등수 매기기
📑 문1) 영어 점수와 수학 점수의 평균 점수를 기준으로 학생들의 등수를 매기려고 합니다. 영어 점수와 수학 점수를 담은 2차원 정수 배열 score가 주어질 때, 영어 점수와 수학 점수의 평균을 기준으로 매긴 등수를 담은 배열을 return하도록 solution 함수를 완성해주세요.
입출력 예
| score | result |
|---|---|
| [[80, 70], [90, 50], [40, 70], [50, 80]] | [1, 2, 4, 3] |
| [[80, 70], [70, 80], [30, 50], [90, 100], [100, 90], [100, 100], [10, 30]] | [4, 4, 6, 2, 2, 1, 7] |
입출력 예 설명
입출력 예 #1
- 평균은 각각 75, 70, 55, 65 이므로 등수를 매겨 [1, 2, 4, 3]을 return합니다.
입출력 예 #2
- 평균은 각각 75, 75, 40, 95, 95, 100, 20 이므로 [4, 4, 6, 2, 2, 1, 7] 을 return합니다.
- 공동 2등이 두 명, 공동 4등이 2명 이므로 3등과 5등은 없습니다.
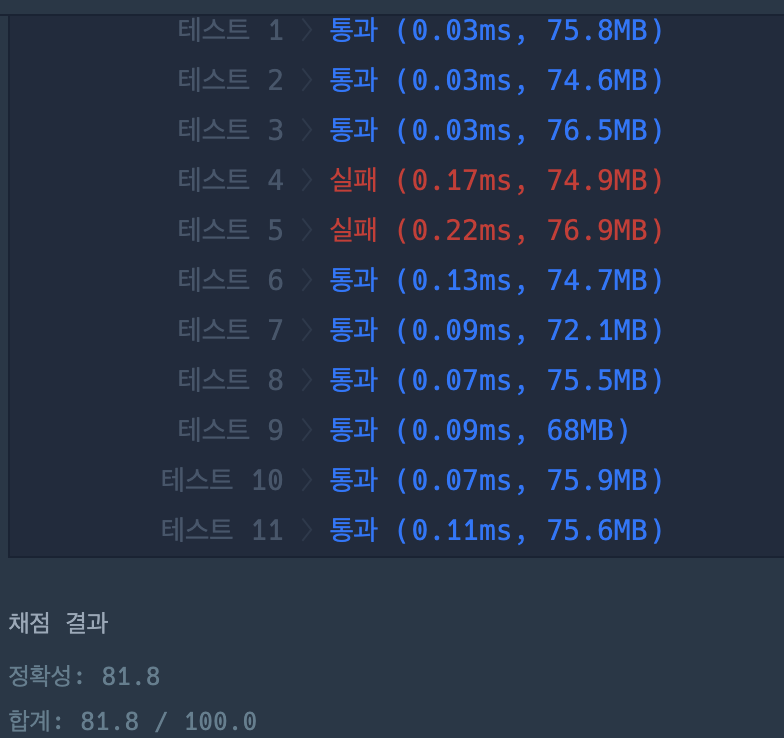
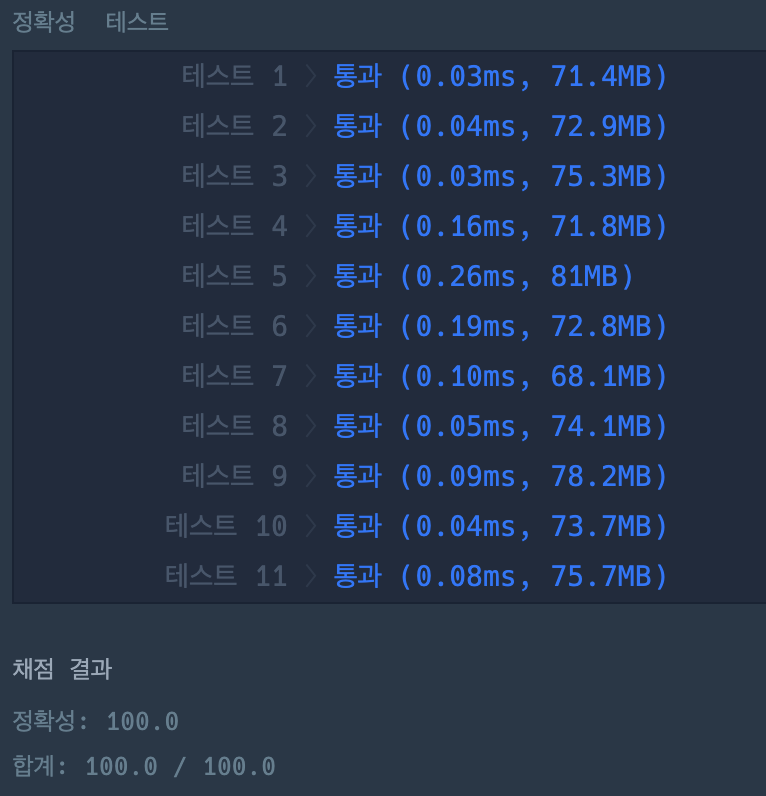
나의 풀이
package 프로그래머스;
import java.util.Arrays;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
public class ScoreRanking {
public static int[] solution(int[][] score) {
Double[] averge = new Double[score.length];
for(int i = 0; i < score.length; i++) {
averge[i] =(double)(score[i][0] + score[i][1]) / 2;
}
Double[] scoreCopy = Arrays.copyOf(averge, averge.length);
Arrays.sort(averge,Comparator.reverseOrder());
Map<Integer,Double > map = new HashMap<>();
for(int i = 0; i < averge.length; i++) {
map.put(i+1, averge[i]);
}
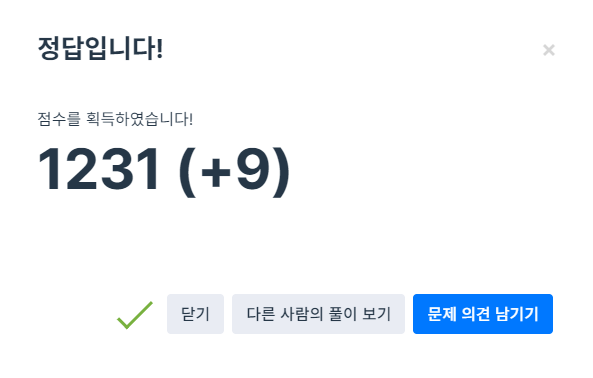
System.out.println(map);
int[] answer = new int[averge.length];
for(int i = 0; i < averge.length; i++) {
if(map.containsValue(scoreCopy[i])) {
for(Map.Entry<Integer, Double> entry : map.entrySet()) {
if(entry.getValue().equals(scoreCopy[i])) {
answer[i] = entry.getKey();
break;
}
}
}
}
return answer;
}
public static void main(String[] args) {
int[][] score = {{1, 2}, {1, 1}, {1, 1}} ;
solution(score);
}
}나의 풀이
먼저, 아래와 같은 형태의 로직을 구성하여 문제를 해결하였다.
- 2차원 배열로 전달받은 매개변수
