
행 기반 데이터베이스
테이블이 디스크에 행으로 저장된다
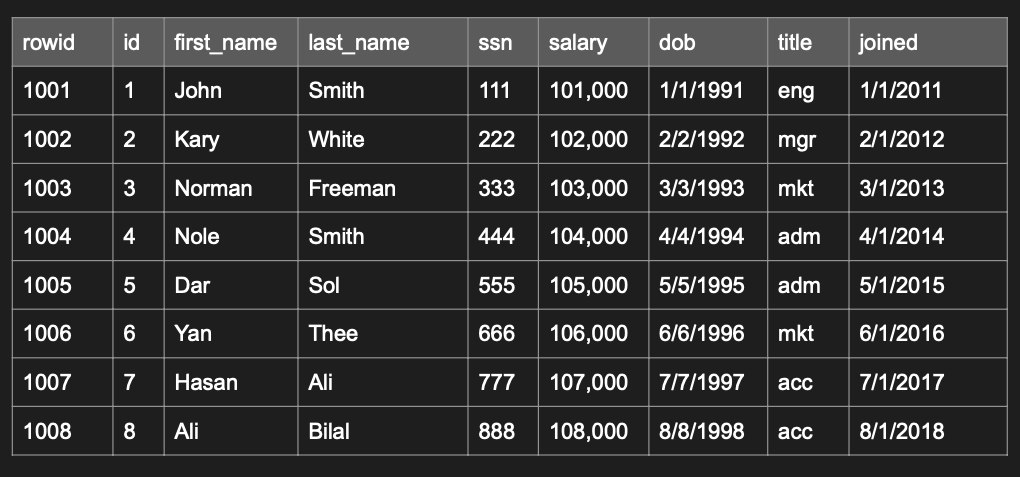
위와 같은 테이블은 다음과 같은 블록으로 저장된다

행마다 데이터의 크기가 다르게 저장된다
행 기반 데이터베이스 쿼리
특정 행을 읽고 싶을 때 블록을 읽어야 한다
하나의 블록에는 여러 행들이 들어 있다
따라서 특정 행을 찾으려면 더 많은 IO가 필요하다

테이블을 순차적으로 탐색하고 ssn=666인 행의 first_name을 찾는 쿼리는 위와 같이 디스크를 스캔한다
행 기반에서는 찾고 있는 행에 도달하기 위해 많은 탐색을 수행하고, 필요하지 않은 열을 가져오면서 낭비된 읽기가 발생한다

이 쿼리도 마찬가지로 salary 열만 얻기 위해서 모든 블록을 탐색해야하고, 필요하지 않은 열도 가져오게 된다
이는 많은 오버헤드를 발생시킬 수 있다
열 기반 데이터베이스
열 기반 데이터베이스는 테이블이 디스크에 열로 먼저 저장된다
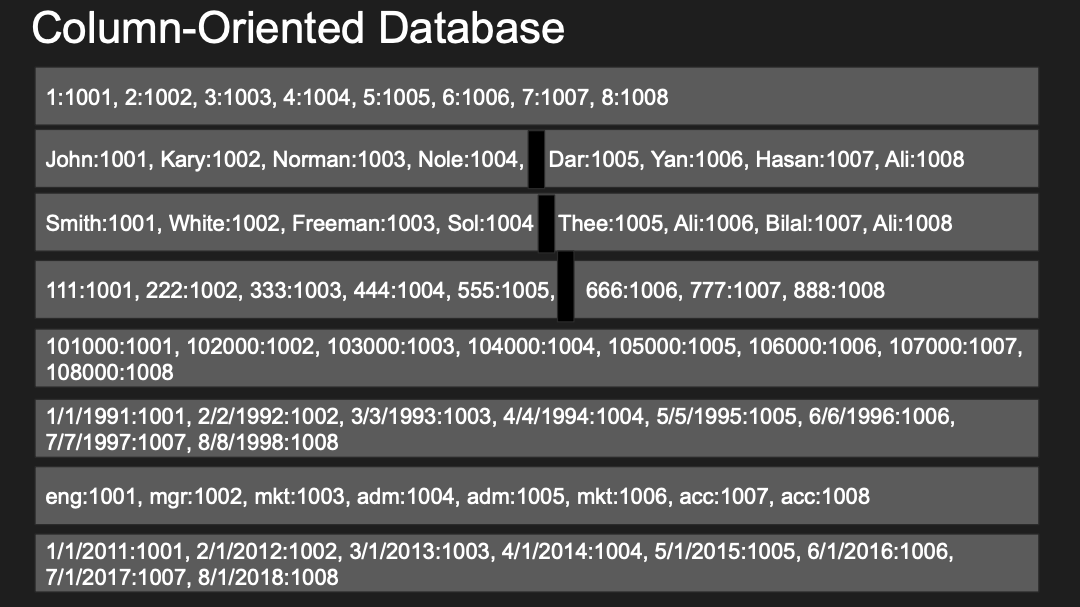
테이블에 단일 블록 IO 읽기를 하면 모든 일치하는 행을 갖는 여러 열을 가져온다
하지만 열을 추가하려면 테이블에 모든 블록에 내용을 업데이트해야 한다
열 기반 데이터베이스 쿼리

