
1장. SQL기본
SQL : DB의 데이터를 정의, 조작, 제어할 수 있는 언어
DML : SELECT, INSERT, UPDATE, DELETE
DDL : ALTER, DROP, CREATE, RENAME
DCL : GRANT, REVOKE
TCL : COMMIT, ROLLBACK (dcl에 포함됨)
가로행, 세로컬럼
정규화 : 데이터 CRUD시 발생할 수 있는 이상현상을 방지하기 위해 중복제거
기본키, 외래키
DDL (Auto COMMIT)
: 데이터 정의어, DB를 정의하는 언어
char(고정길이 문자열) varchar(가변길이 문자열) date(날짜 및 시간) number(숫자)
제약조건
기본키 : UNIQUE & NOT NULL
UNIQUE KEY : 고유키 정의 ,null가능
FOREIGN KEY : null 가능
테이블 생성 > CREATE
테이블 구조 변경 > ALTER TABLE -- ADD, DROP COLUMN, MODEFY, DEFAULT
제약조건 > CONSTRAINT
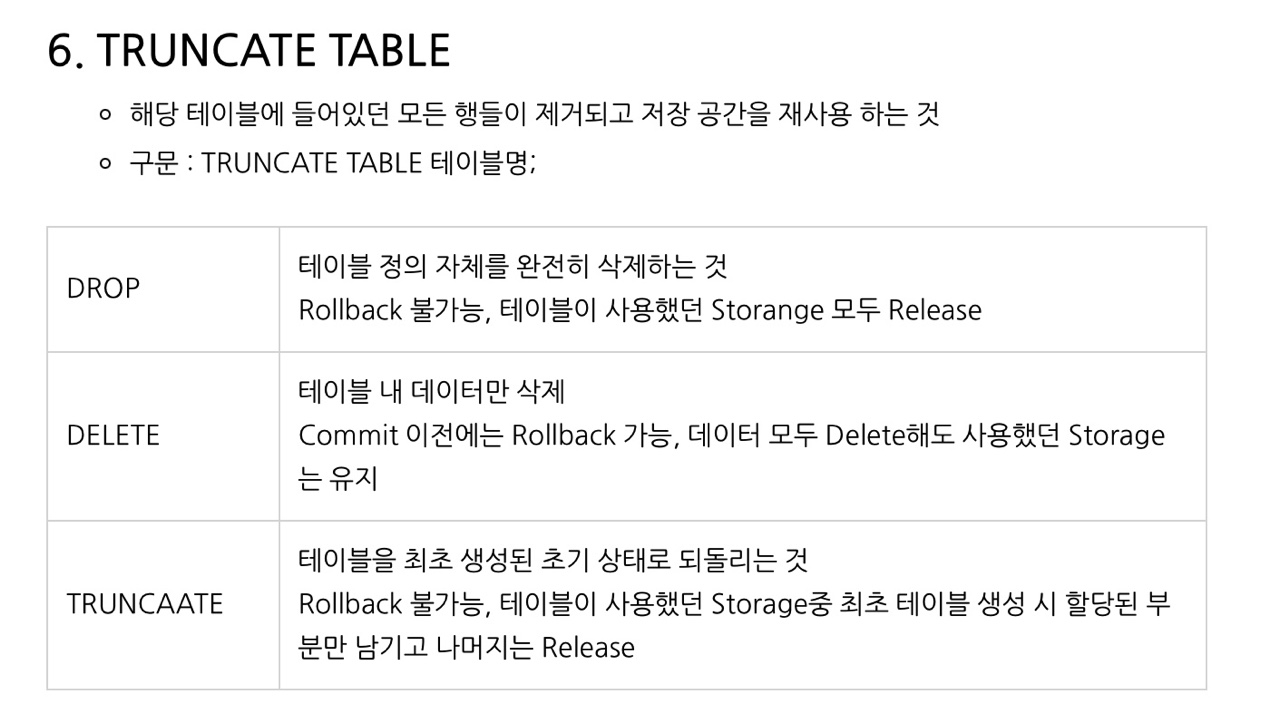
테이블 삭제 > DROP
테이블 데이터 삭제(초기상태) > TRUNCATE
컬럼명 변경 > RENAME COLUMN -- TO --
DML (NOT AUTO COMMIT)
: 데이터 조작어, 데이터를 입력하는,,
INSERT, DELETE, UPDATE, SELETE
TCL
트랜잭션 : DB조작
COMMIT, ROLLBACK, SAVEPOINT
트랜잭션의 특징 : 원자성, 고립성, 일관성, 지속성
연산자 종류
BETWEEN A AND B > a,b를 포함한
IN (LIST) (A, B) > a또는 b
ROWNUM > 원하는 만큼의 행
TOP > 결과 집합에서 출력되는 행위 수 제한
LOWER > 소문자로
UPPER > 대문자로
CONCAT(a,b) > ab
SUBSTR(abc,2,2) > bc
LENGTH > 길이를 숫자값으로
TRIM(' abc') > abc
SIGH > 사인값
MOD(8, 3) > 2
CEIL(3.8) >
FLOOR(3.8) > 3
ROUND(38.5235, 3) > 38.524
TRUNC(38.5235, 3) > 38.523
SYSDATE > 현재날짜와 시간
1 = 하루 , 1/24/60 = 1분
NVL(a,b) > a가 null이면 b
NULLIF(a,b) > a=b면 null
COALESCE(null,b) > b
DISTINCT > 중복제거
COUNT(*) > null을 포함한 행의 개수
COUNT() > null제외
SUM, MAX, AVG > 집계함수는 null 제외
GROUP BY > ALIAS X