score의 영어, 수학점수의 평균을 구할 것.Arrays.sort()메서드를 쓰면 작은수 부터 큰 수로오름차순 정렬이기 때문에내림 차순으로 역정렬 할 것- 이를 Map 자료 구조
key = 등수,value = 점수로 할당 할 것- Map의
순서쌍 ( 등수 - 평균 점수)을 기존의 평균점수간 든 배열과 비교하여 같은value값이 있으면 키값을 answer에 저장(키값 = 등수)
순서 1번
Double[] averge = new Double[score.length];
for(int i = 0; i < score.length; i++) {
averge[i] =(double)(score[i][0] + score[i][1]) / 2;
}
순서 2번
Arrays.sort(averge,Comparator.reverseOrder());
순서 3번
Map<Integer,Double > map = new HashMap<>();
for(int i = 0; i < averge.length; i++) {
map.put(i+1, averge[i]);
}
반복은 index = 0 부터 돌기 때문에, index가 아닌, 등수를 의미하기 위해 i+1을 키값으로 할당
순서 4번
순서 4에서 부터는 내가 구성했던 로직대로 구현하면, map의 value값은 비교할 수 있으나, value 값이 일치 했을 경우 그에 해당하는 key값을 뽑아낼 방법이 없음, 그리고 map의 value값과 원래의 배열값과 비교할려고 보니 원래의 배열값이 내림 차순으로 정렬된 값으로 값이 변경됐기때문에, 원래의 배열값을 저장할 새로운 Copy 배열을 추가로 할당
Double[] averge = new Double[score.length];
for(int i = 0; i < score.length; i++) {
averge[i] =(double)(score[i][0] + score[i][1]) / 2;
}
Double[] scoreCopy = Arrays.copyOf(averge, averge.length);
그림에서 알 수 있듯이, 원배열은 내림차순으로 정렬하는 순간 값이 변경됨을 확인할 수 있음, 따라서 기존의 원본 배열을 그대로 복사할 배열이 따로 필요한 이유
int[] answer = new int[averge.length];
for(int i = 0; i < averge.length; i++) {
if(map.containsValue(scoreCopy[i])) {
for(Map.Entry<Integer, Double> entry : map.entrySet()) {
if(entry.getValue().equals(scoreCopy[i])) {
answer[i] = entry.getKey();
break;
}
}
}
}value값을 비교하여 같으면, 해당하는 key값을 뽑아내기 위해서는 Map.Entry인터페이스를 활용해야함,
if(entry.getValue().equals(scoreCopy[i])) {
answer[i] = entry.getKey();
break;
}여기서 entry.getValue()와 비교해야하는 배열은 내림차순으로 정렬된 배열 averge가 아닌, 원 배열을 복사한 scoreCopy가 되어야 기존의 순서대로 등수가 할당
내가 추가로 했던 실수는 처음에 모든 배열의
