🤑 이번 글은 기업 제출용 프로젝트 설명 글 입니다.
- 강화학습의 A3C 알고리즘과 입력 데이터에 맞게 설계한 LSTMDNN network를 활용하여 강화학습 선물 자동매매 봇을 만든 프로젝트 입니다.
- 현재 저는 AI/Data Scientist 분야로 취업을 준비하고 있고 이 글은 기업에 제출할 포트폴리오를 작성한 글 입니다.
- 프로젝트의 코드는 jongwon code Github에 있습니다. 감사합니다.
📕프로젝트 정보
- 😀 프로젝트 구성원 : 이종원(개인프로젝트)
- 📆 프로젝트 기간 : 2022.12.15 ~ 2023.01.08
- 💻 사용 모델 : 강화학습 알고리즘(A3C), 신경망 모델(LSTM-DNN custom model)
- 🤖 주요 사용 기술 : python, tensorflow, keras, multi-processing
📕목차
- 1. 프로젝트 정보
- 2. 목차
- 3. A3C 알고리즘 설명
- 4. LSTMDNN Agent vs DNN Agent
- 5. Data Preprocessing
- 6. Environment
- 7. Learner
- 8. 훈련 및 테스트 결과 확인
- 9. cmd 입력
- 10. 고찰
📕A3C(Asynchronous Advantage Actor-Critic)
📘A3C(Asynchronous Advantage Actor-Critic) 알고리즘
-
Multi A2C(Advantage Actor Critic) Agent를 Asynchronous한 방식으로 훈련하는 알고리즘.
-
AC(Actor Critic)
-
Actor Network와 Critic Network로 이루어진 강화학습 알고리즘
- Actor Network : 최적의 action을 선택하는 것에 목적성을 둔 Network
- Critic Network : 함수를 정확히 평가하는 것에 목적성을 둔 Network.
-
Policy Iteration 방식의 강화학습 알고리즘
- Actor Network 로 최적의 action을 선택할 수 있게 모델을 업데이트 하고 (정책 발전),
- Critic Network 를 통해 를 정확히 추정하도록 모델을 업데이트 하여 policy의 신뢰도를 확보하는 알고리즘. (정책 평가)
-
AC의 목적함수
- = 출력의 의 출력
-
AC의 정책신경망(Actor Network) 파라미터 업데이트 수식
-
-
A2C(Advantage Actor Critic)
-
AC의 가중치 업데이트 공식이 함수 에 따라 변동이 심해 의 개념을 도입하여 학습의 안전성을 확보.
-
Baseline으로 Value function의 도입
- 가치 함수 는 상태 마다 다르지만, 행동마다 다르지 않기 때문에 효율적으로 큐 함수 의 분산을 효율적으로 줄일 수 있음.
- 가치 함수 는 상태 마다 다르지만, 행동마다 다르지 않기 때문에 효율적으로 큐 함수 의 분산을 효율적으로 줄일 수 있음.
-
Advantage의 정의
-
TD error
- 에서 함수와 함수를 각각 근사하려면 비효율적임. 의 개념을 적용하여 함수를 와 로 변환
-
- On-policy 방식 알고리즘
- 주어진 에 대해 을 결정하는 가 존재하는 알고리즘.
- 의 부분을 개선.
-
Global Network & Replay Memory
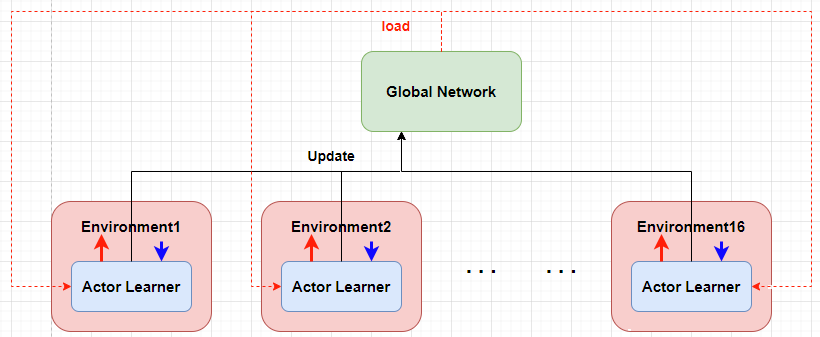
- 각 Actor Learner는 각기 다른 환경에서 학습을 진행하기 때문에 학습 샘플들의 연관성을 낮을 수 있는 장점이 있음.
