
유저 검색 기능의 변경
현재 사이드 프로젝트 Grimity의 검색 요구사항이 복잡해서 AWS OpenSearch를 사용하고 있는데.. (프리티어가 가능해서)
OpenSearch를 사용해본 사람은 알 것이다. 프리티어 사양으로 노드를 띄우기만 해도 메모리의 60 ~ 80퍼센트를 왔다갔다하며 사용하고 있다.
실제 데이터가 좀 많아지다보니 OpenSearch 서버가 터지는 일이 점점 잦아져 결국 유저 검색의 기능을 줄이고 메인 데이터베이스인 PostgreSQL에서만 하기로 결정했다. (그림이나 게시글 검색은 그대로 OpenSearch 사용, 어차피 추후 MeiliSearch로 마이그레이션 할 예정이라)
현재 유저 검색 요구사항
- 닉네임 필드는 like '%abc%' 와일드카드 연산
- bio 필드는 한글 형태소 분석
- 위 두가지 필드 동시 검색 + 닉네임 필드에 가중치를 더 크게 줘서 정확도순 정렬 지원
타협된 유저 검색 요구사항
- 닉네임 필드만 like 'abc%' 접두사 패턴 매칭 연산
기본 Unique 인덱스의 예상치 못한 동작
애초에 우리 서비스는 name 필드에 unique index가 설정되어 있었고 unique index는 B-tree 기반으로 저장된다.
따라서 별다른 조치없이도 like 'abc%' 와 같은 앞에서부터 매치시키는 와일드카드 연산은 인덱스를 탈 것이라고 예상했고 실제 데이터베이스에서 테스트해봤다.
1. 동등(=) 연산
explain analyze select * from "User" where name = 'test';
= 연산은 당연히 unique index를 타고 있고
2. 접두사 패턴 매칭('abc%') 연산
explain analyze select * from "User" where name like 'abc%';
패턴 매칭 연산은 인덱스를 탈 거란 내 예상과 달리 풀테이블 스캔을 하고 있었다.
우리 서비스에 유저 데이터가 280건 밖에 없어서 옵티마이저가 Seq Scan을 선택한 걸수도 있겠다 싶어 이참에 제대로 성능테스트를 해보며 어떤 인덱스를 사용할 지 결정하기로 했다.
성능 테스트
테스트 환경
- MacBook M2 Pro (메모리 16GB)
- Docker로 로컬에 띄운 PostgreSQL 16.8
- User 데이터 100만건
1. 기본 Unique 인덱스
우선 가장 기본인 Unique Index 부터 테스트해보자.
-- CreateTable
CREATE TABLE "User" (
"id" UUID NOT NULL,
"name" TEXT NOT NULL,
CONSTRAINT "User_pkey" PRIMARY KEY ("id")
);
-- CreateIndex
CREATE UNIQUE INDEX "User_name_key" ON "User"("name");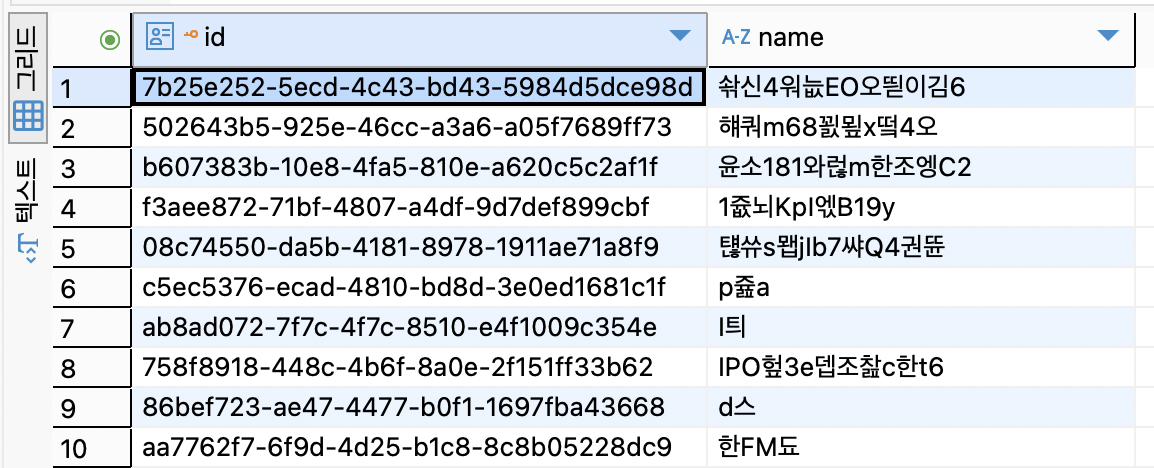
대충 이런 유저데이터 100만건을 넣었고 인덱스 크기는 42M 이다.
= 연산
explain analyze select * from "User" where name = '동물원';
이건 마찬가지로 인덱스를 잘 타고있고
LIKE 연산
explain analyze select * from "User" where name like '동물원%';
이번에도 풀 테이블 스캔을 하고 있다.
이유를 찾아보니 PostgreSQL에서 B-tree 인덱스를 통해 접두사 패턴 매칭 쿼리를 최적화하고 싶다면 컬럼의 로케일이 C 로케일 이거나 연산자 클래스가 text_pattern_ops 여야 한다.