int기본 자료형 구조를 사용하였는데, 테스트케이스 에러가 발생하여 확인결과, double형 자료형을 사용해야 소수점 계산으로 등수를 더 정확하게 판단할 수 있었다. 위 코드에선 double형 대신Double자료형(Wrapper 클래스)을 사용하였는데,Arrays.sort()메서드는 기본 자료형을 배열로 갖는 경우에는 정렬할 수 있지만, 객체 자료형(Comparator)을 배열로 갖는 경우 정렬을 할 수 없기때문에,Double과 같은Wrapper클래스로 배열의 요소를 객체로 감싸서sort()메서드를 사용하였다.
유한소수 판별하기
📑 문2) 소수점 아래 숫자가 계속되지 않고 유한개인 소수를 유한소수라고 합니다. 분수를 소수로 고칠 때 유한소수로 나타낼 수 있는 분수인지 판별하려고 합니다. 유한소수가 되기 위한 분수의 조건은 다음과 같습니다.
- 기약분수로 나타내었을 때, 분모의 소인수가 2와 5만 존재해야 합니다.
두 정수 a와 b가 매개변수로 주어질 때, a/b가 유한소수이면 1을, 무한소수라면 2를 return하도록 solution 함수를 완성해주세요.
입출력 예
| a | b | result |
|---|---|---|
| 7 | 20 | 1 |
| 11 | 22 | 1 |
| 12 | 21 | 2 |
입출력 예 설명
- 분수 7/20은 기약분수 입니다. 분모 20의 소인수가 2, 5 이기 때문에 유한소수입니다. 따라서 1을 return합니다.
- 분수 11/22는 기약분수로 나타내면 1/2 입니다. 분모 2는 소인수가 2 뿐이기 때문에 유한소수 입니다. 따라서 1을 return합니다.
- 분수 12/21는 기약분수로 나타내면 4/7 입니다. 분모 7은 소인수가 7 이므로 무한소수입니다. 따라서 2를 return합니다.
Hint
- 분자와 분모의 최대공약수로 약분하면 기약분수를 만들 수 있습니다.
- 정수도 유한소수로 분류합니다.
나의 풀이
class Solution {
public int solution(int a, int b) {
int answer = 0;
if (a == 1) return 1;
for(int i = 2; i <= a; i++) {
if (a % i == 0) {
if(a % i == 0 && b % i == 0) {
a /= i;
b /= i;
}
}
}
if (b == 1) {
answer = 1;
} else {
while (b % 2 == 0) {
b /= 2;
}
while (b % 5 == 0) {
b /= 5;
}
if (b == 1) {
answer = 1;
} else {
answer = 2;
}
}
// System.out.println(b);
System.out.println(answer);
return answer;
}
}
나의 생각
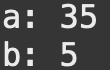
int a = 3500,int b = 500 일 때를 예를들면
for(int i = 2; i <= a; i++) {
if (a % i == 0) {
if(a % i == 0 && b % i == 0) {
a /= i;
b /= i;
}
}
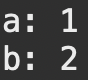
}먼저, 매개변수 a,b를 기약분수로 나타내기 위한 위의 연산 코드를 통해 a, b를 기약분수의 형태로 나타내는데, 분자가 분모보다 클 경우와, 분자가 분모보다 작을 경우로 나누어 생각하여,
| 분자가 분모보다 클 경우 (a=3500, b=500) | 분모가 분자보다 클 경우(a=11, b=22) |
|---|---|
 |  |
와 같이 나타 낼 수 있다.
