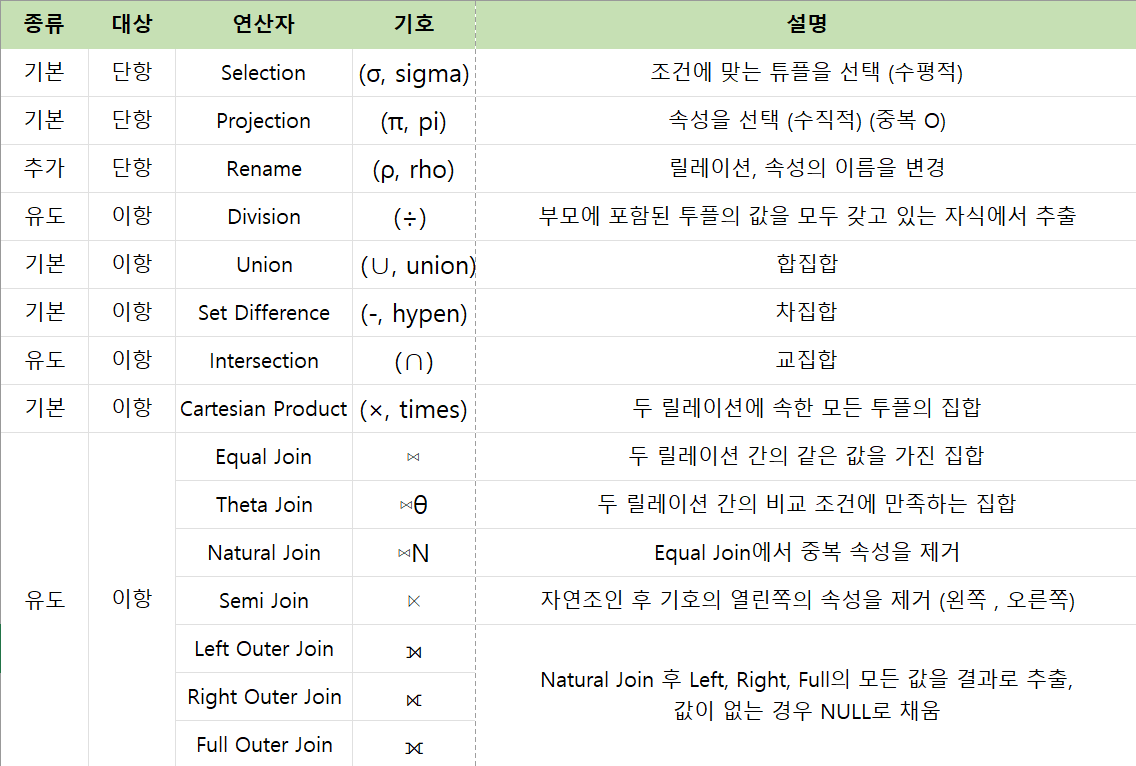
여기서 Join은 유도된 연산자로 Cartesian Product 와 Selection을 함께 실행하여 얻은 결과와 동일하다.
다른건 다 감이 오는데
카티전 프로덕트..? 이게 뭘까 싶을 수 있다.카티전 프로덕트는 집합에서 곱의 개념으로 A= {a, b, c} , B = {1, 2} 일 때 (a,1), (a, 2), (b,1), (b,2), (c, 1), (c,2) 처럼 나타 낼 수 있다. 엄청나게 많은 결과를 생성하기 때문에 많이 사용되지는 않는다.
2. 다양한 조인들...
관계 대수에서 언급된 조인들을 하나씩 살펴 보자
Theta Join(세타 조인), Equal Join(동등 조인), Natural Join(자연 조인)
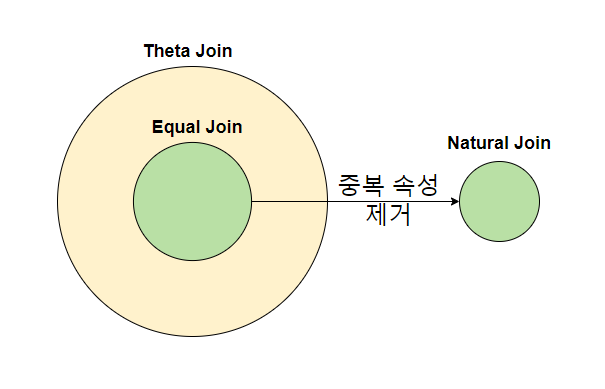
그림처럼 비교 조건 (<, =, >)을 만족하는 Join이 Theta Join이고 그중 비교 조건이 (=)일 때 Equal Join이 된다.
