강의 유튜브 : 토비의 봄 TV - 스프링 리액티브 프로그래밍
1강 (Reactive Streams)
1. 개요
리액티브 프로그래밍의 표준 사양인 리액티브 스트림즈의 기본 개념을 정리하고, 기존 디자인 패턴과의 비교를 통해 그 특징과 한계를 분석한다.
2. 데이터 흐름 및 언어적 기초
2.1 데이터 흐름의 방향성
- 업스트림(Upstream): 데이터가 위에서 아래로 흐르는 방향 또는 그 상위 단계를 의미한다.
- 다운스트림(Downstream): 데이터가 아래에서 위로 흐르는 방향 또는 그 하위 단계를 의미한다.
2.2 자바 제네릭(Generic) 활용
- 제네릭 메서드 선언 시, 타입 파라미터는 함수의 리턴 타입 왼쪽에 명시하여 해당 메서드 내에서 사용할 타입을 정의한다.
3. 데이터 처리 모델 비교: Pull vs Push
3.1 Pull 방식 (Iterable)
- 특징: 데이터를 사용하는 측에서 필요한 시점에 직접 값을 꺼내오는(순회하는) 방식이다.
- 구현: Java의
Iterable,Iterator가 대표적인 예시이다.
3.2 Push 방식 (Observer Pattern)
- 특징: 데이터 제공자가 데이터가 준비되었을 때 사용(구독)자에게 밀어넣어 주는 방식이다.
- 공통점: 두 방식 모두 '데이터의 요청과 제공'이라는 목적은 동일하나, 주도권의 위치가 다르다.
4. 옵저버 패턴을 활용한 비동기 구현의 한계
옵저버 패턴을 통해 비동기 패턴을 구현할 경우, 다음과 같은 설계상의 단점이 존재한다.
- 종료 시점 명시 불가: 데이터 스트림이 언제 끝나는지에 대한 표준적인 종료 시그널이 없어, 작업 완료를 알리기 어렵다.
- 에러 핸들링 부재: 데이터 전달 과정에서 에러가 발생했을 때 이를 전달받는 방식이나, 에러 발생 후의 복구 및 처리(Handling)에 대한 표준화된 규격이 부족하다.
5. 시사점
Reactive Streams는 기존 옵저버 패턴이 가진 종료와 에러 처리의 한계를 극복하기 위해 제안되었다. 이를 통해 비동기 데이터 흐름을 보다 안전하고 표준화된 방식으로 관리할 수 있는 기반을 제공한다.
2강 (Operators)
Project Reactor 연산자 및 Spring 프레임워크 연동 분석
1. Project Reactor: Flux의 핵심 연산자 분석
Project Reactor에서 제공하는 연산자(Operator)는 데이터 스트림을 가공하고 모니터링하는 핵심적인 역할을 수행한다.
1.1 log(): 스트림 흐름의 투명성 확보
- 기능: Publisher(발행자)와 Subscriber(구독자) 사이에서 교환되는 요청 정보 및 신호를 로그로 기록한다.
- 의의: 데이터 흐름의 각 단계에서 발생하는 시그널을 시각화하여 디버깅 및 흐름 파악을 용이하게 한다.
1.2 map(): 데이터 변환(Transformation)
- 기능: 스트림을 통해 전달되는 데이터에 특정 함수를 적용(Apply)하여 가공한다.
- 구조적 특징: 데이터를 받아 변환 후 다음 단계로 넘겨주는 '중간 구독자(Intermediate Subscriber)'이자 '중간 연산자'로서의 역할을 수행한다.
1.3 reduce(): 데이터 집계 및 누적(Aggregation)
- 기능: 데이터 흐름의 각 단계 결과를 누적하고, 그 결과값에 지속적으로 함수를 적용하여 하나의 최종값을 산출한다.
2. 연산자의 정체성과 특이 동작
2.1 연산자의 본질: 중간 구독자(Intermediate Subscriber)
- Flux에서 제공하는 다양한 오퍼레이터들은 원본 데이터를 특정 목적에 맞게 가공하기 위한 '중간 구독자'의 성격을 띤다. 이는 데이터 소스로부터 최종 소비자까지 이어지는 파이프라인의 구성 요소가 된다.
