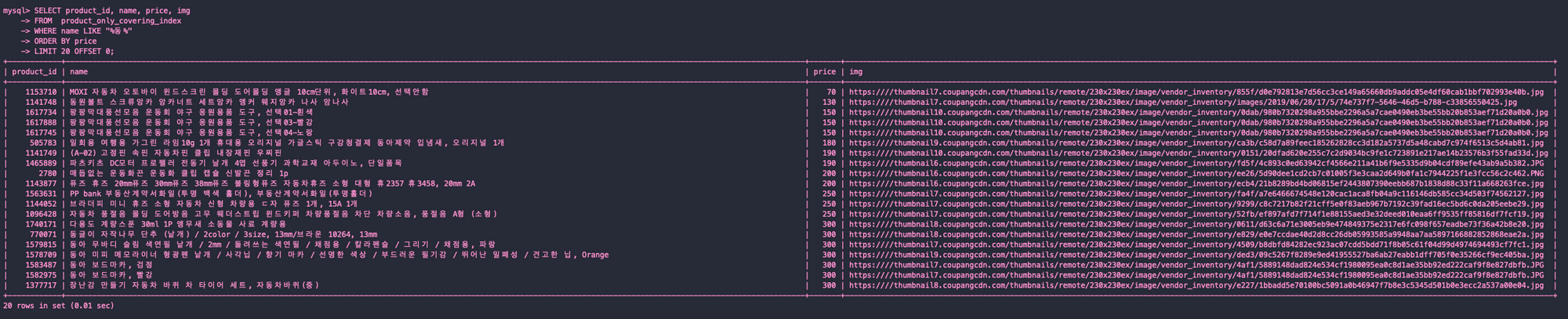
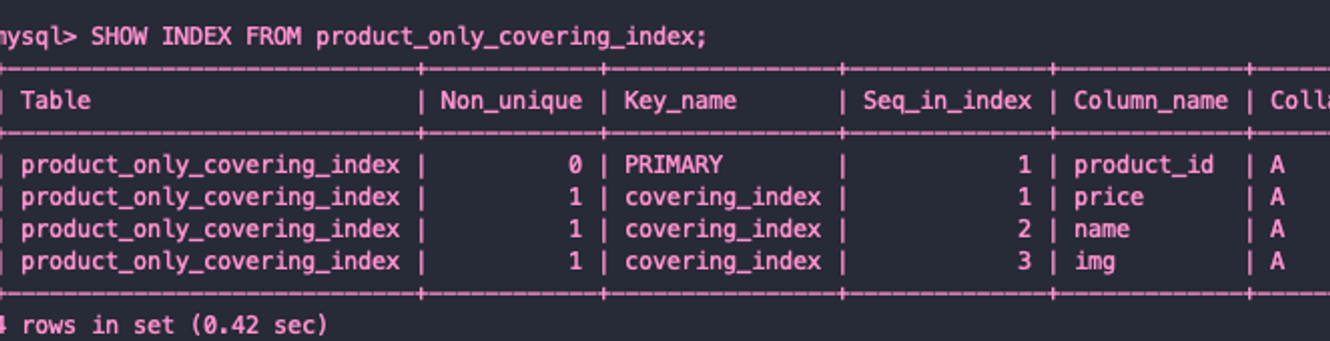
커버링 인덱스
https://dev.mysql.com/doc/refman/8.0/en/glossary.html#glos_covering_index
covering index
An index that includes all the columns retrieved by a query.
Instead of using the index values as pointers to find the full table rows, the query returns values from the index structure, saving disk I/O.
…
인덱스는 데이터를 효율적으로 탐색하는 방법이다.
MySQL은 인덱스 안에 있는 데이터를 사용할 수 있다.
이를 잘 활용하면 실제 데이터까지 접근할 필요가 없다.
….
커버링 인덱스는 쿼리를 실행하는데 필요한 모든 데이터를 갖는 인덱스를 뜻한다.
SELECT, WHERE, ORDER BY, GROUP BY 등에 사용되는 모든 컬럼이 인덱스의 구성요소인 경우를 뜻한다.
커버링 인덱스는 B-Tree 인덱스를 스캔하는 것만으로 원하는 데이터를 가져올 수 있다.
컬럼을 읽기 위해 디스크에 접근하여 데이터 블록을 읽지 않아도 된다.
다음과 같이 테이블과 인덱스를 만든다.
create table address_svc_m.cover_index
(
id int(11) auto_increment,
sido_name varchar(100),
sgg_name varchar(100),
sido_code varchar(100),
sgg_code varchar(100),
primary key (id)
);
create index cover_index_id_sido_name_sgg_name_index
on address_svc_m.cover_index (id, sido_name, sgg_name);아래와 같이 SELECT SQL을 실행한다.
select id, sido_name, sgg_name
from address_svc_m.cover_index
where sgg_name = '창원시 진해구'SELECT, FROM, WHERE 의 대상이 되는 id, sido_name, sgg_name은 모두 index로 지정한 컬럼이다.
이럴 경우 covering index로 실행된다.
