그룹 함수
특정 ROW들의 집합으로 그룹이 형성돼서 적용된다. TABLE에서 나온 집계된 값을 하나의 컬럼으로 반환하기 때문에 다른 컬럼과 함께 조회할 수 없다.
SUM(컬럼) : 테이블의 특정 컬럼에 대한 합을 구한다. 컬럼의 타입은 NUMBER만 가능하다.
AVG(컬럼) : 테이블의 특정 컬럼의 평균을 구한다. 마찬가지로 NUMBER 타입만 가능하다.
COUNT(*||컬럼) : 테이블의 데이터 수를 출력한다.
MIN(컬럼) : 테이블의 특정 컬럼의 최솟값.
MAX(컬럼) : 테이블의 특정 컬럼의 최댓값.
--사원의 월급의 총합계
SELECT TO_CHAR(SUM(SALARY),'FML999,999,999') AS 사원총급여
FROM EMPLOYEE;
--D5부서의 월급 평균
SELECT AVG(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE='D5';
--그룹 함수 끼리는 SELECT문에 함께 작성할 수 있다.
SELECT SUM(BONUS), AVG(BONUS) -->NULL값은 아예 제외 시키고 평균을 구한다.
, AVG(NVL(BONUS,0)) -->NULL값을 0으로 대체 후 평균을 구한다.
FROM EMPLOYEE;
--테이블의 데이터 수 확인
SELECT COUNT(*), COUNT(DEPT_CODE), COUNT(BONUS) --25, 23, 9 출력
FROM EMPLOYEE;💡 NULL은 데이터에서 제외해버린다. *은 ROW의 컬럼 중에 하나라도 값이 있으면 카운트하고 ROW 전체가 NULL인 경우에만 제외한다.
GROUP BY
그룹 함수를 사용했을 때, 특정 기준으로 컬럼 값을 묶어서 처리하는 것이다. 그룹 별로 집계하기 위해 사용하며 GROUP BY에 작성한 기준이 되는 컬럼은 SELECT문에 작성할 수 있게 된다.
WHERE절 아래 [GRUOP BY 컬럼, ...] 구조로 작성한다.
--부서별 급여 합계
SELECT DEPT_CODE, SUM(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE;
--GROUP BY 절에 다수에 컬럼 작성
-->넣은 컬럼을 모두 만족하는 조건의 합계를 구한다.
SELECT DEPT_CODE, JOB_CODE, COUNT(*)
FROM EMPLOYEE
GROUP BY DEPT_CODE, JOB_CODE;
--부서별 인원이 3명 이상인 부서만 출력
SELECT DEPT_CODE, COUNT(*)
FROM EMPLOYEE
--WHERE COUNT(*)>=3
GROUP BY DEPT_CODE
HAVING COUNT(*)>=3;💡 HAVING?
쿼리의 실행 순서가 FROM→WHERE→SELECT→GROUP BY 이므로 그룹 함수에 조건을 달고 싶어도 WHERE절에 작성할 수 없다. 조건을 달고 싶을 때, HAVING절 사용한다.
- GROUP BY를 이용해서 주민번호로 남,여 구분
--남자, 여자의 급여 평균 및 인원수 출력 SELECT DECODE(SUBSTR(EMP_NO,8,1),'1','남','3','남','2','여','4','여') AS 남녀구분 , AVG(SALARY), COUNT(*) FROM EMPLOYEE GROUP BY DECODE(SUBSTR(EMP_NO,8,1),'1','남','3','남','2','여','4','여'); --GROUP BY에서도 구분을 나눠주어야 하나의 남,여 그룹으로 묶여서 출력된다.
그룹별 집계와 총 집계를 한 번에 출력해주는 함수
ROLLUP() : 마지막에 총 집계 출력한다. 두 개 이상의 인수를 전달했을 때, 1. 두 개 컬럼을 집계, 2. 첫번째 인수 컬럼의 소계, 3. 전체 총계. 총 3가지로 나뉘어서 집계된 값을 RESULT SET에 보여준다.
CUBE() : 맨 위에 총 집계 출력한다. 두 개 이상의 인수를 전달했을 때, 1. 두 개 컬럼의 집계, 2. 첫번째 인수 컬럼 소계, 3. 두번째 인수 컬럼 소계, 4. 전체 총계. 총 4가지 경우로 나뉘어서 집계가 되는데 그 이상의 인수를 추가해도 컬럼 소계를 구할 수 있는 경우의 수만큼 집계해서 출력한다.
--부서별 급여 합계와 총 합계를 조회
SELECT DEPT_CODE, SUM(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY ROLLUP(DEPT_CODE); --||GROUP BY CUBE(DEPT_CODE);
--2개 이상의 컬럼 집계
SELECT DEPT_CODE, JOB_CODE, SUM(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY ROLLUP(DEPT_CODE, JOB_CODE);
SELECT DEPT_CODE, JOB_CODE, SUM(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY CUBE(DEPT_CODE, JOB_CODE);GROUPING
GROUPING함수를 이용하면 집계 결과를 분기 처리해서 출력할 수 있다. ROLLUP, CUBE로 집계한 로우에 대해 분기 처리한다. 문자열(컬럼값)이 NULL이 된 얘들을 기준으로 집계된 로우는 1을 반환하고 아니면 0을 반환한다.
