
스레드의 메모리 접근 방식과 그에 따른 문제점
다음 코드는 둘 이상의 스레드가 한 메모리 공간(한 변수)에 접근했을 때 발생하는 문제를 보여준다.
public class MultiAccess {
public static Counter cnt = new Counter();
public static void main(String[] args) throws InterruptedException {
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.increment();
}
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.decrement();
}
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
t1.join(); // t1이 참조하는 스레드 종료 대기
t2.join(); // t2가 참조하는 스레드 종료 대기
System.out.println(cnt.getCount());
}
}
class Counter {
int count = 0; // 두 스레드에 의해 공유되는 변수
public void increment() {
count++; // 첫 번째 스레드에 의해 실행됨
}
public void decrement() {
count--; // 두 번째 스레드에 의해 실행됨
}
public int getCount() {
return count;
}
}
// 실행결과
-311
-233다음 join 메소드는 특정 스레드의 실행이 완료되기를 기다릴 때 호출한다.
public final void join() throws InterruptedExceptionmain 스레드가 두 스레드의 실행이 완료되기를 기다리기 위해서 join 메소드를 호출했다.
실행 결과는 예상과 다르다.
increment 천 번, decrement 천 번이므로 출력 결과는 0이어야 하는데, 실행할 때마다 출력 값이 다르다.
이를 통해 다음을 유추할 수 있다.
둘 이상의 스레드가 동일한 변수에 접근하는 것은 문제를 일으킬 수 있다.
따라서 둘 이상의 스레드가 동일한 메모리 공간에 접근해도 문제가 발생하지 않도록 동기화(synchronization)를 해야한다.
동일한 메모리 공간에 접근하는 것은 왜 문제가 되는가?
변수에 저장된 값을 1씩 증가하는 연산을 두 스레드가 동시에 진행한다고 가정한다.
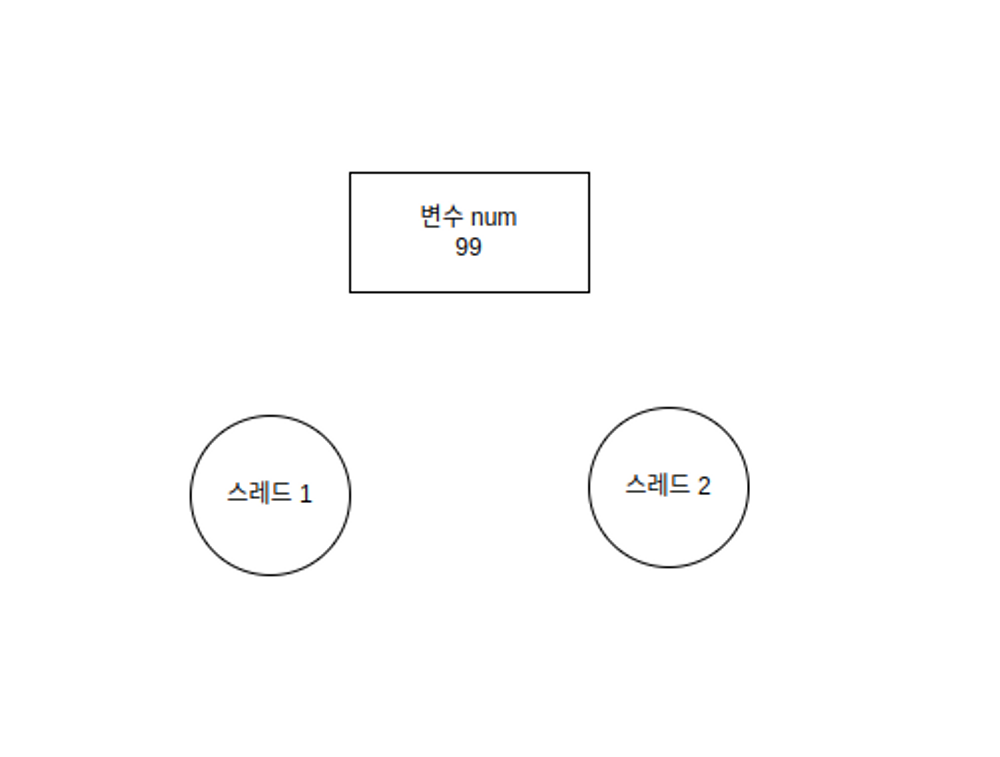
위 그림의 상황에서 스레드1이 변수 num의 값을 1 증가시키면 100이 된다.
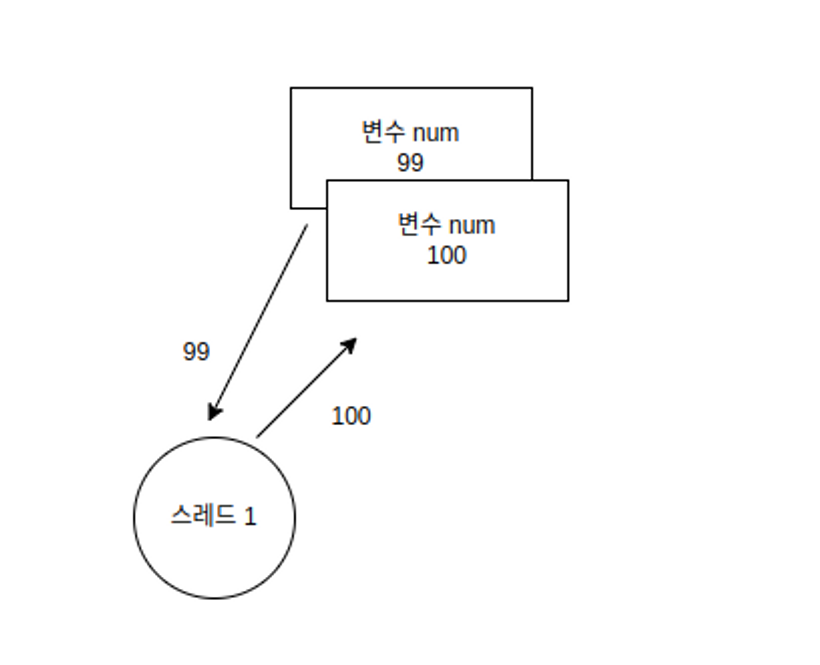
값의 증가는 코어를 통해 연산이 필요한 작업이다.