Using Index
커버링 인덱스가 적용되면 실행 계획(EXPLAIN)의 결과 Extra 필드에 Using index가 표시된다.
EXPLAIN
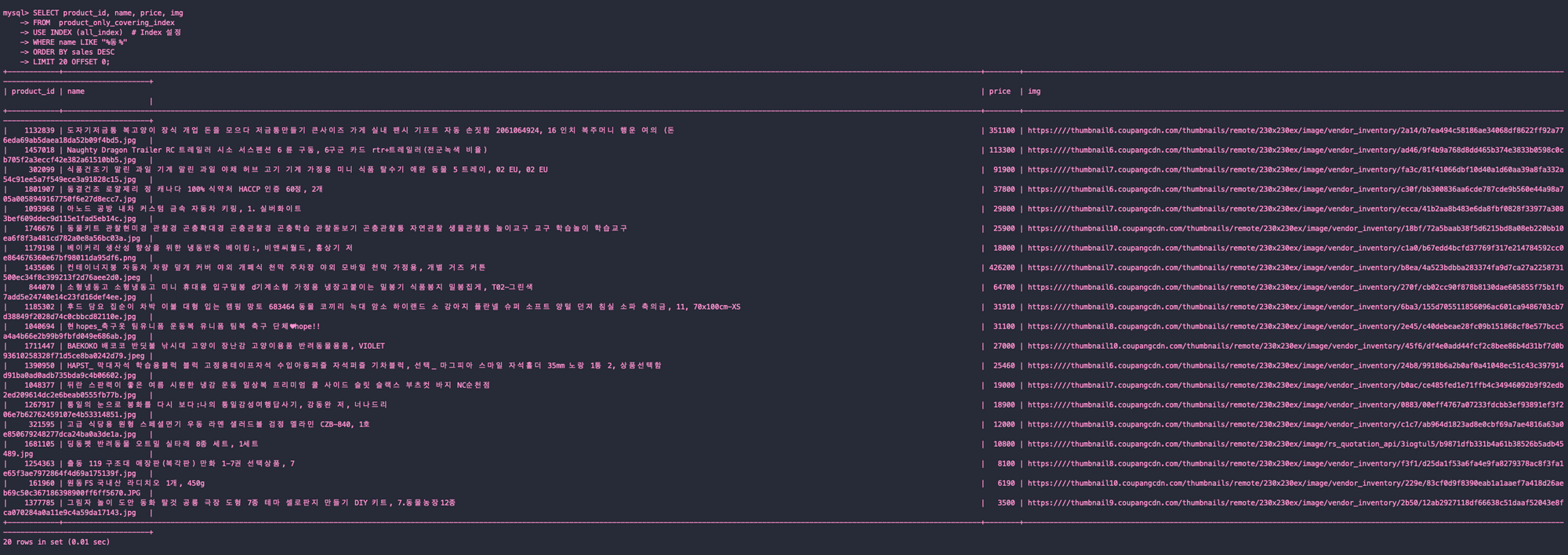
SELECT product_id, name, price, img
FROM product_only_covering_index
WHERE name LIKE "%동%"
ORDER BY price
LIMIT 20 OFFSET 0;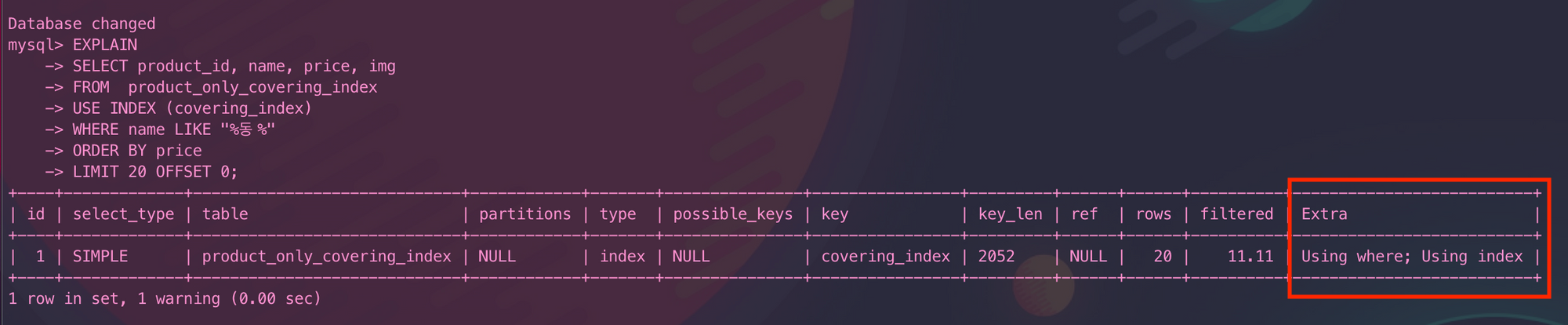
Non Clustered Key, Clustered Key
Clustered Key
대상
- PK
- PK가 없을 땐 유니크 키
- 둘 다 없으면 6byte의 Hidden Key 생성
제한
- 테이블 당 1개만 존재 가능
Non Clustered Key
대상
- 일반적인 인덱스
제한
- 여러개 생성 가능
Non Clustered Key와 Clustered Key를 이용한 데이터 탐색은 다음과 같이 진행된다.