- 의 의 아이디어를 활용하였고, 현재 기반의 의사결정에 의한 데이터를 저장할 수 있음.
- 각 는 일정 횟수를 탐색 하고 탐색 데이터를 활용하여 를 업데이트 한뒤 자신을 로 업데이트 함.
📕LSTMDNN Agent vs DNN Agent
📘입력 데이터의 특징
-
학습에 사용되는 주식 데이터에는 데이터의 부족, 시계열성, Agent의 action에 독립성/의존성라는 특성이 있습니다. 다음의 특성에 대해서 살펴보겠습니다.
-
데이터의 부족
- 학습에 사용한 일봉 데이터는 일년에 260개 정도 생성되는 만큼 데이터가 매우 부족합니다. 따라서, 존재하는 데이터 내에서 중요한 정보를 담은 feature들을 최대한 많이 추출해야 했습니다.
- 다양한 기술적 분석 지표(Bollinger Band, 일목 균형표, 지수 이평선)와 캔들의 비율의 특성들을 feature로 추출하였습니다.
-
시계열 데이터
- 주식 가격 데이터는 대표적인 시계열 데이터 입니다. 따라서, FNN(Feed Forward Network)보단 시계열 정보를 잘 학습할 수 있는 LSTM Network를 사용하였습니다.
- 또한, LSTMDNN Network의 경우 10일의 데이터를 학습할 수 있도록 추가 전처리 하였습니다.
-
Agent의 action에 대한 독립성/의존성의 공존
- Agent가 Environment로 부터 받는 State는 주식가격 정보(chart state)와 계좌잔고 정보(balance state)입니다.
- Agent의 action(매수, 매도, 관망)이 호가에 일부 영향을 미칠 순 있으나 종가 형성에 영향을 미치지는 않을 것이라고 가정했습니다. 즉, 주식가격은 Agent의 action에 독립적 데이터 입니다. 하지만, 계좌 정보는 Agent의 action에 따라서 변하는 의존적인 데이터 입니다.
- 따라서, 독립적인 입력 데이터와 의존적인 입력 데이터를 각각 LSTM Network와 DNN Network로 분리하여 학습하고 Concatenate하는 구조를 설계하였습니다.
📘Agent Network Structure
📒LSTMDNN Agent
- 설계한 LSTMDNN Network와 비교를 위한 기본 모델인 DNN Network는 아래와 같습니다.
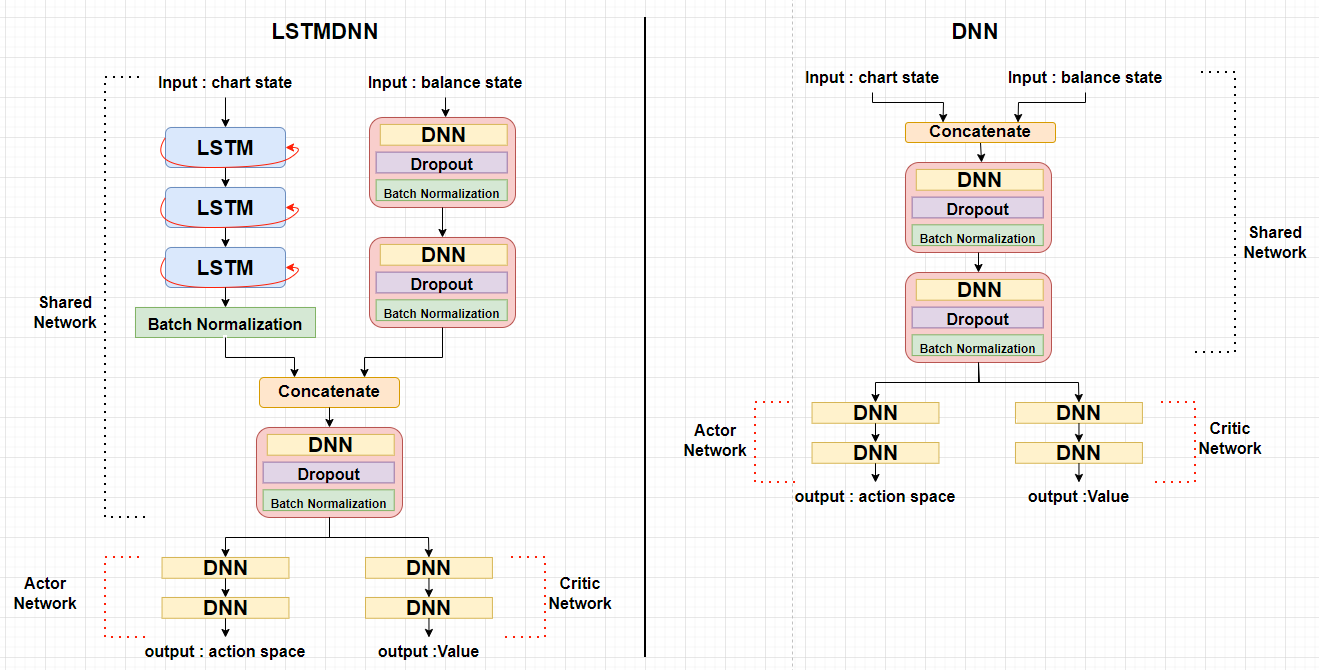
-
Shared Nework Part
-
Actor와 Critic Network는 Network 상부를 공유하며 입력 데이터를 각각 LSTM, DNN Network로 훈련하여 결합합니다.
-
LSTM Part