간혹 Inner Join이 곧 Equal Join이라고 생각 하는 경우가 있는데, 엄밀히 따지자면 틀린 이야기다. Outer Join에서도 Equal Join처럼 동등 비교 조건문이 들어갈 수 있기도 하고, Inner Join사용시에 Equal Join도 사용 가능한 것으로 생각하면 된다.
Equal Join에서 중복 속성을 제거하게 되면 Natural Join이 됩니다. Natural Join은 다음과 같이 두 테이블에 같은 이름의 열이 있을 때 생략하여 사용 가능하다.
SELECT * FROM A NATURAL JOIN B;Inner Join
그림에서 보이는 것처럼 교집합을 나타낸다.
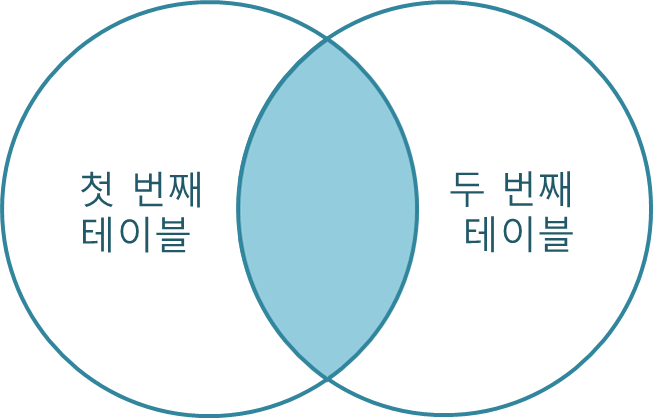
출처: TCPschool
아래 처럼 작성할 수 있다.
SELECT * FROM A JOIN B ON A.id = B.id;Outer Join
Inner Join의 결과로 나오지 않는 행도 NULL값으로 포함해서 결과를 나타내는 Join이다.
어느 쪽을 기준으로 합치냐에 따라서 Left Join , Right Join으로 나뉜다.
Left Join
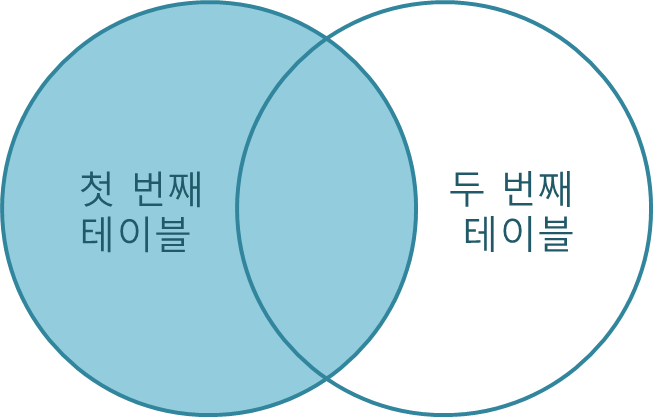
출처: TCPschool
첫 번째 테이블을 기준으로 두 번째 테이블을 조합하는 Join이다. ON절의 조건을 만족하지 않더라도 첫 번째 테이블을 표시하고, 두 번째 테이블의 필드를 NULL로 표시한다.
SELECT * FROM A LEFT JOIN B ON A.id = B.id;Right Join
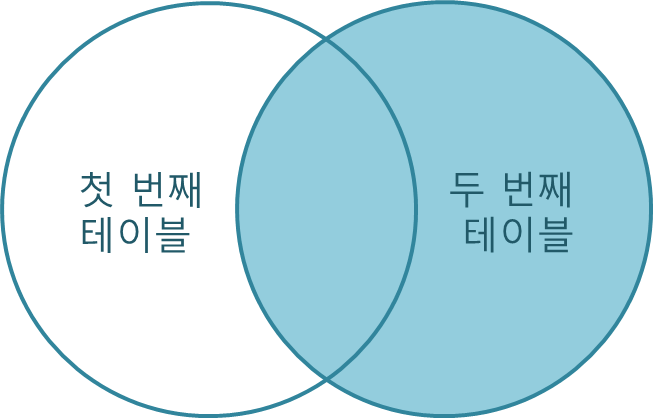
출처: TCPschool
Left Join과는 반대로 두 번째 테이블을 기준으로 첫 번째 테이블을 조합하는 Join이다. ON절의 조건을 만족하지 않더라도 두 번째 테이블을 표시하고, 첫 번째 테이블의 필드를 NULL로 표시한다.