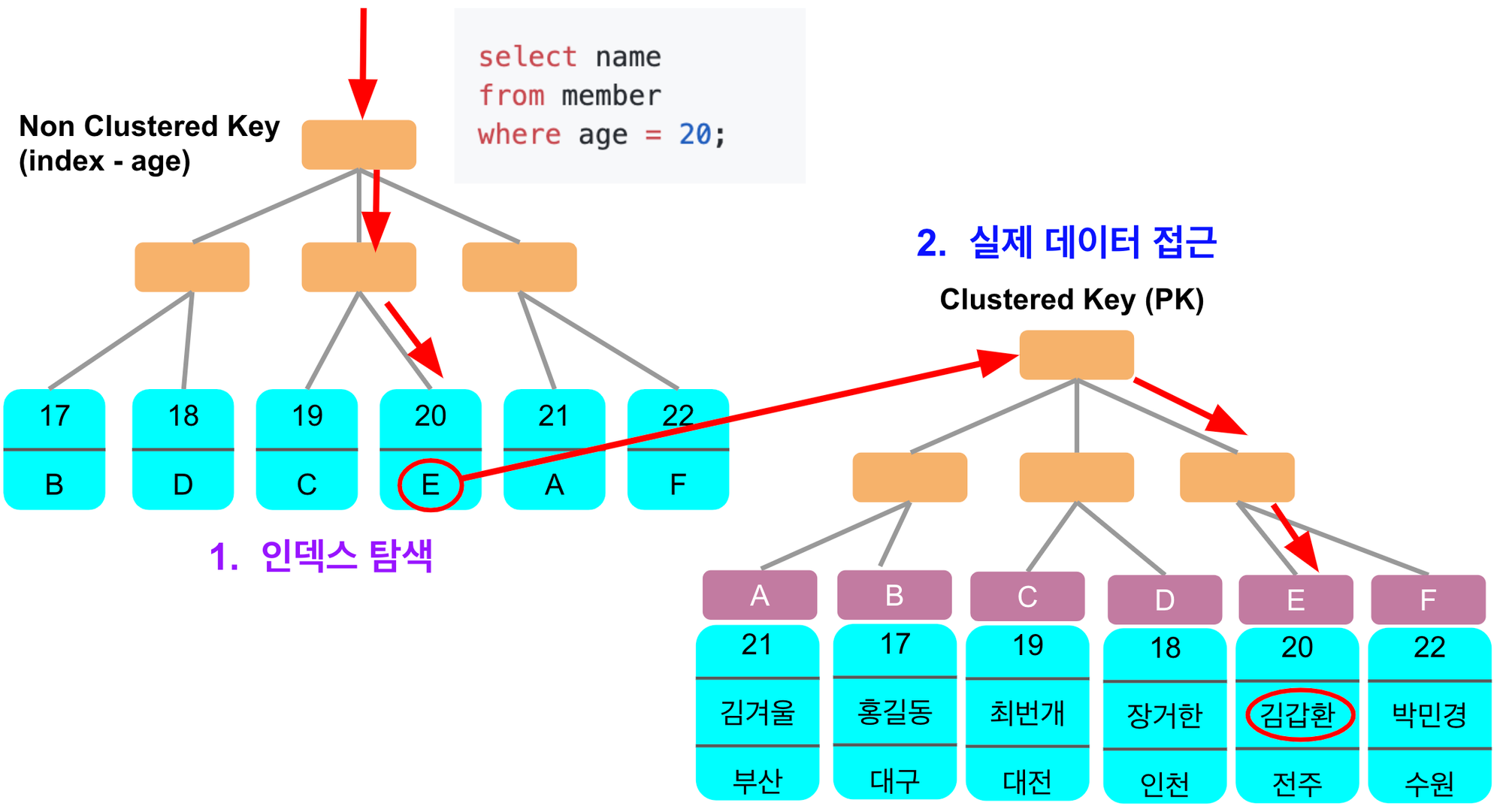
Non Clustered Key에는 인덱스 칼럼의 값들과 PK의 값이 포함된다.
Clustered Key 만이 실제 테이블의 row 위치를 알고 있다.
인덱스 조건에 부합한 where 조건이더라도 select 에 인덱스 이외의 컬럼 값이 필요하면 Clustered Key 값으로 데이터 블록을 찾아야 한다.
커버링 인덱스는 데이터 블록에 접근 없이 인덱스에 있는 컬럼 값들로만 쿼리를 완성하는 것을 말한다.