- LSTM Network에 입력값은 ex) 입니다.
- Chart 정보는 '시계열성', 'action에 독립성'이라는 특징을 가지고 있기 순환신경망 구조의 LSTM Network를 통해 학습시켰습니다.
- LSTM network의 activation function은 일반적으로 사용하는 를, 은 를 적용하여 일반화 효과를 적용하였습니다.
- 3개의 LSTM 구조를 통해 출력된 결과를 Batch Normalization을 통해 정규화 했습니다.
- Batch Normalization은 balance state를 DNN network로 학습하고 출력한 결과와 크기를 어느정도 일치시키기 위해 사용했습니다.
-
DNN Part
- DNN Network의 입력값은 (포지션 자금 비율, 손익, 현재 포지션, 평균 수익률) 입니다.
- Balance 정보는 'action에 종속적'이라는 특징을 가지고 있어서 Chart 정보와 분리하여 학습하였고 DNN Network를 사용했습니다.
- DNN Network와 Dropout, BatchNormalization을 추가하여 정규화와 일반화를 적용하였 습니다.
-
Concatenate Part
- LSTM Network에 의해 출력된 결과와 DNN Network에 의해 출력된 결과를 결합합니다.
- 결합된 데이터를 을 통과시켜 Actor Part와 Critic Part에 입력값으로 전달합니다.
-
-
Actor Part
- Shared Network에서 출력된 결과를 입력하여 action space를 출력하는 Actor part입니다.
- Actor은 (매수 확률, 관망 확률, 매도 확률)을 출력합니다.
- Critic Part
- Shared Network에서 출력된 결과를 입력하여 Value를 출력하는 Critic part입니다.
- Critic은 value(scalar)를 출력합니다.
📒DNN Agent
- DNN 모델은 LSTMDNN 모델과 비교를 위해 생성한 기본 모델입니다.
- 입력 데이터들을 분리하지 않고 결합해서 학습하였고 shared part, Actor part, Critic part 모두 DNN Network로 학습하였습니다.
📕Data Preprocessing
📘DNN Agent preprocessing
- 주식 데이터의 open, high, low, close, vloume feature에서 Bollinger Band, 일목 균형표, 지수 이평선의 기술적 지표와 캔들 차트의 내부적 비율 데이터를 계산하여 24개의 새로운 feature를 추출하였습니다.