스레드 변수 num에 저장된 값 99를 가져다 코어의 도움을 받아서 이를 100으로 만드는 과정을 거친다.
그리고 나서 이 값을 변수 num에 가져다 놓는다.
그래야 비로소 num의 값이 증가하고, 이것이 변수에 저장된 값이 변경되는 방식이다.
다음과 같이 스레드1, 스레드2도 값을 증가시키기 위해 변수 num에 저장된 값 99를 가져갔다고 가정한다.
시차를 두고 가져갈 수 있지만 코어가 여러개면 거의 동시에 가져가는 것도 가능하다.
각각 이 값을 증가시켜 100으로 만든다.
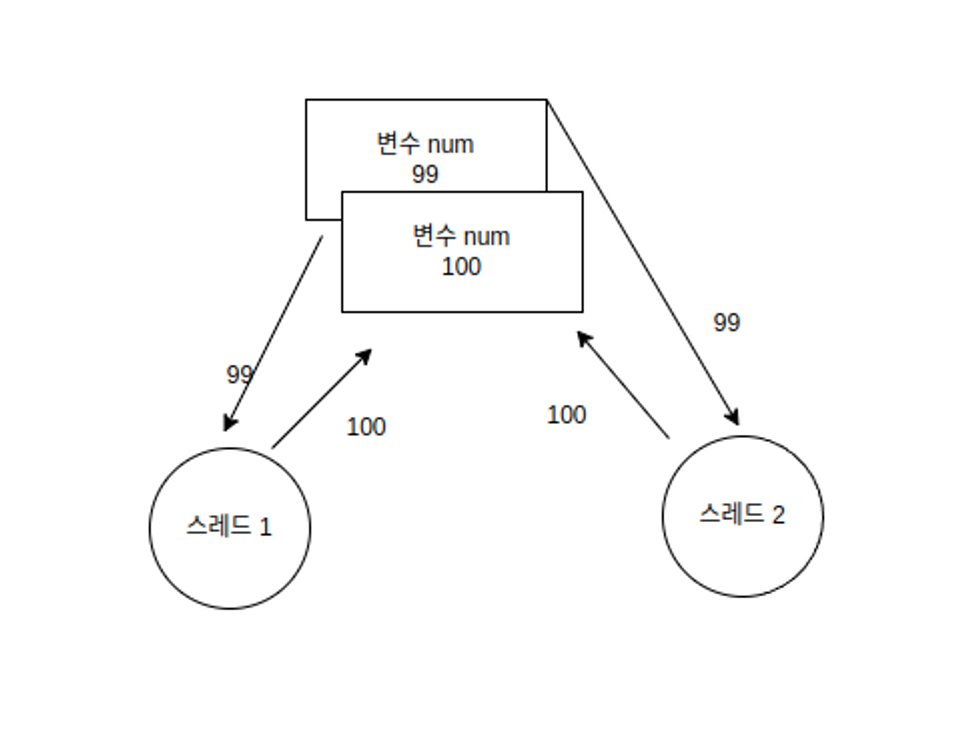
마지막으로 증가시킨 값을 다시 변수 num에 각각 가져다 놓는다.
그러면 변수 num에는 101이 아닌 100이 저장된다.
두 스레드 모두 100을 가져다 놓기 때문이다.
이 상황은 위 예제에서 많이 발생했다.
이 문제는 한순간에 한 스레드만 변수에 접근하도록 제한하면 해결된다.
동기화(Synchronization) 메소드
앞서 정의한 Counter 클래스의 메소드에 다음과 같이 synchronized 선언을 추가하면 동기화가 이뤄진다.
synchronized public void increment() {
count++;
}synchronized 선언이 추가되면, 이 메소드는 한순간에 한 스레드의 접근만 허용한다.
앞서 보인 Counter 클래스는 다음과 같이 동기화를 하면 된다.
class Counter {
int count = 0; // 두 스레드에 의해 공유되는 변수
synchronized public void increment() {
count++; // 첫 번째 스레드에 의해 실행됨
}
synchronized public void decrement() {
count--; // 두 번째 스레드에 의해 실행됨
}
public int getCount() {
return count;
}
}
// 실행 결과
0
0
0동기화(Synchronization) 블록
동기화 메소드 기반의 동기화는 사용하기 편하지만 메소드 전체에 동기화를 걸어야 한다는 단점이 있다.
synchronized public void increment() {
count++; // 동기화 필요
System.out.println("카운터 값 증가"); // 동기화 불필요
}동기화가 불필요한 부분을 실행하는 동안에도 다른 스레드의 접근을 막는 일이 발생한다.
이러한 경우 동기화 블록을 이용해 문장 단위로 동기화 선언을 하는 것이 효율적이다.
public void increment() {
synchronized (this) { // 동기화 블록
count++;
}
System.out.println("카운터 값 증가"); // 동기화 불필요
}동기화 블록은 둘 이상의 스레드에 의해 동시에 실행될 수 없도록 함께 동기화된다.
동기화 블록을 사용한 코드는 다음과 같다.