검색 속도 비교
데이터 수 1,028,222
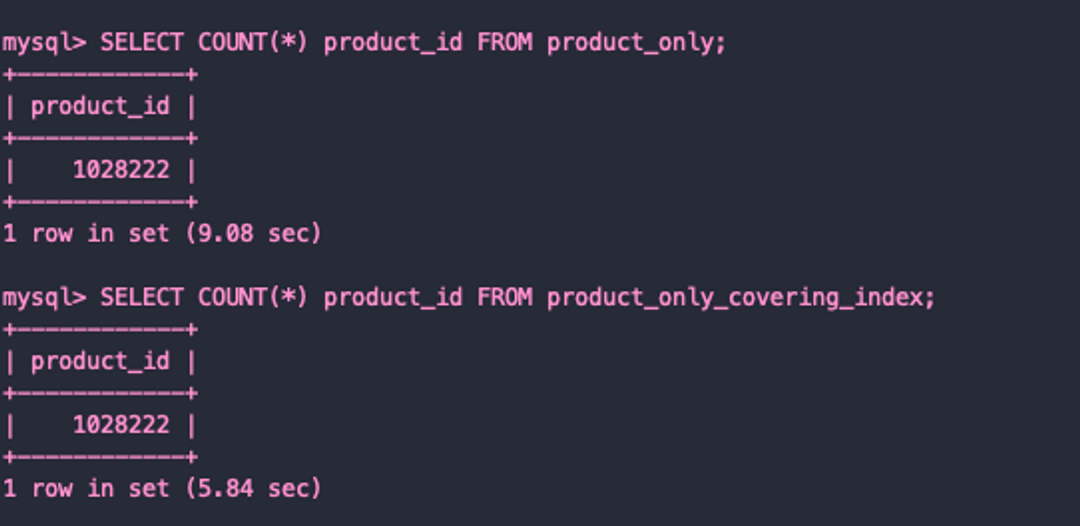
테스트를 실행할 쿼리
SELECT product_id, name, price, img
FROM product_only
WHERE name LIKE "%동%"
ORDER BY price
LIMIT 20 OFFSET 0;prodcut_only_covering_index 테이블에는 다음 쿼리로 인덱스 부여
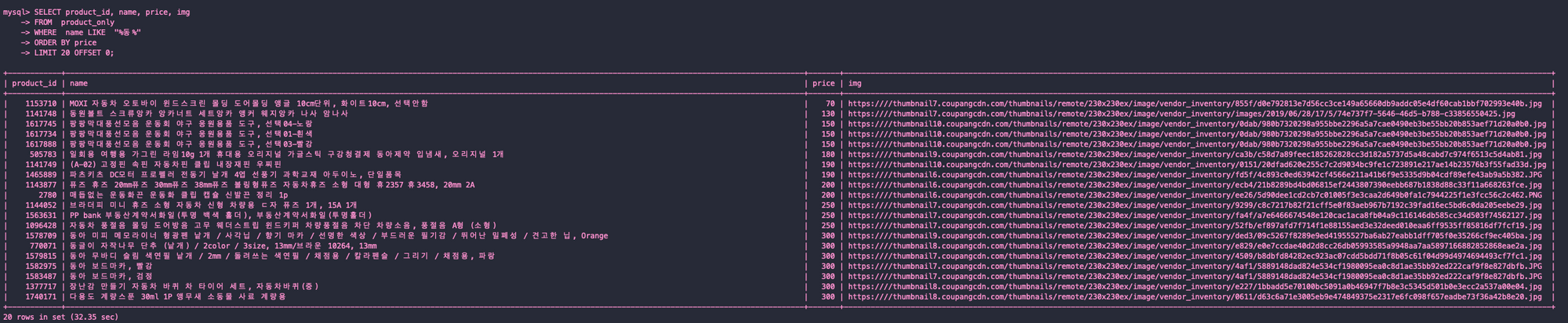
CREATE INDEX covering_index ON product_only_covering_index (price, name, img);일반 검색
인덱스 x

실행 계획
- Using filesort

일반 검색 결과 32.51s
Covering Index
인덱스 부여
- name, price, img

실행 계획
- Using index

Covering index 적용 검색 결과 0.01s
실행 쿼리 변경
현재 정렬 기준 컬럼이 price, sales 이다.
각각 ORDER BY price, ORDER BY sales 쿼리를 실행해야 한다.
위에서 생성한 인덱스 covering_index에는 sales가 없다.
따라서 ORDER BY sales 쿼리를 실행하려면 Covering Index를 사용할 수 없다.
기존 Covering Index에 sales를 추가하면 ORDER BY price, sales 쿼리를 실행해야 하므로 새로운 인덱스를 만들었다.
CREATE INDEX all_index ON product_only_covering_index (sales, price, name, img);
all_index 는 sales 컬럼이 Seq_in_index 값이 1이므로 ORDER BY sales 쿼리를 실행할 수 있다.
이제 쿼리는 다음과 같이 2개로 나뉜다.
