서브 쿼리(SUBQUERY)
SELECT문 안에 서브 SELECT문이 하나 더 작성되는 것으로 서브 쿼리만으로는 사용할 수 없다. SELECT문의 위치는 상관 없지만 서브 쿼리는 반드시 소괄호()안에 작성을 해야 한다. 괄호가 없으면 메인 SELECT문이 중복 작성된 것으로 처리돼서 오류가 발생하기 때문이다.
서브 쿼리와 비교할 항복은 반드시 서브 쿼리의 SELECT한 항목의 갯수와 자료형을 일치시켜야 한다.
SELECT문을 두 개 작성해서 조회해야 되는 것들을 하나의 SELECT문을 실행하는 것으로 해결할 수 있다는 장점이 있다. 단, 같은 결과를 내는 상황이라면 JOIN을 사용하는 것이 퍼포먼스적인 부분에서 더 좋다.
--D5부서의 평균 급여보다 많이 받는 사원 조회
SELECT *
FROM EMPLOYEE
WHERE SALARY>=(SELECT AVG(SALARY) FROM EMPLOYEE WHERE DEPT_CODE='D5');단일행 서브 쿼리
서브 쿼리 결과가 1개의 열, 1개의 행인 것으로 메인 쿼리를 실행했을 때가 아닌 것을 주의한다. 컬럼을 작성하거나 WHERE절에 비교 대상 값으로 자주 사용한다.
--사원들의 급여 평균보다 많이 받는 사원의 이름, 급여, 부서코드 조회
SELECT EMP_NAME, SALARY, DEPT_CODE,(SELECT AVG(SALARY) FROM EMPLOYEE) AS AVG
FROM EMPLOYEE
WHERE SALARY>(SELECT AVG(SALARY) FROM EMPLOYEE);
--부서가 총무부인 사원을 조회
SELECT *
FROM EMPLOYEE
WHERE DEPT_CODE=(SELECT DEPT_ID FROM DEPARTMENT WHERE DEPT_TITLE='총무부');
-->메인커리와 서브커리의 TABLE이 같지 않아도 실행 가능하다.다중행 서브 쿼리
서브 쿼리의 결과가 한 개의 열, 다수의 ROW을 갖는다.
--직책이 부장, 과장인 사원을 조회(동등비교)
SELECT*
FROM EMPLOYEE
WHERE JOB_CODE IN(SELECT JOB_CODE FROM JOB WHERE JOB_NAME IN('과장','부장'));
-->다중 ROW를 가져오기 때문에 =으로 비교할 수 없다.💡 하나의 ROW에 다수의 ROW를 연결할 수 없다. 그래서 다중행이 포함된 서브 쿼리는 컬럼에는 사용하지 못하기 때문에 WHERE절, FROM절에 사용해야 한다.
다중행 대소 비교
다중행일 때, 부등호를 사용해서 비교하려고 하면 컴퓨터는 어떤 값을 기준으로 비교해야 하는지 모르기 때문에 기준이 될 값을 지정해줘야 한다.
ANY : OR로 ROW를 연결, 하나라도 TRUE가 된다면 반환.
ALL : 전체가 TRUE일 때 반환하는 것으로 AND로 ROW를 연결했다고 볼 수 있다.
--D5,D6의 월급보다 크거나 같은 사람
SELECT*
FROM EMPLOYEE
WHERE SALARY>=ANY(SELECT SALARY FROM EMPLOYEE WHERE DEPT_CODE IN('D5','D6'));
-->D5, D6 둘 중 하나의 최솟값보다 크기만 하면 전부 출력한다.
--D5, D6의 월급보다 작은 사람
SELECT EMP_NAME, SALARY, DEPT_CODE
FROM EMPLOYEE
WHERE SALARY<ALL(SELECT SALARY FROM EMPLOYEE WHERE DEPT_CODE IN ('D5','D6'));
-->SALARY가 D5, D6의 월급과 모두 비교했을 때 작은 경우를 구하는 것으로 두 값의
--최솟값과 비교한 것과 동일하다.다중열 서브 쿼리
컬럼이 여러 개, ROW가 1개인 서브 쿼리.
--기술지원부이면서 급여가 200만원인 사원의 이름, 부서명, 급여
SELECT EMP_NAME, DEPT_TITLE, SALARY
FROM EMPLOYEE JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
WHERE (DEPT_TITLE, SALARY) IN (SELECT DEPT_TITLE, SALARY
FROM EMPLOYEE JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
WHERE SALARY=2000000 AND DEPT_TITLE='기술지원부');상관 서브 쿼리
서브 쿼리를 구성할 때 메인 쿼리의 값을 가져와서 사용할 수 있도록 설정하는 것이다. 메인 쿼리의 값이 서브 쿼리의 결과에 영향을 주고 서브 쿼리의 결과가 메인 쿼리의 값에 영향을 주기 때문에 데이터가 유동적이다.
--본인이 속한 부서의 사원수를 조회. 사원명, 부서코드, 사원수
SELECT EMP_NAME, DEPT_CODE
,(SELECT COUNT(*) FROM EMPLOYEE WHERE DEPT_CODE=E.DEPT_CODE) AS 사원수
FROM EMPLOYEE E;✅ WHERE절에 상관 서브 쿼리 이용
EXISTS(서브쿼리) : 서브쿼리에 결과가 1행 이상이면 TRUE를 반환, 0행이면 FALSE를 반환한다.
