
저장소 개념
- Table
- Row_id
- Page
- IO
- Heap
- Index b-tree
Table
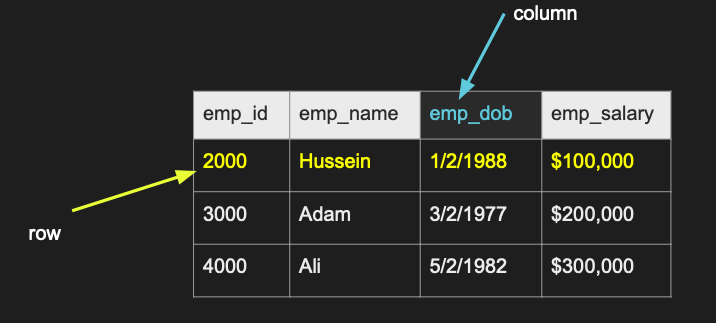
테이블은 행과 열로 이루어진다
열에는 실제 정보가 들어있다
Row_ID
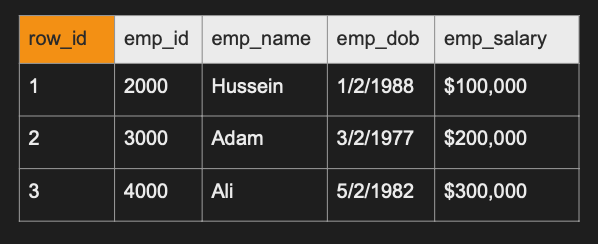
대부분의 데이터베이스는 자체적으로 유지하는 행인 Row_ID를 만든다
이는 행 자체에서의 위치로 특정 행을 고유하게 식별한다
Page
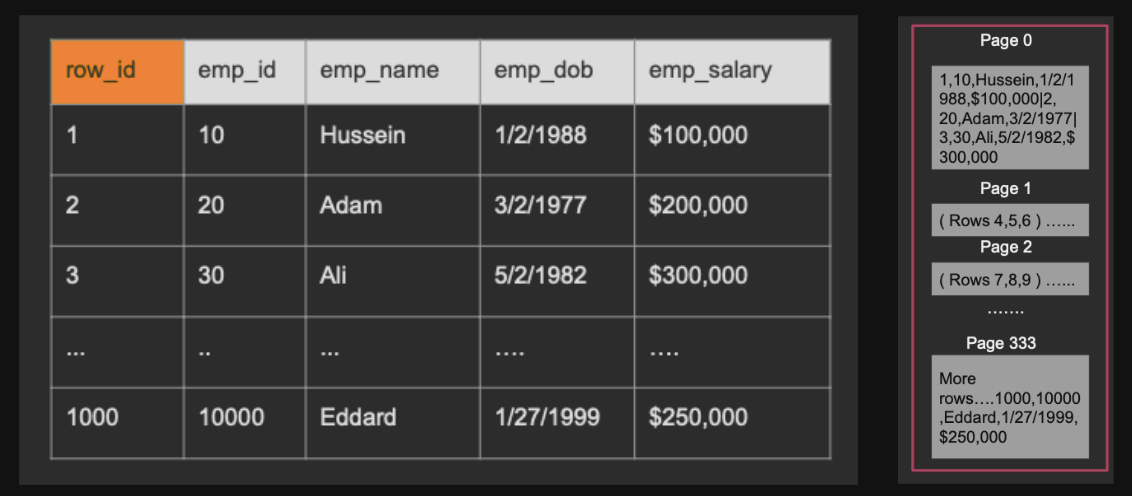
페이지는 고정된 크기의 메모리 위치로, 디스크 위치로도 변환되는 일련의 바이트다
행들은 논리적인 페이지에 저장되고 행의 크기에 따라 많은 행이 한 페이지에 들어갈 수 있다
데이터베이스는 실제로 단일 행을 읽을 수 없고 페이지 단위로 데이터를 읽는다
현재 사진에서 1000번째 데이터를 가져오려면 Page 0 부터 끝까지 모든 페이지를 봐야한다
IO
IO는 디스크로 읽고 쓰는 요청이다