- 주가와 거래량의 데이터 크기 차이를 맞추기 위해 비율의 개념으로 feature를 변형하였습니다.
- 아래는 24개의 feature와 설명입니다.
| close_ema15_ratio | : n일 지수 이동평균선 | |
| volume_ema15_ratio | ||
| close_ema33_ratio | ||
| volume_ema33_ratio | ||
| close_ema56_ratio | ||
| volume_ema56_ratio | ||
| close_ema112_ratio | ||
| volume_ema112_ratio | ||
| open_lastclose_ratio | ||
| close_lastclose_ratio | ||
| volume_lastvolume_ratio | ||
| high_close_ratio | ||
| close_low_ratio | : n일 최대값 | |
| max9_close_ratio | ||
| max26_close_ratio | ||
| max52_close_ratio | ||
| close_min9_ratio | : n일 최소값 | |
| close_min26_ratio | ||
| close_min52_ratio | ||
| close_fspan1_ratio | : 선행스팬 1 | |
| close_fspan2_ratio | : 선행스팬 2 | |
| bbupper_close_ratio | : Bollinger Band 상단 | |
| close_bblower_ratio | : Bollinger Band 하단 | |
| std20_mean20_ratio | : 20일 표준편차*0.945 |
📘LSTMDNN Agent preprocessing
-
LSTMDNN Agent에서는 LSTM 네트워크 학습을 위해 추가적인 전처리과정을 거칩니다.
-
t 시점의 입력 데이터는 t-9, t-8, t-7, t-6 ..., t-1, t 이렇게 총 10개의 데이터를 묶어서 LSTM network의 입력값으로 생성합니다.
-
t 시점의 입력 데이터
| timestep | featur1 | featur2 | featur3 | -- | -- | featur24 |
|---|---|---|---|---|---|---|
| t-9 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t-8 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t-7 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t-6 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t-5 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t-4 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t-3 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t-2 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t-1 | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
| t | close_ema15_ratio | volume_ema15_ratio | close_ema33_ratio | ... | ... | std20_mean20_ratio |
📕Environment
- Agent의 action에 대해서 Environment가 state를 반환해줄 수 있는 가상 환경을 구현하였습니다.
📘Environment reaction process
- Agent의 action(long, short, none)에 대해서 Envrionment는 다음의 과정을 거쳐 반응합니다.
- action을 수행할 수 있는지 검증. (action 수행을 위한 잔고 여분 확인)
- action에 대해서 진입 수량을 결정. (action의 확률에 따라 진입 수량 결정)
- action 수행. (Envrionment의 현재 포지션에 따라 action 수행)
- balance state 업데이트.
- 포지션/자금 비율 업데이트
- 손익 업데이트
- 현재 포지션 업데이트
- 평균 수익률 업데이트
📘Balance state update
- agent의 action 수행 이후 Balance 정보를 업데이트 합니다.
📒Balance state
- agent의 action에 의해 업데이트 되는 balance state는 (hold ratio, profit loss, position, avg return) 이고 각각 "포지션/자금 비율", "손익", "현재포지션", "평균 수익률"입니다. 계산 공식은 아래와 같습니다.
📕Learner
- A3C는 여러개의 Actor Learner를 각각 독립된 환경에서 병렬적으로 학습하고 Gloabal network를 업데이트 시킵니다.
📘train mode
- 설정한 --mode에 따라서 train, update, test, monkey가 존재하며 각각의 특성과 해당 부분의 코드는 아래와 같습니다.