if (b == 1) {
answer = 1;
} else {
while (b % 2 == 0) {
b /= 2;
}
while (b % 5 == 0) {
b /= 5;
}
if (b == 1) {
answer = 1;
} else {
answer = 2;
}
}b = 1 일 때는, a와 관계 없이, 정수가 되므로 유한 소수가 되고, 만약, b를 2나 5로 나누었을때 나머지가 0인 경우는 b값을 한 번 이상 더 나눌 수 있다는 의미가 된다. 따라서, 최종적으로 b == 1 일때, 유한소수 이며, 그 외의 값은 무한 소수 로 판별할 수 있다. 위 표의 예처럼, b= 5, b = 2일때, 2나 5로 나누면 b값이 1로 떨어지기 때문에 유한 소수를 판별할 수 있게 된다.
다른 풀이
class Solution {
public int solution(int a, int b) {
int answer = 0;
// 소인수분해
for (int i = 2; i <= a; i++) {
if (a % i == 0 && b % i == 0) {
a /= i;
b /= i;
i--;
}
}
// 2와 5 이외의 소수가 있는지 확인
while (b % 2 == 0) b /= 2;
while (b % 5 == 0) b /= 5;
if (b == 1) answer = 1;
else answer = 2;
return answer;
}
}다른 풀이(2)
유클리드 호제법을 이용한 최대공약수 구하기
유클리드 호제법은재귀적인 방법으로 a와 b의 최대공약수를 구하는 알고리즘
package programmers;
public class FiniteDecimal {
public static int solution(int a, int b) {
int answer = 0;
b /= gcd(a,b);
System.out.println("b: " + b);
if (b == 1) {
answer = 1;
} else {
while (b % 2 == 0) {
b /= 2;
}
while (b % 5 == 0) {
b /= 5;
}
if (b == 1) {
answer = 1;
} else {
answer = 2;
}
}
return answer;
}
public static int gcd (int a, int b) {
if(b == 0) {
return a;
}else {
return gcd(b,a%b);
}
}
public static void main(String[] args) {
solution(8 , 12);
}
}
핵심

a = 8, b = 12 일 경우, gcd (12, 8) 이 되고,
a = 12, b = 8 일 경우, gcd( 8, 4)가 되고,
a = 8, b = 4 일 경우, gcd(4, 0) 이 되기때문에,return 4즉, 최대공약수4를 리턴한다.
저주의 숫자 3
📑 문3) 3x 마을 사람들은 3을 저주의 숫자라고 생각하기 때문에 3의 배수와 숫자 3을 사용하지 않습니다. 3x 마을 사람들의 숫자는 다음과 같습니다.
| 10진법 | 3x 마을에서 쓰는 숫자 | 10진법 | 3x 마을에서 쓰는 숫자 |
|---|---|---|---|
| 1 | 1 | 6 | 8 |
| 2 | 2 | 7 | 10 |
| 3 | 4 | 8 | 11 |
| 4 | 5 | 9 | 14 |
| 5 | 7 | 10 | 16 |
정수 n이 매개변수로 주어질 때, n을 3x 마을에서 사용하는 숫자로 바꿔 return하도록 solution 함수를 완성해주세요.
입출력 예
| n | result |
|---|---|
| 15 | 25 |
| 40 | 76 |
입출력 예 설명
-
15를 3x 마을의 숫자로 변환하면 25입니다.
-
40을 3x 마을의 숫자로 변환하면 76입니다.
나의 풀이
class Solution {
public int solution(int n) {
int answer = 0;
int[] cn = new int[n];
cn[0] = 1;
for(int i = 1; i < n; i++) {
cn[i] = cn[i-1] + 1;
if(cn[i] % 3 == 0) {
cn[i] = cn[i-1] + 2;
}
if(String.valueOf(cn[i]).contains("3")) {
cn[i] = cn[i-1] + 3;
}
if((cn[i] / 10) % 10 == 3) {
cn[i] = cn[i-1] + 11;
if(String.valueOf(cn[i]).contains("3")) {
cn[i] += 1;
}
}
}
answer = cn[n-1];
return answer;
}
}
나의 생각
이번 문제를 풀면서 느꼈던 점은 억지로 끼워맞추어 문제를 풀었다는 느낌이 강하게 들었다. 그 이유를 하나씩 파악해보자. 3의 배수와 3이라는 숫자가 들어가면 그 숫자를 건너 뛰어 숫자를 판별하는 방법을 추론하는 문제이다. 나는 이 문제를 배열로 생각하여 문제를 풀었는데 나의 의식의 흐름대로 풀이를 설명해보겠다. 주어진 조건대로 문제를 풀기위해 먼저, 배열에 값이 +1씩 증가하여 들어가는지 확인을 먼저하였다.