이 요청을 최소화할수록 쿼리가 더 빨라진다
IO 한 번으로 하나의 행을 읽을 수 없고, 많은 정보가 있는 페이지를 읽는다
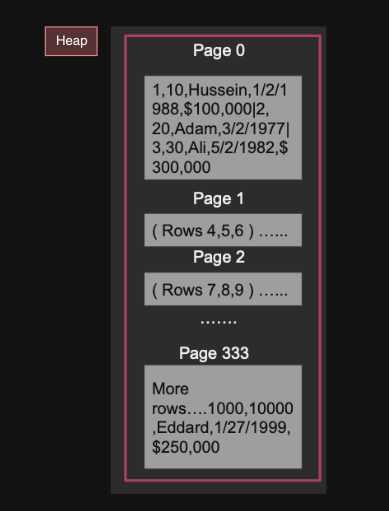
Heap
힙은 모든 페이지를 포함한 테이블을 저장한다
힙에서 원하는 데이터만 탐색하는 것은 비싸기 때문에 인덱스가 필요하다
Index
인덱스는 힙을 가리키는 포인터를 가진 자료 구조다
포인터는 주로 Row_ID를 가리키는 단순한 숫자이고, Row_ID에는 힙의 페이지에 대한 더 많은 메타데이터가 있다
인덱스는 일부 데이터를 가지고 있어서 빠르게 탐색을 할 수 있다
인덱스는 B-Tree 자료 구조를 사용한다
인덱스는 힙에서 모든 페이지를 탐색하는 대신 정확히 어떤 페이지를 가져와야 하는지 알려준다
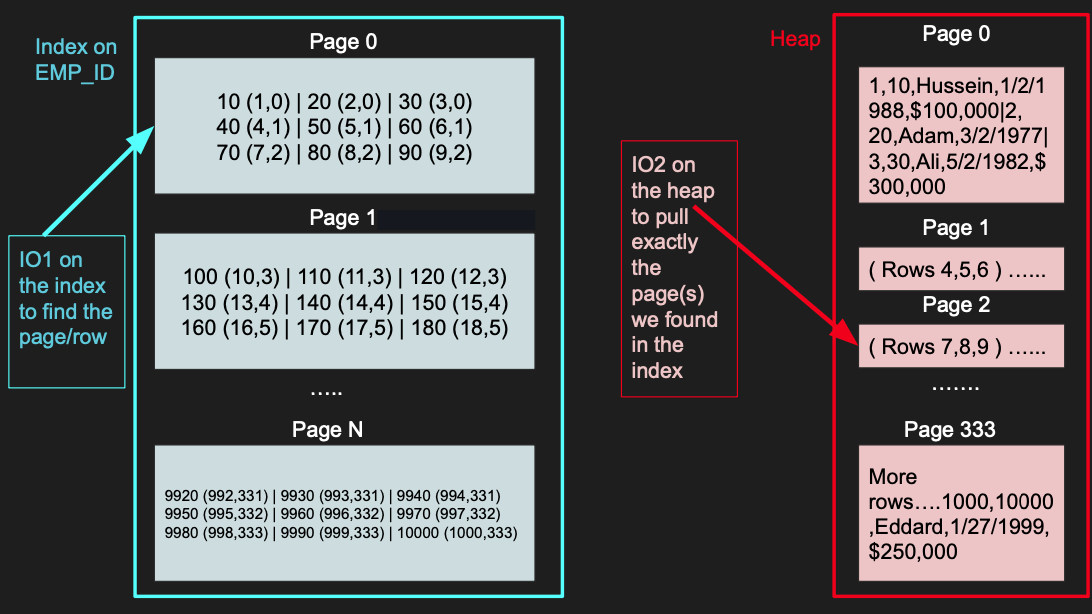
인덱스에서 emp_id를 인덱싱했다면 emp_id만 볼 수 있다
(1,0)은 emp_id 10 값이 페이지 0에 1번 행에 있다는 걸 뜻한다