SELECT * FROM A RIGHT JOIN B ON A.id = B.id;Cross Join
Cross Join 은 관계 대수에서 잠깐 언급했던 Cartesian Product 와 같다. 카티전 조인이라고도 한다.
SELECT * FROM A CROSS JOIN B ON A.id = B.id;Self Join
말그대로 자기 자신을 Join하는 방법이다. A 테이블을 각각 Child, Parent로 지정해서 사용한다.
SELECT * FROM A AS parent JOIN A AS childSemi Join
솔직히 처음 들어보는 조인이었다. 조사해보니 세미 조인은 서브 쿼리와 메인 쿼리와의 연결을 위한 유사 조인 이었다...(가짜야가짜)
1:n 관계에서 1의 컬럼만을 사용할 경우 사용할 수 있는데, 집계함수 없이 group by나 distinct를 사용해서 중복제거를 하고 있다면 성능 향상의 효과를 얻을 수 있다.
In 과 Exists를 통해 사용할 수 있다고 한다.
SELECT * FROM A WHERE A.name IN (SELECT B.name FROM B );SELECT * FROM A WHERE EXISTS (SELECT 1 FROM B WHERE A.name = B.name)자세한건 아래 블로그와 참고자료에 첨부한 유튜브 영상을 참고하자
3. 조인 동작 방식
Mysql 에서는 NESTED LOOP JOIN(NL Join)을 사용하고 있으며, 이외에 SORT-MERGE JOIN, HASH JOIN이 있다. Hash Join의 경우 Mysql 8.0부터 지원하고 있다고 한다.
NESTED LOOP JOIN(NL Join)
우리가 프로그래밍에서 사용하는 반복문과 유사한 방식으로 조인을 수행하는데, 반복문 외부에서 먼저 읽어지는 테이블을 Driving Table 이라고 하고, 반복문 내부에서 나중에 읽어지는 테이블을 Driven Table이라고 한다.
Inner Join의 경우에는 옵티마이저가 순서를 조절해 최적화 하기 때문에 쿼리에서의 테이블 순서가 보장 되지 않고, Outer Join의 경우에는 Outer 테이블을 먼저 읽기 때문에 옵티마이저가 선택할 수 없다.
어찌 되었건 옵티마이저의 실행계획을 통해서 Driving Table 과 Driven Table 이 정해졌다면 다음 프로세스를 따른다.
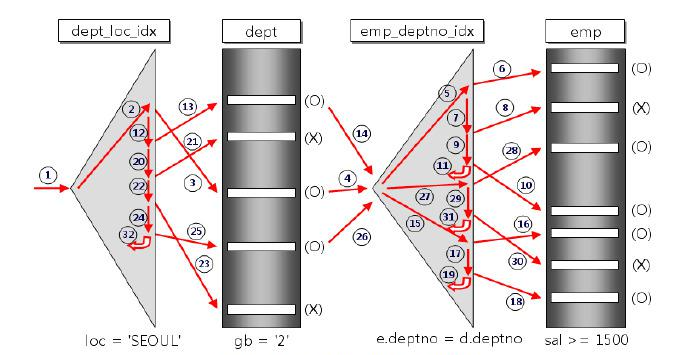
출처: https://coding-factory.tistory.com/756
Driving Table에서 주어진 WHERE 조건문을 만족하는 행을 찾는다. (인덱스 OR 풀스캔등)Driving Table의 조인 KEY 값을 가지고Driven Table에서 조인을 수행 (랜덤 Access)- 반복
Driving Table의 조건을 만족하는 결과가 많을 수록 반복문의 n의 크기가 커지고, Driven Table에 더 많이 접근해야 하므로 성능은 나빠지게 된다.
그러므로 힌트 나 뷰 를 통해서 선택된 Driving Table 의 크기가 작아지도록 해야 한다.
마무리
관계 대수 부터 각 Join과 Join의 동작 방식까지 간단하게 살펴 보았다. Join 때문에 성능 이슈가 많이 생겨서 반정규화를 하거나 아예 NoSQL을 이용하는 경우도 많지만 근-본인 관계형 DB에서 Join에 대해 조금 더 잘 이해하는 계기가 되었다. 조인 동작 방식에 대해서는 추후에 더 자세히 공부해볼 예정이다.
참고자료
-
코드박사 와 데이터베이스 만화
-
관계 대수
“Mysql로 배우는 데이터베이스 개론과 실습” 책 참고
-
TCP School
-
세미 조인
-
조인
-
Equal Join == Inner join ???
-
join 동작 방식