- n=20일때, 선언된 배열안에 내가 원하는대로(+1씩 증가) 값이 들어가는가?
int[] cn = new int[n];
cn[0] = 1;
for(int i = 1; i < n; i++) {
cn[i]= cn[i-1] + 1;
}
내가 생각했던 로직에서는 현재의 배열값은 현재의 배열 직전의 값이 꼭 필요하기때문에 위와 같은 로직을 구성하였다.
3, 6, 9, 12, 15, 18, 13☛ 3을 만나게 되면+1을 한 4, 5, 7, 8, 10 ... 이렇게 나와야한다.(3의 배수를 필터)
for(int i = 1; i < n; i++) {
cn[i]= cn[i-1] + 1;
if(cn[i] % 3 ==0) {
cn[i] = cn[i-1] + 2;
}
}
13,23과 같이 3의 배수는 아니면서 수에 3이 포함된 값을 어떻게 검출할 것인가??
위와 같은 경우에는, 숫자3을 문자로 보고 , 문자3을 검출하는 방법을 사용한다.
String.valueOf(cn[i]).contains("3") 배열cn[i]를 String.valueOf() 메서드에 넣어 문자로 변환 뒤, 3이라는 문자가 포함되는가? 를 판별하는 것이다. 위와 같은 경우에는 3이 포함되는가? 에 대한 답을 trueorfalse로 답한다.
for(int i = 1; i < n; i++) {
cn[i]= cn[i-1] + 1;
if(cn[i] % 3 ==0) {
cn[i] = cn[i-1] + 2;
}
if(String.valueOf(cn[i]).contains("3")) {
cn[i] = cn[i-1] + 3;
}
}
32,35역시, 3을 포함하기 때문에 if조건에 걸리는것이 아닌가 하겠지만, 이미 cn[i-1] + 3의 결과값이 cn[i]로 들어가기때문에 한번 더 조건을 걸어줘야한다.
나의 경우, 일일이 어떤 값이 나오는가를 확인하면서 32이전의 값 29에서 30대를 지나 40이 되기위해 어떤 조건이 필요한가를 설정하였다. 여러 방법이 있겠지만, 30이상 40미만의 값을 검출하기 위해 풀었던 조건은 다음과 같다.
for(int i = 1; i < n; i++) {
cn[i] = cn[i-1] + 1;
if(cn[i] % 3 == 0) {
cn[i] = cn[i-1] + 2;
}
if(String.valueOf(cn[i]).contains("3")) {
cn[i] = cn[i-1] + 3;
}
if((cn[i] / 10) % 10 == 3) {
cn[i] = cn[i-1] + 11;
}
30~39까지는, 나누기 10의 몫을 다시 %10 한 나머지가 3일 경우로 판별이 가능하며, 30번대를 진입하기전 마지막 값 29에서 11을 더해줘야 40이 되기때문에 위와 같은 식을 구성하였다. 이렇게 하여 채점을 해봤지만 반례가 있는것을 확인....
- n = 100 (넣을 수 있는 값의 최대) 을 넣을 경우 세자리 수로 넘어가면서 if문으로 검출 안되는 경우가 발생한다...

이러한 경우, 문자로 3을 검출 했던 로직을 한번 더 실행하여 검출
for(int i = 1; i < n; i++) {
cn[i] = cn[i-1] + 1;
if(cn[i] % 3 == 0) {
cn[i] = cn[i-1] + 2;
}
if(String.valueOf(cn[i]).contains("3")) {
cn[i] = cn[i-1] + 3;
}
if((cn[i] / 10) % 10 == 3) {
cn[i] = cn[i-1] + 11;
if(String.valueOf(cn[i]).contains("3")) {
cn[i] += 1;
}
}
즉, 128에서 139로 넘어갈때, 3이 있으면 +1하여 140으로 넘어감
진짜 나의 생각
일명...노가다?로 문제를 해결하였지만, 이는 100점자리 해결법은 절대 아니라는 생각 (오히려 이건 정답이 아니다.라는 생각)이 들었다. 정답을 향해 억제로 끼어맞춘 느낌이랄까...? 정답만 맞으면 되지? 라는 생각도 할 순 있지만, 개발자를 꿈꾸면서 문제를 이렇게도 풀 수있구나 정도로 넘어가면 좋을꺼같다.