| --mode | description |
|---|---|
| train | 모델 훈련, Actor가 출력한 action space에서 확률에 기반해 action 선택 |
| update | 모델 업데이트, 기존에 훈련된 Network 파라미터를 업데이트, 모델 훈련과 동일 |
| test | 모델 테스트, 훈련된 Network로 action space 출력, 가장 높은 확률값의 action 선택 |
| monkey | 랜덤 action 선택, 무작위 행동과 각 모델의 수행 능력을 비교 |
learner.py
# [train, update] : 정책신경망의 출력을 받아 확률적으로 행동을 선택
def get_action(self, c_observed, b_observed) :
c_observed, b_observed = self.reshape_state(c_observed, b_observed)
policy = self.local_model([c_observed, b_observed])[0][0]
# action space 출력 결과를 softmax 함수로 변화하여 확률 분포 생성
policy = tf.convert_to_tensor(utils.softmax(policy))
# softmax에 의해 변환된 확률 분포에 따라서 action 선택
action_index = np.random.choice(self.action_size, 1, p=policy.numpy())[0]
return action_index, policy # [test] : 최대 확률 값을 행동으로 선택
def test_get_action(self, c_observed, b_observed) :
c_observed, b_observed = self.reshape_state(c_observed, b_observed)
policy = self.local_model([c_observed, b_observed])[0][0]
# action space 출력 결과를 softmax 함수로 변환하여 확률 분포 생성
policy = tf.convert_to_tensor(utils.softmax(policy))
# 가장 최적의 action 선택
action_index = np.argmax(policy.numpy())
return action_index, policy # [monkey] : 무작위 행동 선택, policy = [1/n, 1/n, ..., 1/n]
def monkey_get_action(self) :
action_index = np.random.randint(self.action_size)
policy = [1/self.action_size for _ in range(self.action_size)]