SELECT*
FROM EMPLOYEE E
--WHERE EXISTS(SELECT DEPT_CODE FROM EMPLOYEE WHERE DEPT_CODE='D9');
-->서브쿼리 값이 변화가 없기 때문에 계속 TURE
--매니저인 사원을 조회 ->서브쿼리의 매니저 아이디가 메인쿼리의 사번과 같으면 매니저.
WHERE EXISTS(SELECT 1 FROM EMPLOYEE WHERE MANAGER_ID=E.EMP_ID);
--직급이 J1이 아닌 사원중에서 자신의 부서별 평균 급여보다 급여를 적게 받는 사원 조회
SELECT *
FROM EMPLOYEE E
WHERE JOB_CODE!='J1' AND SALARY<
(SELECT AVG(SALARY) FROM EMPLOYEE WHERE E.DEPT_CODE=DEPT_CODE);✅ FROM절에 상관 서브 쿼리 이용
FROM절에 사용하는 서브 쿼리는 대부분 다중행 다중열 서브 쿼리이다. SELECT문을 이용해서 나온 RESULT SET을 하나의 테이블처럼 사용한다. 이걸 INLINE VIEW라고 한다.
--성별 중 여자만 출력
SELECT *
FROM( --INLINE VIEW. 주민번호로 여자를 구분해서 만든 RESULT SET을 FROM절에서 TABLE처럼 사용
SELECT E.*, DECODE(SUBSTR(EMP_NO,8,1),2,'여자',4,'여자','남자') AS GENDER
FROM EMPLOYEE E
)
WHERE GENDER='여';INLINE VIEW 활용
--부서명이 총무부이고 직급이 부사장인 사원 출력
--**JOIN,집합 연산자 활용**
SELECT*
FROM (
SELECT *
FROM EMPLOYEE LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
JOIN JOB USING(JOB_CODE)
)-->JOIN을 이용해서 여러 테이블의 정보를 하나의 INLINE VIEW로 만들어 테이블로 활용
WHERE DEPT_TITLE='총무부' AND JOB_NAME='부사장';
--사원번호, 부서코드, 직급코드에 1이 포함되면 각각 이름, 부서명, 직급명을 출력
--**집합연산자 이용**
SELECT *
FROM (SELECT EMP_ID AS CODE, EMP_NAME AS TITLE
FROM EMPLOYEE
UNION
SELECT DEPT_ID, DEPT_TITLE
FROM DEPARTMENT
UNION
SELECT JOB_CODE, JOB_NAME
FROM JOB
)
WHERE CODE LIKE '%1%';WITH
SELECT문에 이름을 부여해서 해당 구문이 종료되기 전까지 사용하기 위해서 쓴다. 하나의 별칭 개념으로 같은 서브 쿼리가 여러 번 사용될 경우 중복 작성을 피할 수 있고 실행 속도도 빨라진다는 장점이 있다.
WITH TOPN_SAL AS(SELECT EMP_NAME, SALARY FROM EMPLOYEE
ORDER BY SALARY DESC)
SELECT ROWNUM AS RNUM, EMP_NAME, SALARY
FROM TOPN_SAL; -->WITH로 정한 별칭을 FROM절에 작성 가능하다.
-->세미콜론을 쓴 이후에는 사용할 수 없다.RANK/DENSE_RANK() OVER
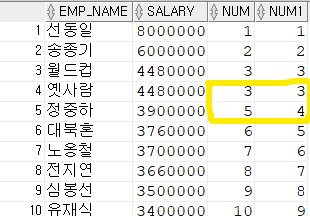
ROW에 순위를 정하고 출력하기 위해 사용한다.
SELECT *
FROM(
SELECT EMP_NAME, SALARY,
RANK() OVER(ORDER BY SALARY DESC) AS NUM,
-->중복값을 같은 수로 처리 후 갯수만큼 번호를 건너뛴다.
DENSE_RANK() OVER(ORDER BY SALARY DESC) AS NUM1
-->DENSE는 중복 값을 같은 수로 처리후 건너뛰지 않고 다음 번호 부여
FROM EMPLOYEE
);
ROWNUM
오라클이 제공하는 가상컬럼으로 ROWNUM 컬럼에 ROW들을 순위 번호를 매겨준다.
--급여를 많이 받는 사원 1~3위 출력
SELECT ROWNUM, E.*
FROM (SELECT * FROM EMPLOYEE ORDER BY SALARY DESC)E
WHERE ROWNUM BETWEEN 1 AND 3;
--ROWNUM은 SELECT문이 실행될때마다 생성된다.
SELECT ROWNUM, T.* --INNERNUM과 ROWNUM은 다른 값을 가진다.
FROM (SELECT ROWNUM AS INNERNUM, E.*
FROM EMPLOYEE E
ORDER BY SALARY DESC)T
WHERE ROWNUM<=3;💡 이 때, ROWNUM은 시작 범위부터 값을 가져올 수 있다. 중간 범위부터는 오라클 내부에서 시작 값을 못 찾기 때문에 값을 불러오지 못한다.
ROWNUM이 구해진 RESULT SET을 하나의 가상 테이블로 불러와서 사용하면 중간 값부터 구할 수 있다. 보통 WEB에서 페이지 단위로 ROW별로 잘라서 사용할 수 있도록 페이징처리 할 때 사용한다.
SELECT *
FROM(
SELECT ROWNUM AS RNUM, E.*
FROM (SELECT * FROM EMPLOYEE ORDER BY SALARY DESC)E)
WHERE RNUM BETWEEN 5 AND 10;