좀 더 클린한 코드
class Solution {
public int solution(int n) {
int answer = 0;
for (int i = 0; i < n; i++) {
answer++;
while (answer % 3 == 0 || String.valueOf(answer).contains("3")) {
answer++;
}
}
return answer;
}
}개발자라고 하면 단순히 코드만 작성하는 줄 알지만, 경우에 따라 어떤 자료형을 사용할 것인지, 불필요한 작업은 없는지 판단하는것 또한 매우 중요하다고 생각한다. 내가 작성했던 코드와 위 코드를 비교 하였을때 나는 얼마나 불필요한 작업을 하였는가? 에 대한 의문이 들었다. 불필요한 코드 사용, 메모리 사용 등으로 발생하는 문제를 개발자라고 하면 이 또한 고민해야한다는 것을 명심하자.
while문으로 조건이 만족할 때 까지 무한 반복하는데, while문 안의 조건은 3의 배수이거나, 3이라는 문자가 있을때까지 반복 수행한다. 0부터 매개변수로 주어지는 n까지 for문을 돌려, answer을 카운팅하는데, 3의 배수 또는 문자3이 검출될때에는 한번더 카운팅 되는 방식을 사용
특이한 정렬
📑 문4) 정수 n을 기준으로 n과 가까운 수부터 정렬하려고 합니다. 이때 n으로부터의 거리가 같다면 더 큰 수를 앞에 오도록 배치합니다. 정수가 담긴 배열 numlist와 정수 n이 주어질 때 numlist의 원소를 n으로부터 가까운 순서대로 정렬한 배열을 return하도록 solution 함수를 완성해주세요.
제한사항
- 1 ≤ n ≤ 10,000
- 1 ≤ numlist의 원소 ≤ 10,000
- 1 ≤ numlist의 길이 ≤ 100
- numlist는 중복된 원소를 갖지 않습니다.
입출력 예
| numlist | n | result |
|---|---|---|
| [1, 2, 3, 4, 5, 6] | 4 | [4, 5, 3, 6, 2, 1] |
| [10000,20,36,47,40,6,10,7000] | 30 | [36, 40, 20, 47, 10, 6, 7000, 10000] |
입출력 예 설명
입출력 예 #1
- 4에서 가까운 순으로 [4, 5, 3, 6, 2, 1]을 return합니다.
- 3과 5는 거리가 같으므로 더 큰 5가 앞에 와야 합니다.
- 2와 6은 거리가 같으므로 더 큰 6이 앞에 와야 합니다.
입출력 예 #2
- 30에서 가까운 순으로 [36, 40, 20, 47, 10, 6, 7000, 10000]을 return합니다.
- 20과 40은 거리가 같으므로 더 큰 40이 앞에 와야 합니다.
나의 풀이
잘못 설계된 나의 풀이
package 프로그래머스;
import java.util.Arrays;
import java.util.LinkedHashMap;
import java.util.Map;
public class UnusualArray {
public static int[] solution(int[] numlist, int n) {
int[] answer = new int[numlist.length];
Map<Integer, Integer> map = new LinkedHashMap<>();
for(int i = 0; i < numlist.length; i++) {
answer[i] = Math.abs(numlist[i] - n);
map.put(numlist[i],answer[i]);
}
Arrays.sort(answer);
System.out.println(Arrays.toString(answer));
System.out.println(map);
int[] newArray = new int[numlist.length];
for (int i = 0; i < answer.length; i++) {
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
if (answer[i] == entry.getValue()) {
newArray[i] = entry.getKey();
map.remove(entry.getKey());
break;
}
}
}
System.out.println(Arrays.toString(newArray));
return answer;
}
public static void main(String[] args) {
int[] numlist = {10000,20,36,47,40,6,10,7000};
solution(numlist,30);
}
}
문제에서 원하는 답은 [36, 40, 20, 47, 10, 6, 7000, 10000]이다. 의식의 흐름대로 매개변수로 주어지는 n의 값과 배열의 값의 차의 절대값을 이용하여 문제를 풀면 되겠다는 생각을 먼저하게됐다.
|36-30| = 6
|20-30| = 10
|40-30| = 10
|47-30| = 17
|10-30| = 20
|6-30| = 24
|7000-30 | = 6970
|10000-30| = 9970

int[] numlist = {10000,20,36,47,40,6,10,7000};
Map 자료형 구조를 사용해서 원본의 값을 key , 절대값을 이용하여 계산된 길이의 값을 value로 하여 map변수에 저장하였다.