위 쿼리에서는 먼저 ssn이 저장된 블록들 중에서 ssn=666인 데이터를 찾아 row_id 값을 찾는다
찾은 row_id 값으로 다시 first_name 블록 중에서 일치하는 데이터를 찾는다
이는 인덱스와 유사하다
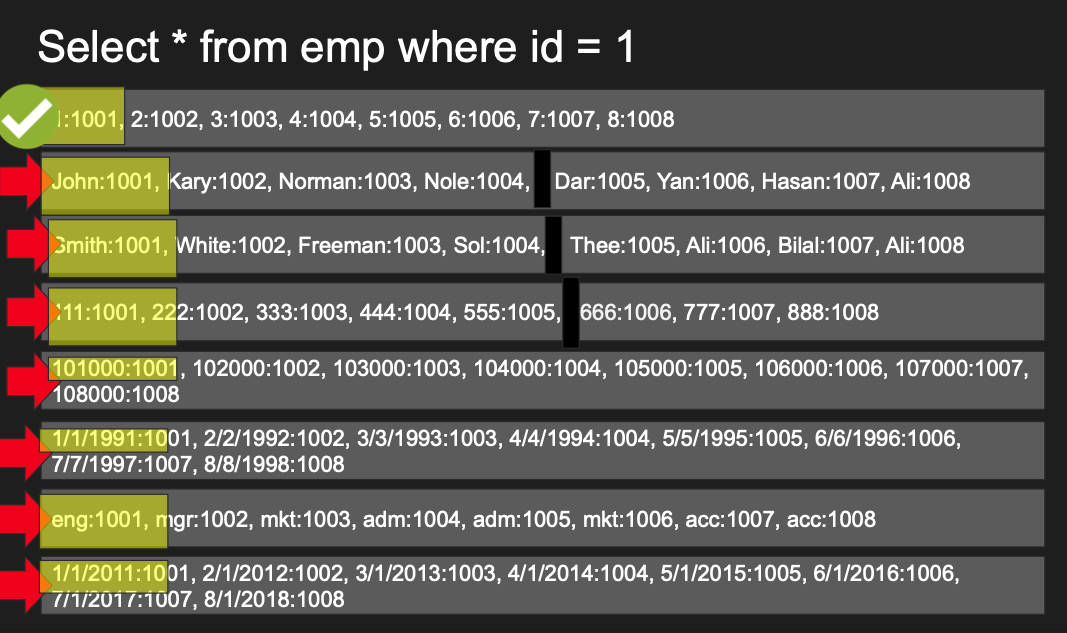
select * 쿼리는 열 기반 데이터베이스에서 모든 블록에 대해 IO가 발생하므로 쓰면 안된다

위 쿼리의 경우 하나의 블록만 읽으면 되므로 엄청난 장점이 있다
만약 salary 블록이 여러 개라면, 여러 개를 읽어야 하지만 행 기반 데이터베이스보다 훨씬 좋다
장단점
| 행 기반 | 열 기반 |
|---|---|
| 쓰기가 빠르다 | 쓰기가 느리다 |
| OLTP | OLAP |
| 압축, 합계과 효과적이지 않다 | 압축, 합계에 효과적이다 |
| 다중 열에 대해 쿼리가 효과적이다 | 단일 열에 대해 쿼리가 효과적이다 |