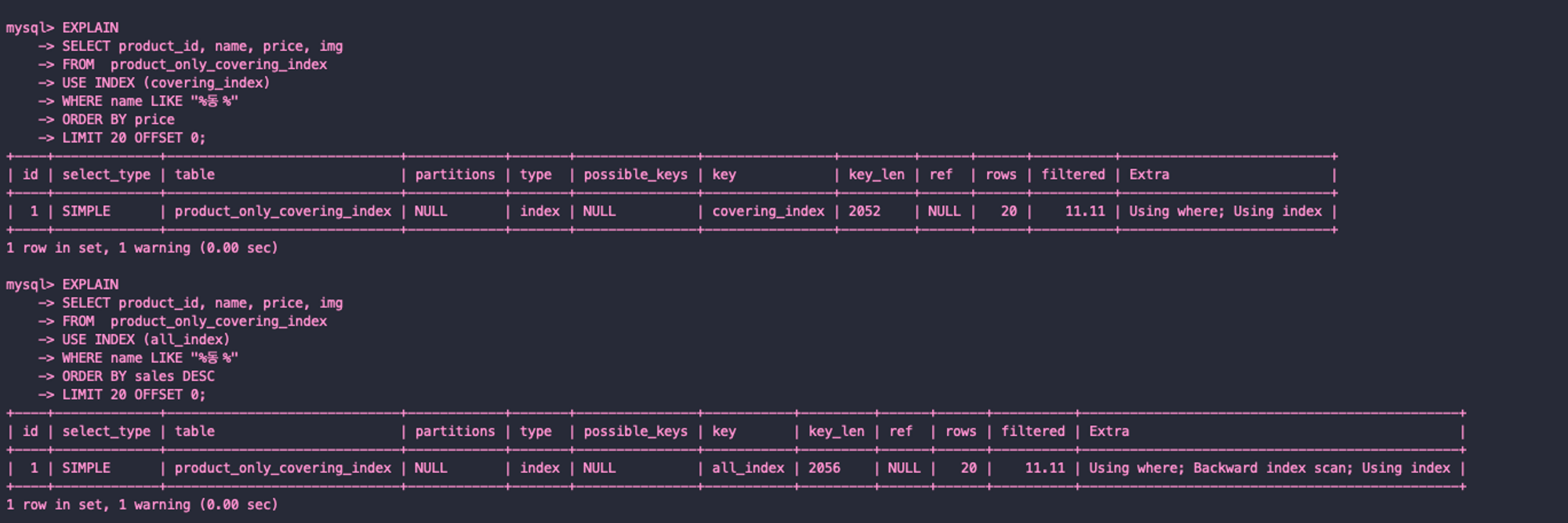
# price 정렬
SELECT product_id, name, price, img
FROM product_only_covering_index
USE INDEX (covering_index) # Index 설정
WHERE name LIKE "%동%"
ORDER BY price
LIMIT 20 OFFSET 0;
# sales 정렬
SELECT product_id, name, price, img
FROM product_only_covering_index
USE INDEX (all_index) # Index 설정
WHERE name LIKE "%동%"
ORDER BY sales DESC
LIMIT 20 OFFSET 0;실행 계획 확인
실행 계획도 Using index로 Covering Index가 적용됨을 확인한다.
실행 결과
price 정렬 0.00 초
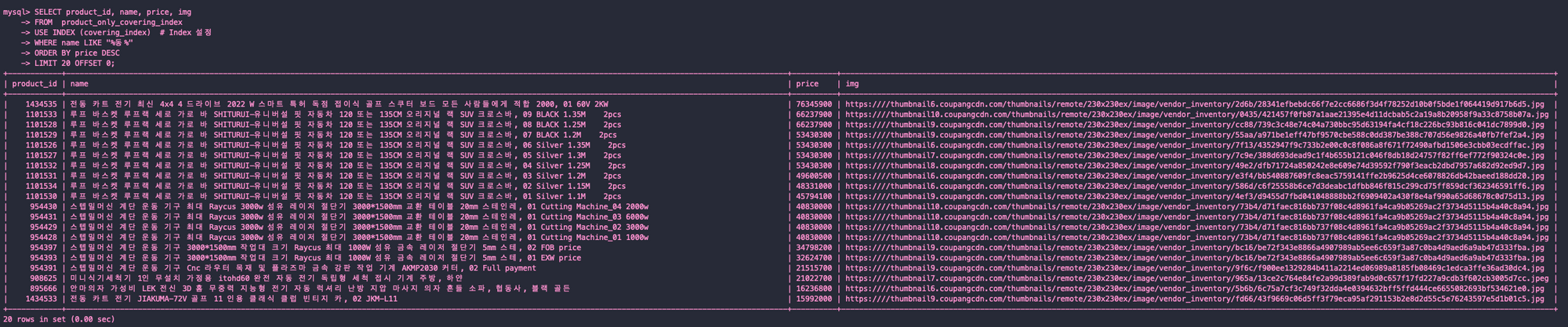
sales 정렬 0.01 초
Querydsl 적용
검색 코드
public List<ProductSimpleResp> searchPageFilter(String q, Pageable pageable) {
List<ProductSimpleResp> results = queryFactory
.select(Projections.constructor(ProductSimpleResp.class,
productCoveringIndex.productId,
productCoveringIndex.productName,
productCoveringIndex.price,
productCoveringIndex.img))
.from(productCoveringIndex)