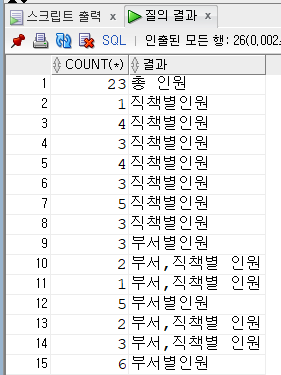
SELECT COUNT(*)
,CASE
WHEN GROUPING(DEPT_CODE)=0 AND GROUPING(JOB_CODE)=1 THEN '부서별인원'
WHEN GROUPING(DEPT_CODE)=1 AND GROUPING(JOB_CODE)=0 THEN '직책별인원'
WHEN GROUPING(DEPT_CODE)=0 AND GROUPING(JOB_CODE)=0 THEN '부서,직책별 인원'
WHEN GROUPING(DEPT_CODE)=1 AND GROUPING(JOB_CODE)=1 THEN '총 인원'
END AS 결과
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY CUBE(DEPT_CODE, JOB_CODE);위 쿼리를 실행하면 해당 RESULT SET이 나온다.
ORDER BY
테이블에서 조회한 데이터를 정렬하는 기능을 한다 . GROUP BY절 뒤에 [ORDER BY 컬럼명 [정렬방식(DESC,ASC)]] 형태로 작성하고 정렬 방식은 ASC(오름차순)이 기본 값으로 생략 가능하다.
--부서코드를 기준으로 오름차순으로 정렬, 값이 같으면 월급이 높은 순으로 정렬
SELECT *
FROM EMPLOYEE
ORDER BY DEPT_CODE ASC, SALARY DESC, EMP_NAME ASC;
--보너스를 내림차순으로 출력하되 NULL값은 맨 아래로 정렬
SELECT *
FROM EMPLOYEE
ORDER BY BONUS DESC NULLS LAST;
--ORDER BY 구문에서는 별칭을 사용할 수 있다.
SELECT EMP_NAME, SALARY AS 월급, BONUS
FROM EMPLOYEE
--실행 순서가 FROM->SELECT->WHERE->ORDER BY 순서기 때문에 별칭 사용 가능
ORDER BY 월급;💡 DESC은 NULL값을 먼저 출력하고 ASC는 NULL값이 나중에 출력 된다. DESC NULLS LAST, ASC NULLS FIRST를 사용해서 NULL값의 순서를 지정해줄 수 있다.
SELECT문을 사용해서 RESULT SET에 출력할 땐 자동으로 각 컬럼에 인덱스 번호가 부여된다. 첫 번째 컬럼에 1부터 인덱스 번호가 부여되고 해당 인덱스 번호를 사용해서 정렬 가능하다. ORDER BY 1; 처럼 사용할 수 있다.
GROUPING SETS
여러 GROUP BY절이 있는 구문을 하나로 작성하게 해주는 기능이다.
SELECT DEPT_CODE, JOB_CODE, MANAGER_ID, AVG(SALARY)
FROM EMPLOYEE
GROUP BY GROUPING SETS((DEPT_CODE, JOB_CODE, MANAGER_ID)
, (DEPT_CODE, JOB_CODE), (DEPT_CODE, MANAGER_ID));집합 연산자
여러 개의 SELECT문을 하나의 RESULT SET으로 출력해주는 것으로 사용하기 위해서는 두 가지 조건이 존재한다. 첫 번째 SELECT문의 컬럼 수과 이후 SELECT문의 컬럼 수가 같아야 한다는 것과 각 컬럼별 데이터 타입이 동일해야 한다.
UNION : 두 개 이상의 SELECT문을 합치는 연산자. 중복 값은 하나만 출력한다.
UNION ALL : 중복 값을 포함해서 전부 출력한다.
MINUS : 중복 값을 아예 제외하고 출력한다.
INTERSECT : 중복 값만 출력한다.
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE='D5'
UNION
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY>=3000000;
--다른 테이블의 데이터를 합치기
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
UNION
SELECT DEPT_ID, DEPT_TITLE
FROM DEPARTMENT;💡 만약 두 SELECT문의 컬럼 수가 다르거나 컬럼의 데이터 타입이 달라지면 오류가 발생한다.
⚠️ORA-01789: 질의 블록은 부정확한 수의 결과 열을 가지고 있습니다.
⚠️ORA-01790: 대응하는 식과 같은 데이터 유형이어야 합니다.
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE='D5'
UNION
SELECT EMP_ID, EMP_NAME, EMP_NO --데이터 타입 오류
--SELECT EMP_ID, EMP_NAME 까지 작성했을 경우 컬럼 수 부정확 오류
FROM EMPLOYEE
WHERE SALARY>=3000000;