ORDER BY > 오름차순(ASC)가 default, ALIAS O, 오라클에서는 null이 가장 큼 나머진 반대
WITH TIES > 같은 급여를 받는 사람은 같이 출력
문장 실행 순서 FROM > WHERE > GROUP BY > HAVING > SELETE > ORDER BY
2장. SQL활용
일반 집합 연산자 :
- UNION > 합집합
- UNION ALL > 합집합(중복포함)
- INTERSECT > 교집합
- MINUS > 차집합
- CROSS JOIN > 곱집합
UNION과 UNION ALL에서 ORDER BY는 맨 마지막에
FROM절 JOIN :
- INNER JOIN > 동일한 값
- NATURAL JOIN > 동일한 이름, ALIAS X, ANSI X, 특정 Join컬럼을 명시적으로 적을 수 있음.
- USING 조건절 > 같은 이름 컬럼 중 원하는 것만
- ON 조건절 > 컬럼명이 달라도 join
- CROSS JOIN > 카티시안 곱
- OUTER JOIN > LEFT, RIGHT, (+)안 붙은 쪽
계층형 질의
- SRART WITH > 시작위치
- CONNECT BY PRIOR > 다음에 전개될 자식
- NOCYCLE > 동일 데이터 전개 X
- ORDER SIBLINGS BY > 형제 노드간 정렬
- LEVER > 루트데이터는 1
- CONNECT_BY_ISLEAF > 리프면 1 아니면 0
- CONNECT_BY_ISCYCLE > 해당 데이터가 조상이면 1 아니면 0
- SYS_CONNECT_BY_PATH > 루트 데이터부터 현재 데이터 경로
- CONNECT_BY_ROOT > 전개할 루트 데이터 표시
서브쿼리 : 다른 SQL문 (ORDER BY X)
인라인 뷰 : FROM절의 서브쿼리
스칼라 서브쿼리 : SLELTE절의 서브쿼리, 단일행
뷰 : 실제 데이터를 가지지 않은 가상의 테이블
뷰 사용 장점 : 독립성, 편리성, 보안성
ROLLUP : 소그룹 간 합계
GROUPING : 집계표시면 1 아니면 0
CUBE : 결합 가능한 모든 다차원 집계
GROUPING SET : 인수들의 개별 모든 집계
RANK > 1,2,2,4
DENSE_RANK > 1,2,2,3
ROW_NUMBER > 1,2,3,4
FIRST_VALUE > 윈도우 첫 값
LAST_VALUE > 윈도우 마지막 값
LAG > 윈도우 이전 몇 번째 행의 값
LEAD > 윈도우에서 이후 몇 번째 행의 값
RATIO_TO_REPORT > sum에 대한 컬럼값의 백분율을 소수점
PERCENT_RANK > 윈도우 첫 번째를 0, 마지막을 1 백분율
CUME_DIST > 현재 행보다 작거나 같은 건수의 대한 누적 백분율
NTLIE > 전체 건수를 인수 값으로 n등분 결과
NTILE(4) -> 4등급으로 나뉜다.