.where(keywordEq(q))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(productSort(pageable))
.fetch();
return results;
}
private OrderSpecifier<?> productSort(Pageable pageable) {
if (pageable.getSort().isEmpty()) {
return null;
}
for (Sort.Order order : pageable.getSort()) {
Order direction = order.getDirection().isAscending() ? Order.ASC : Order.DESC;
if (order.getProperty().equals("sales")) {
return new OrderSpecifier<>(direction, productCoveringIndex.sales);
} else if (order.getProperty().equals("price")) {
return new OrderSpecifier<>(direction, productCoveringIndex.price);
}
}
return null;
}
private BooleanExpression keywordEq(String keyword) {
return isEmpty(keyword) ? null : productCoveringIndex.productName.contains(keyword);
}%동% 키워드로 검색
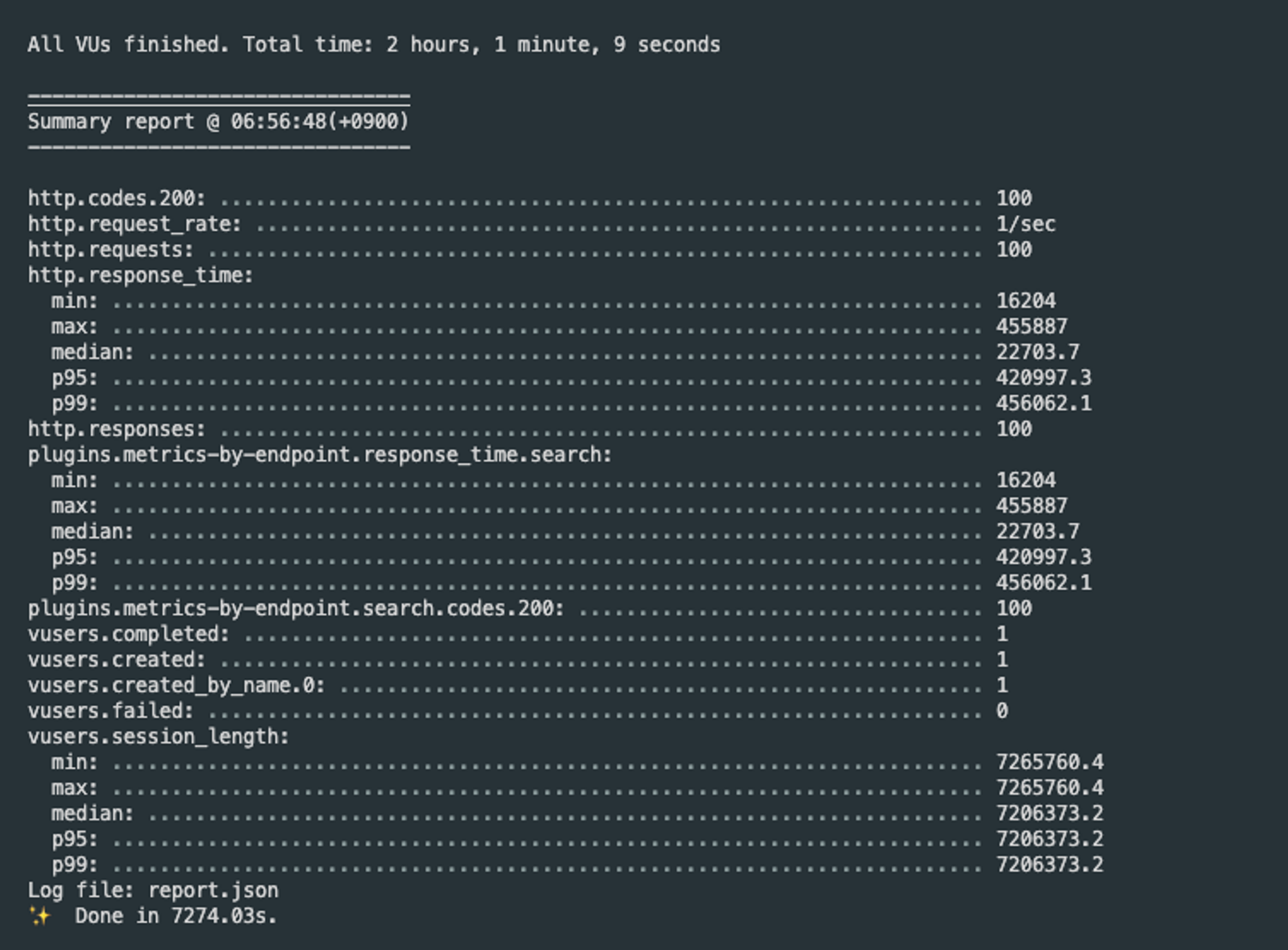
/api/product/list/ci?search=동&page=0&size=20&sort=price,asc포스트맨 요청 5회 결과
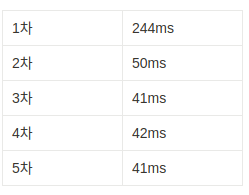
하지만 키워드와 매칭되는 상품데이터가 적을 수록 속도가 느려진다.