for (int i = 0; i < answer.length; i++) {
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
if (answer[i] == entry.getValue()) {
newArray[i] = entry.getKey();
map.remove(entry.getKey());
break;
}
}
}오름차순으로 정렬된 answer[i]와 entry.getValue()를 비교하여 같으면 새로운 배열 newArray[i]에 저장하고, 해당하는 키를 map에서 제거하여 중복을 피하는 방법을 사용하였다. 만약, map.remove를 하지않는다면 아래와 같은 결과가 출력된다.
[36, 20, 20, 47, 10, 6, 7000, 10000]
그 이유는 map자료형 구조에서 값이 같은 value가 존재하더라도, 반복을 통해 같은 값이 있으면 중복제거가 되지않고 다시 한번 검출 되기때문이다.
map.remove() 메서드를 포함 시켜 계산하면 아래와 같은 결과가 나오는데,

이 부분에서 20과,40을 나누는 기준을 생각하기위해 이틀동안 머리를 쥐어짰다... 하루에 알고리즘 1문제 씩 푸는 숙제를 다음날로 미룬(?) 역사적인 날이다...
수정된 코드
package programmers;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
public class UnusualArray {
public static int[] solution(int[] numlist, int n) {
int[] answer = new int[numlist.length];
Map<Integer, Integer> map = new LinkedHashMap<>();
for(int i = 0; i < numlist.length; i++) {
answer[i] = Math.abs(numlist[i] - n);
map.put(numlist[i],answer[i]);
}
Arrays.sort(answer);
System.out.println(Arrays.toString(answer));
System.out.println(map);
int[] newArray = new int[numlist.length];
int index = 0;
for (int i = 0; i < answer.length; i++) {
List<Integer> sameValueKeys = new ArrayList<>();
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
if (entry.getValue() == answer[i]) {
sameValueKeys.add(entry.getKey());
}
}
if(!sameValueKeys.isEmpty()) {
Collections.sort(sameValueKeys,Collections.reverseOrder());
for(Integer key : sameValueKeys) {
newArray[index++] = key;
map.remove(key);
}
}
}
System.out.println(Arrays.toString(newArray));
return newArray;
}
public static void main(String[] args) {
int[] numlist = {10000,20,36,47,40,6,10,7000};
solution(numlist,30);
}
}나의 생각
내가 짠 코드에 불필요한 부분이 없는지, 더 간소화 시킬 수 있는 부분이 없는지 생각할 여력이 없을 정도로 머리가 아픈 문제였다... 중복값이 없어도 나에겐 충분히 어려운 문제인데 같은 값이 존재할 경우, 매개변수 n과 가까운 수가 앞으로 오게 하는 로직을 생각하기가 너무 까다로웠다. 이 부분 덕분에, 여러 사람들이 푼 방법을 몇 개 찾아보긴 했지만, 웬만하면 내가 구성한 로직으로 풀 수 있다 라는 오기가 생겨 끝까지 도전했다. 문제의 열쇠는 정렬을 한 번 더 하는건데, 오름차순이 아닌 내림차순으로 정렬하는 것이다!
핵심 부분만 짚고 넘어가자면,
int index = 0;
for (int i = 0; i < answer.length; i++) {
List<Integer> sameValueKeys = new ArrayList<>();
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
if (entry.getValue() == answer[i]) {
sameValueKeys.add(entry.getKey());
}
}
if(!sameValueKeys.isEmpty()) {
Collections.sort(sameValueKeys,Collections.reverseOrder());
for(Integer key : sameValueKeys) {
newArray[index++] = key;
map.remove(key);
}
}
}
- 같은 차이값을 가진 숫자들의 키를 저장할
sameValueKeys리스트를 생성- 맵의 각 엔트리를 순회하면서, 해당 엔트리의 값이 현재 차이값과 같은 경우, 해당 키를
sameValueKeys에 추가sameValueKeys리스트에 저장된 키들이 같은 차이값을 가진 숫자들임, 이제 내림차순으로 정렬함
Collections.sort(sameValueKeys, Collections.reverseOrder());- 정렬된
sameValueKeys리스트를 순회하면서,newArray에 원소를 추가하고, 해당 키를 맵에서 제거. 이때, 키 값이 큰 숫자부터newArray에 추가됨
List 자료 구조를 쓴 이유가 무엇일까?