총 건수가 7개면 1등급, 2등급, 3등급 2개씩, 4등급 1개
DCL
REVOKE : 권한 취소
GRANT : 권한 부여
ROLE : 유저에게 알맞은 권한을 한 번에 부여하기 위해
절차형 SQL : Procedure, Trigger 등
저장 모듈 : PL/SQL 문장을 DB 서버에 저장하여 사용자와 애플리케이션 사이에서 공유할 수 있도록 만든 SQL 컴포넌트 프로그램
PL/SQL
- Block구조, 모듈화 ㄱㄴ
- 변수, 상수를 선언하여 sql문장 간 값 교환
- if, loop등 절차형 언어 사용
- DBMS 정의 에러 사용
- 호환성 좋음
- 응용프로그램의 성능 향상
- Block 단위로 처리해서 통신량 줄임
DECLARE : BEING~END 절에서 사용될 변수와 인수에 대한 정의 및 데이터 타입 선언
BEING~END : 개발자가 처리하고자 하는 SQL문과 여러가지 비교, 제어문을 이용 필요한 로직 처리, 실행부(필수)
EXCEPTION : 예외 처리부
T-SQL : sql-server 제어하는 언어
USER DEFINED FUNCTION > Procedure처럼 절차형 SQL을 로직과 함계 DB내에 저장해놓은 명령문 집합
TRIGGER : 특정 테이블에 DML문이 실행되면 자동으로 수행
프로시저 : BEING~END절에 COMMIT, ROLLBACK 가능 EXECUTE 명령어로 실행
트리거 : BEING~END절에 사용 X
옵티마이저 : 사용자가 질의한 SQL문에 대해 최적의 실행방법을 결정하는 역할
규칙기반 옵티마이저 : 우선순위를 기준으로 실행계획 생성
비용기반 옵티마이저 : 필요한 비용(자원 사용량)이 가장 적은 계획을 선택하는 방식
SQL 처리 흐름도 : SQL 내부적인 처리 절차를 시각적으로 표현(조인순서, 조인기법, 엑세스 기법 등)한 도표
인덱스 : 원하는 데이터를 쉽게 찾을 수 있도록 도와주고, 검색 성능 최적화를 목표
외래키가 설계되어 있지만 인덱스가 없는 상태라면 입력/삭제/수정의 부하가 덜 생긴다.

B-tree 기반 인덱스, 데이터는 컬럼 값으로 정렬
브랜치 블록과 리프 블록으로 구성되며 브랜치 블록은 분기를 목적으로, 리프 블록은 인덱스를 구성하는 칼럽의 값으로 정렬
조인 : 두 개 이상의 테이블을 하나의 집합으로 만드는 연산
NL Join : 프로그래밍에서 사용하는 중첩 반복문과 유사한 방식
Sort Merge Join : 조인 컬럼을 기준으로 데이터를 정렬하여 조인을 수행
SQL setOperation 중 중복 제거하려고 정렬작업을 안 함.
Hash Join : 조인 컬럼을 기준으로 해쉬 함수를 수행하여 서로 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지 비교하며 조인
동등 조건 외 사용 X
명시적 커서에서 FETCH단계 이후 CLOSE CURSOR가 수행된다.
UNBOUNDED PRECENDING은 end point(문장 끝)에 사용 X