return action_index, policy📘loss function
📒Loss functoin
- Loss function은 Actor Loss, Critic Loss, 정책 확률의 entropy로 구성되어 있습니다.
- Critic Loss : TD Error를 작게하고자 MSE의 개념인 를 사용하였습니다.
- Actor Loss : policy의 분포를 균등 분포에서 벗어나서 특정 action을 선택하도록 유도하고 Critic의 TD Error가 작은 값을 유도하고자 를 사용하였습니다.
- entropy : policy가 균등 분포에서 벗어나 특정 action의 확률을 높힐 수 있게끔 entropy를 추가하였습니다.
📒Loss functoin Equation
📒TD Error
- TD Error는 총 16의 timestep까지 계산하였습니다. (batch = 16)
TD Error 수식
📕훈련 및 테스트 결과 확인
📘Model Train : loss history
- LSTMDNN모델과 DNN모델의 epoch별 loss 추이는 아래와 같습니다.
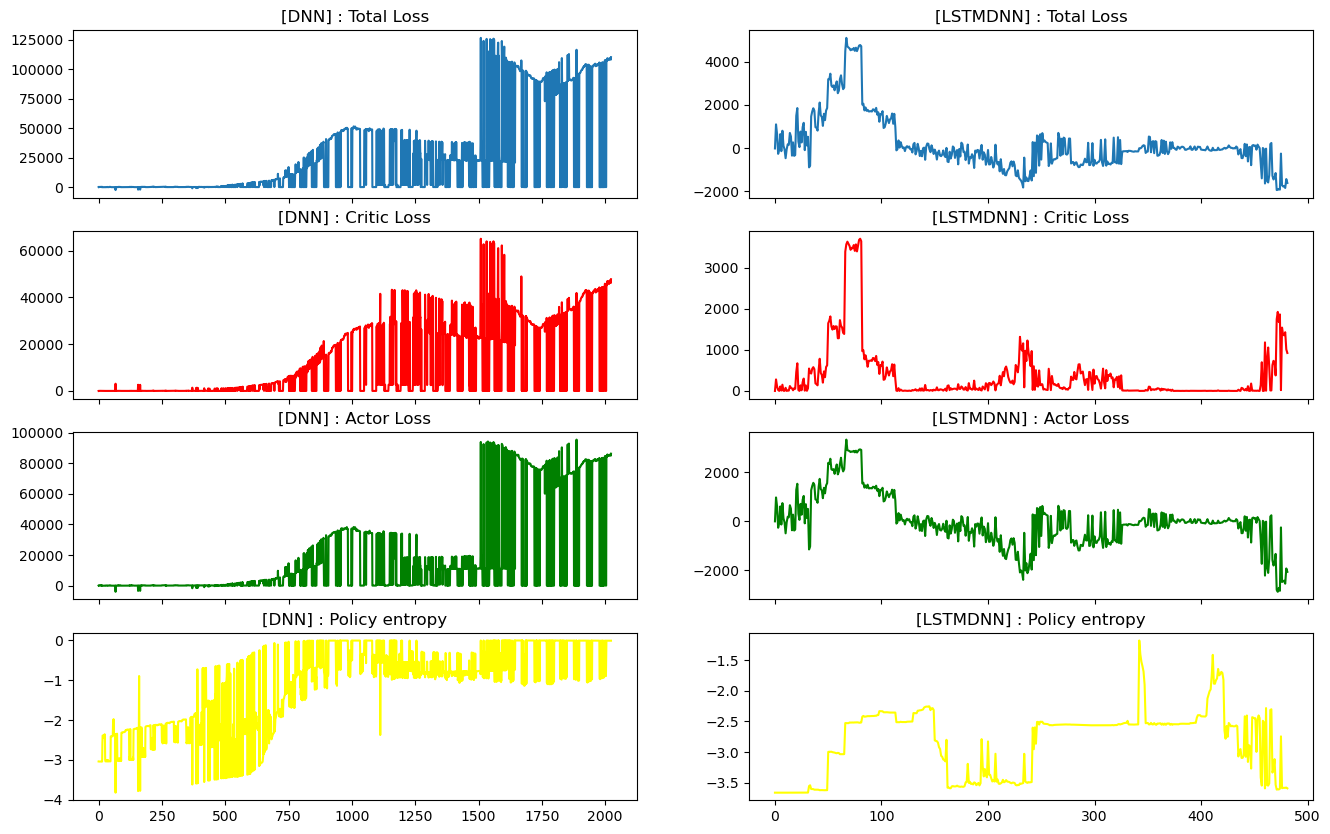
- 비교를 위해 생성한 DNN 모델은 학습이 되지 않는 모습을 보이고, 그에 반해 LSTMDNN모델은 점점 loss를 줄여가는 모습을 보여줬습니다.
- 다만, critic loss가 증가해도 actor loss가 그 부분을 상쇄하여 total loss는 줄어드는 모습을 보여줬습니다. 이는, value function을 적절하게 예측해야하는 Critic부분이 제 역할을 못하는 상황을 초래할 수 있습니다.
- policy의 entropy는 감소하고 있다고 판단하기 어렵습니다. 즉, actor가 특정 action을 신뢰도 있게 예측하지 못한다고 판단할 수 있습니다. 주식 데이터는 입력 데이터의 수에 비해 복잡도가 너무 높은 것이 문제일 것이라고 생각합니다.
📘Predict : compare PL
- 학습한 LSTMDNN, DNN모델과 랜덤 선택으로 action을 결정하는 MONKEY의 손익을 비교하면 아래와 같습니다.
- 비교 기준은 cmd 입력 인자인 --start_date 입니다. (--end_date 기본값인 20221220으로 동일합니다.)
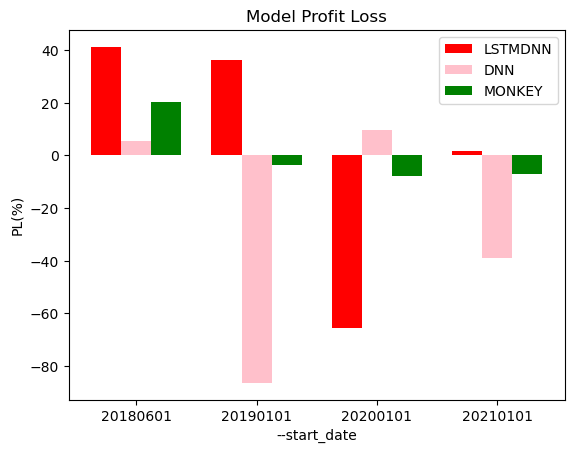
- LSTMDNN가 전반적으로 좋은 손익을 내었고 DNN 모델은 랜덤 선택인 MONKEY보다 더 안 좋은 모습을 보여줬습니다. 즉, 데이터 수가 적고 복잡도가 높은 주가 데이터를 위해 순환 신경망 구조를 결합하여 설계한 LSTMDNN모델이 입력 데이터를 잘 해석했다고 판단할 수 있습니다.