순서보장: 리스트는 원소들의 순서를 유지. 이 경우, 같은 차이값을 가진 키를 찾을 때 순서가 유지되므로, 이후에 정렬할 때 원래 순서에 영향을 받지 않음중복허용: 리스트는 중복된 원소를 허용함. 이 문제에서는 중복이 발생할 가능성이 낮지만, 혹시 같은 차이값을 가지는 중복된 키가 있을 경우 리스트에 저장할 수 있음(핵심)정렬용이성: 리스트는Collections클래스를 사용하여 쉽게 정렬할 수 있음. 이 경우Collections.sort()와Collections.reverseOrder()를 사용하여 내림차순 정렬을 적용할 수 있음
문자열 밀기
📑 문5) 문자열 "hello"에서 각 문자를 오른쪽으로 한 칸씩 밀고 마지막 문자는 맨 앞으로 이동시키면 "ohell"이 됩니다. 이것을 문자열을 민다고 정의한다면 문자열 A와 B가 매개변수로 주어질 때, A를 밀어서 B가 될 수 있다면 밀어야 하는 최소 횟수를 return하고 밀어서 B가 될 수 없으면 -1을 return 하도록 solution 함수를 완성해보세요.
입출력 예
| A | B | result |
|---|---|---|
| "hello" | "ohell" | 1 |
| "apple" | "elppa" | -1 |
| "atat" | "tata" | 1 |
| "abc" | "abc" | 0 |
입출력 예 설명
- "hello"를 오른쪽으로 한 칸 밀면 "ohell"
- "apple"를 몇 번을 밀어도 "elppa"가 될 수 없음
- "atat"는 오른쪽으로 한칸, 왼쪽으로 세 칸을 밀면 "tata"가 되므로 최소 횟수인 1을 반환
- "abc"는 밀지 않아도 "abc" 이므로 0을 반환
나의 풀이
class Solution {
public int solution(String A, String B) {
int answer = -1;
String[] strArray = new String[A.length()];
int length = A.length();
if(A.equals(B)) {
return 0;
}else {
A +=A;
for(int i = 0; i < length; i++ ) {
strArray[i] = A.substring(i,i+length);
if(strArray[i].equals(B)) {
answer = Math.abs(i-length);
}
}
}
return answer;
}
}나의 생각
처음에는 매개변수 String A를 배열에 담아 문제에서 요구하는 방법으로 반복을 돌리려고 했는데, 곰곰히 생각해보니 굳이 배열로 담아 인덱스를 반복시킬 필요가 없겠다라는 생각이 들었다.
처음 If문은 매개변수로 주어지는 String A와, StringB가 같으면 문자를 밀 필요가 없기 때문에 return 0을 반환한다. 그 외, -1또는 1만 체크 하면 되기 때문에, 문자열 A에 A를 한번더 더해준다. 내가 설계한 방법은 만약, hello 문자열이 있다면 한번 더 나열하여 hellohello가 되게 한다. String 클래스의 subString메서드를 사용하면, 시작 index와 끝 index를 이용하여 문자열을 자를 수 있는데, 반복문을 통해 내가 원하는 문자열을 자를수 있게 된다. 자른 문자열은 다음과 같다.
hellohello
[0] :hello
[1] :elloh
[2] :llohe
[3] :lohel
[4] :ohell
하지만, 내가 잘못 생각한 부분이 있었으니....
문제에선 각 글자를 오른쪽으로 밀고, 마지막문자는 맨앞으로 보낸다 즉, 문제에서 원하는 순서는 다음과 같다
[0] :
hello
[1] :ohell
[2] :lohel
[3] :llohe
[4] :elloh
내가 구성한 로직과, 문제가 원하는 로직이 다르다는 것을 알 수 있다. 그러므로, 추가로 로직을 추가해줬는데, 추가로 구성한 로직은 다음과 같다.
if(strArray[i].equals(B)) {
answer = Math.abs(i-length);
}문제에서 주어진 매개변수 String B = ohell이, 내가 구성한 로직에서의 순서는 4번째 index에 존재하며, 문제에서 원하는 조건대로 푼 로직에선 1번째 index에 존재하기 때문에 최소 이동수 는 1이된다. 그렇다면 내가 구성한 로직에서 최소값1을 리턴하려면 어떤 조건을 추가해줘야할 것인가??
내가 구성한 로직에서 ohell 의 index는
4이기 때문에,Math.abs(i-length)를 풀면,4-(length : 5)= 1이 된다.