AWS RDS PostgreSQL의 기본 로케일은 다음과 같다.
SELECT datcollate, datctype
FROM pg_database
WHERE datname = current_database();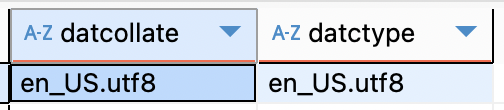
기본 unique 인덱스가 무용지물인 이유가 C 로케일이 아니었기 때문이었다.
en_US.utf8 과 같은 언어별 로케일은 각 언어별로 복잡한 문자열 비교 규칙을 사용하고 있어 B-tree 인덱스로는 패턴 매칭을 효율적으로 할 수 없지만 C 로케일 은 문자열을 비교할 때 단순한 바이트 비교만 수행하기 때문에 B-tree 인덱스로 저장하더라도 like 'abc%' 와 같은 패턴 매칭을 효율적으로 수행할 수 있다.
2. C 로케일을 적용한 Unique 인덱스
-- CreateTable
CREATE TABLE "User" (
"id" UUID NOT NULL,
"name" TEXT COLLATE "C" NOT NULL,
CONSTRAINT "User_pkey" PRIMARY KEY ("id")
);
-- CreateIndex
CREATE UNIQUE INDEX "User_name_key" ON "User"("name");여기서 주의할 점은 컬럼 타입에 C 로케일을 적용하는 방법과 컬럼 타입은 그대로두고 Index에 C 로케일을 적용하는 방법이 있다.
위 예제는 컬럼 타입에 C 로케일을 적용한 방법이지만 만약 후자의 방법을 선택한다면 매 쿼리마다 COLLATE "C"를 직접 명시해줘야하는 번거로움이 있다.
인덱스 크기는 43M로 기존 en_US.utf8과 동일한 수준
= 연산
explain analyze select * from "User" where name = '동물원';
LIKE 연산
explain analyze select * from "User" where name like '동물원%';
성공이다. 컬럼의 타입을 C 로케일로 설정하면 Unique 인덱스 하나만 두고, 기존 쿼리의 수정없이 성능 최적화가 가능하다.
3. text_pattern_ops 인덱스
인덱스를 설정할 때 연산자 클래스를 지정할 수 있다.
기본값은 text_ops 이며 컬럼에 지정된 로케일로 문자비교를 수행하지만 text_pattern_ops를 지정하게 된다면 C 로케일을 설정한 것처럼 바이트 비교를 수행하기 때문에 B-tree 인덱스를 사용하더라도 접두사 패턴매칭을 효율적으로 할 수 있다.
-- CreateTable
CREATE TABLE "User" (
"id" UUID NOT NULL,
"name" TEXT NOT NULL,
CONSTRAINT "User_pkey" PRIMARY KEY ("id")
);
-- CreateIndex
CREATE UNIQUE INDEX "User_name_key" ON "User"("name" text_pattern_ops);인덱스 크기는 43M 로 이전 인덱스들과 동일
= 연산

LIKE 연산

결론
PostgreSQL에서 기본 Unique 인덱스(B-tree)로는 접두사 패턴 매칭 (LIKE 'abc%')을 효율적으로 수행할 수 없다.
이를 해결하기 위해 컬럼의 로케일을 C 로케일 로 설정하거나 연산자 클래스를 text_pattern_ops 로 설정해야하며 둘 사이에 성능차이는 미미하고 인덱스 크기 또한 별 차이 없어 인덱스만 수정하면 끝나는 text_pattern_ops 를 서비스에 도입했다.
DROP INDEX "User_name_key";
CREATE UNIQUE INDEX "User_name_key" ON "User"("name" text_pattern_ops);적용 후 LIKE 연산 결과
explain analyze select * from "User" where name like 'abc%';
풀 테이블 스캔중이던 쿼리를 기존 Unique 인덱스를 살짝 수정하는 것만으로 최적화에 성공했다 😎
번외
지금은 접두사 패턴 매칭이지만 만약 '%abc%' 와 같은 쿼리를 수행해야 한다면 GIN + pg_trgm 같은 인덱스를 설정해야 할 것이다.
앞선 인덱스들은 크기가 43M 으로 일정했지만 GIN 인덱스는 크기가 어느 정도될지 궁금해서 해봤는데..
CREATE EXTENSION IF NOT EXISTS pg_trgm;
-- CreateTable
CREATE TABLE "User" (
"id" UUID NOT NULL,
"name" TEXT NOT NULL,
CONSTRAINT "User_pkey" PRIMARY KEY ("id")
);
-- CreateIndex
CREATE INDEX "idx_user_name" ON "User" USING GIN ("name" gin_trgm_ops);
SELECT
pg_size_pretty(pg_relation_size('public."User"')) AS table_size,
pg_size_pretty(pg_indexes_size('public."User"')) AS indexes_size;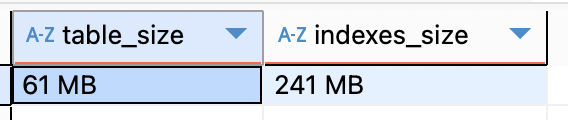
워 차이가 크긴하네..