- 다만, 크게 손실을 보는 기간도 존재하기 때문에 안정적으로 수익이 나는 RL 모델이라고 하기는 어렵습니다.
📕cmd (argparser)
| 입력인자 | 설명 | type | default |
|---|---|---|---|
| 로그 파일의 이름 | 파일실행시간 | ||
| 투자 종목 코드 | '005380' (=현대자동차) | ||
| 신경망 모델 설정 | = ['LSTMDNN', 'DNN'] | 'LSTMDNN' | |
| 학습 모드 | =['train', 'test', 'update', 'monkey'] | 'train' | |
| 훈련 데이터 시작일 | '20180601' | ||
| 훈련 데이터 마지막일 | '20221220' | ||
| learning rate | 0.0001 | ||
| LSTMDNN Network의 n_steps | 10 | ||
| 초기 잔고 | 100000000 |
main.py 내 입력 인자
parser = argparse.ArgumentParser()
parser.add_argument('--name', default=utils.get_time_str())
parser.add_argument('--code', type=str, default='005380')
parser.add_argument('--model', choices=['LSTMDNN', 'DNN'], default='LSTMDNN')
parser.add_argument('--mode', choices=['train', 'test', 'update', 'monkey'], default='train')
parser.add_argument('--start_date', default='20180601')
parser.add_argument('--end_date', default='20221220')
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--n_steps', type=int, default=10)
parser.add_argument('--balance', type=int, default=100000000)
args = parser.parse_args()
예시
- 종목코드 '005380'을 n_step이 10인 LSTMDNN 신경망으로 훈련 시킴. learning rate는 0.0001. 훈련 데이터는 20200101 ~ 20221220
python main.py --code 005380 --model LSTMDNN --mode train --start_date 20200101 --lr 0.0001 -- n_steps 10
- 종목코드 '005380'을 n_step이 10인 기존에 훈련된 LSTMDNN 신경망으로 업데이트 시킴. learning rate는 0.00006, 업데이트 데이터는 20180601~20221220
python main.py --code 005380 --model LSTMDNN --mode update --start_date 20200101 --lr 0.00006- 종목코드 '005380'을 DNN 신경망으로 훈련 시킴. learning rate는 0.0001, 업데이트 데이터는 20180601~20221220
python main.py --code 005380 --model DNN📕고찰
📘학습 환경에 대한 고찰
- 설계한 Agent과 Environment는 선물 거래를 염두한 롱/숏 포지션이 가능하도록 구현했습니다. 이번 프로젝트에서는 단방향 주식 데이터로 진행을 했습니다. 추후, BTC 선물 데이터로 해당 프로젝트를 발전시킬 계획입니다.
📘critic loss와 batch 사이의 trade off에 대한 고찰
- Actor network의 policy entropy가 감소하지 않는 모습을 보였습니다. 이는, total loss를 계산할 때 actor loss 와 critic loss의 비율이 커서 entorpy loss가 영향을 못 미치기 때문이라고 생각합니다. 훈련 과정에서 각 loss들에 대해서 여러번 튜닝 했지만, critic loss와 actor loss는 지속적으로 커지고, 서로를 상쇄하는 모습을 보였습니다. 이 부분은 critic loss가 커졌기 때문에 발생한 것이라고 판단되며 TD Error의 timestep이 커질 수록 critic loss가 커지는 것을 확인했습니다.
- 하지만, TD Error의 timestep을 줄이면 학습의 batch size가 줄어들어 훈련 시간이 너무 길어지는 문제가 발생했습니다. 현재, gpu가 없는 cpu 환경에서 학습을 진행해야 했기에 그 부분을 고려하지 않을 수 없었습니다.
- 따라서, 추후 study에서는 이러한 trade off를 어떻게 해결해야 할지 고민하는 시간을 갖겠습니다.
감사합니다.