-
LIKE
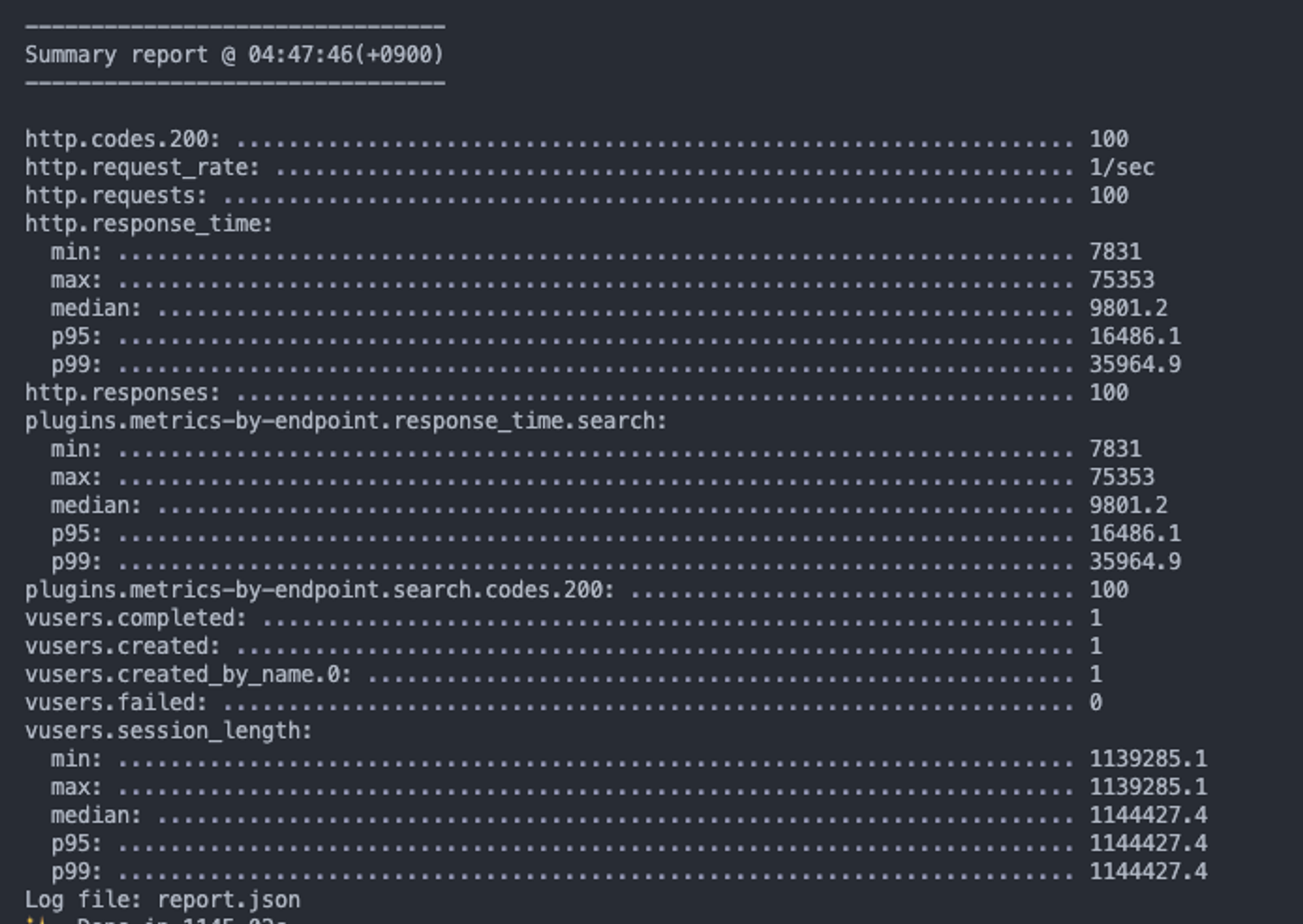
%맥북%: 평균 9초
-
LIKE
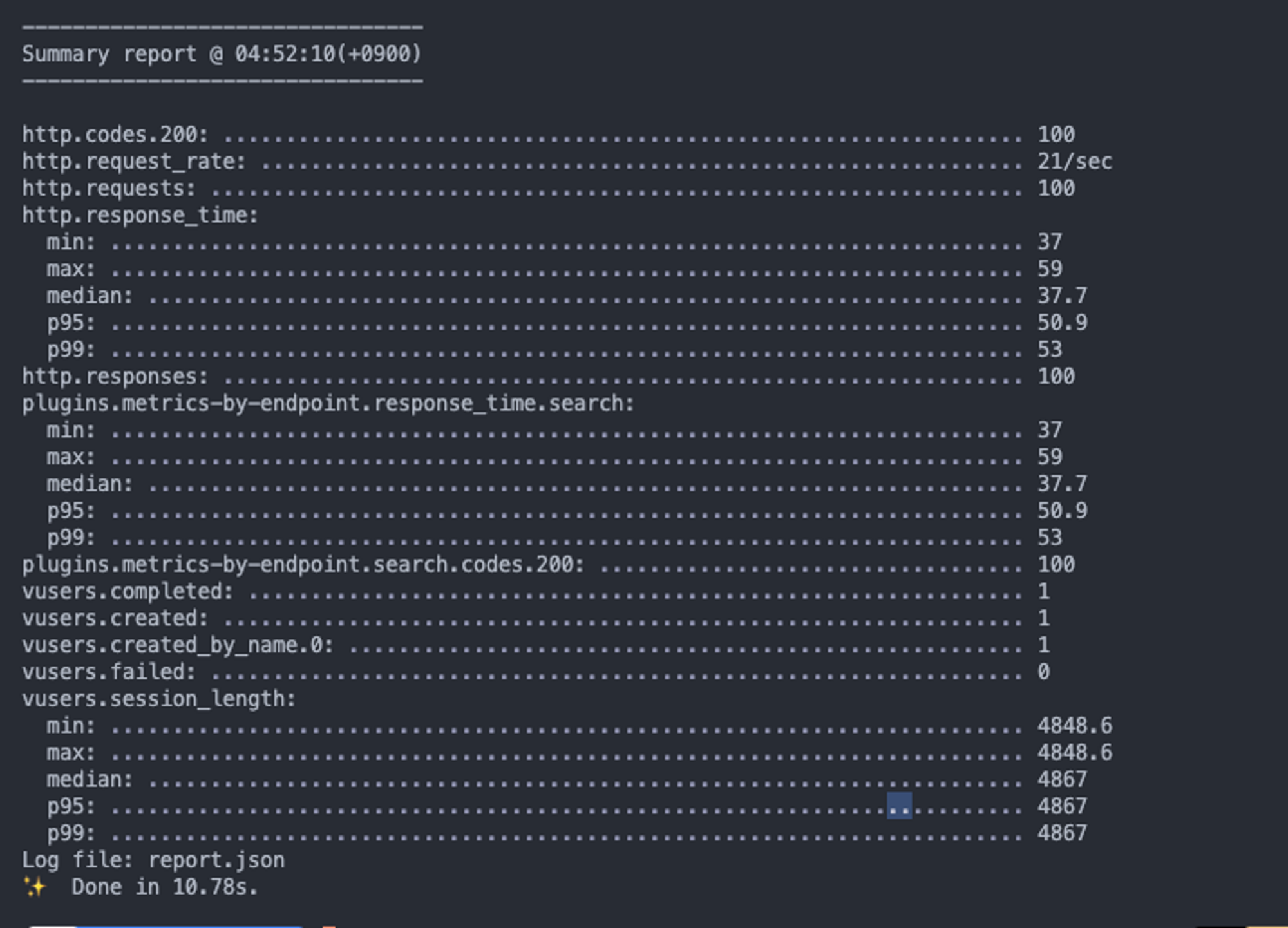
%키보드%: 평균 0.03초
-
LIKE
%잔스포츠 백팩%: 평균 22초
결론
현재 커버링 인덱스 적용은 옳지 않다.
그 이유는 다음과 같다.
1. 본질적인 검색 향상을 위한 상품명 컬럼(name)의 인덱스 문제가 해결된 것이 아니다.
2. 위와 같이 인덱스를 설정한다면, 새로운 검색 조건이 생길 경우 그때마다 새로운 조건의 인덱스를 생성해야 하며 DB를 갈아 엎어야 한다.
3. 아래의 사진 처럼 실행 계획의 type은 index이다.
이는 인덱스를 처음부터 끝까지 읽는 인덱스 풀 스캔을 의미하며, 테이블 풀스캔보다는 빠르나 성능이 좋지 못하다.
또한 이는 현재 검색 결과 데이터가 많은 경우 운이 좋게도 검색 속도가 빠르지만, 검색 결과 데이터가 적은 경우에는 검색 속도가 현저히 느린 현상의 이유이다.

4. 위 처럼 쿼리의 컬럼들을 모두 인덱스로 걸 경우 write(insert, update, delete)시 오히려 성능이 느려져 효율적이지 못하다.
5. 또한 쿼리에 필요한 컬럼들을 모두 인덱스로 거는 것이 아닌, 최소한의 인덱스를 통해 범위를 줄인 후 데이터 블록에 접근하여 인덱스가 아닌 다른 필요한 데이터들을 불러오는 방식을 현업에서는 많이 사용한다고 한다.
-
ex) 위에서
idx(price, name, img)에서 img는 실은 Index로 필요치 않은 컬럼이다.idx(price, name, price, img)에서 또한 price, img는 필요치 않아 제외할 수 있다.idx(price, name),idx(sales, name)인덱스를 통해 범위를 줄인 후 나머지 필요한 데이터를 조회. -
물론 위의 예시 또한 현재 검색 성능을 높이는 우리의 상황에서 좋게 설정된 인덱스(
idx(price, name),idx(sales, name))는 아님을 인지하자!
참고
https://tecoble.techcourse.co.kr/post/2021-10-12-covering-index/
https://jojoldu.tistory.com/476
https://jojoldu.tistory.com/481?category=761883