2.2 시그널 제어의 특이성
- cancel 호출 흐름: 일반적인 스트림은
onNext이후onComplete로 종료되지만, 특정 연산자나 상황에서는onNext이후 즉시cancel을 호출하는 독특한 메커니즘이 존재한다. 이는 구독 측에서 조기에 흐름을 제어하는 리액티브 스트림의 특성 중 하나다.
3. Spring 프레임워크에서의 Reactor 활용
3.1 컨트롤러 계층의 구현
- Publisher 반환: Spring Rest Controller의 엔드포인트 메서드에서 최종 가공된
Publisher(Flux 또는 Mono)를 직접 리턴하는 방식을 취한다.
3.2 프레임워크의 역할 (Spring MVC/WebFlux)
- 구독(Subscription) 자동화: 개발자가 직접
subscribe()를 호출할 필요가 없다. 리턴된Publisher가 어떤Subscriber를 통해 실행될지는 Spring 프레임워크가 내부적으로 판단하고 처리한다.
3.3 데이터 처리 파이프라인의 구조
- 데이터 흐름의 경계: 퍼블리셔가 시스템의 경계(Endpoint)에 위치하며, 백엔드 로직에서 여러 단계의 서브스크라이버(오퍼레이터)를 거치며 데이터를 가공한다.
- 최종 결과 제공: 가공이 완료된 최종 형태의 퍼블리셔가 클라이언트에게 제공됨으로써 비동기 데이터 전달이 완성된다.
3강 (Schedulers)
Reactive Streams의 스케줄링 및 스레드 관리 메커니즘 분석
1. 스레드 풀 관리와 ExecutorService
리액티브 환경에서 효율적인 리소스 관리를 위해 스레드 풀의 개념을 정확히 이해하는 것이 중요하다.
- ExecutorService: 정해진 개수의 스레드를 유지하며, 처리 용량을 초과하는 요청은 큐(Queue)에 대기시키는 스레드 풀 시스템이다. 이를 통해 불필요한 스레드 생성을 막고 리소스 낭비를 완화한다.
- 스레드 명명:
ThreadFactory를 사용하여 스레드 이름을 지정할 수 있으며, 스프링 등에서 제공하는CustomizableThreadFactory를 쓰면 더욱 간편하게 설정 가능하다. - 종료(Shutdown) 전략:
- shutdown(): 현재 진행 중인 작업을 모두 마친 후 우아하게(Graceful) 종료한다.
- shutdownNow(): 대기 중인 작업을 취소하고 실행 중인 스레드에 인터럽트를 걸어 즉시 강제 종료한다.
2. Reactor 스케줄러: subscribeOn과 publishOn
데이터 흐름의 병목 현상을 해결하기 위해 적절한 지점에 스케줄러를 배치해야 한다.
- subscribeOn: 퍼블리셔가 느리고 서브스크라이버가 빠를 때 사용한다. 구독 시점부터 퍼블리셔의 동작을 별도의 스레드에서 수행하도록 한다.
- publishOn: 퍼블리셔는 빠르지만 서브스크라이버의 처리 속도가 느릴 때 사용한다. 이후에 오는 서브스크라이버 및 오퍼레이터의 동작을 별도의 스레드에서 수행하게 한다.
- 구조 최적화: 퍼블리셔, 서브스크라이버, 각각의 오퍼레이터가 상황에 맞는 최적의 스케줄러를 타게 설계하여 처리율(Throughput)은 높이고 지연 시간(Latency)은 낮추는 것이 리액티브 프로그래밍의 핵심 역량이다.
3. Flux의 동작 및 구독 메커니즘
- 간편한 구독:
subscribe()호출 시 서브스크라이버 객체 전체를 구현하지 않고 메서드 레퍼런스나 람다식 하나만 전달하면, 내부적으로onNext신호만 처리하는 서브스크라이버가 생성된다. - 자체 스레드 운영:
subscribeOn을 명시하지 않아도 별도의 스레드에서 동작하는 퍼블리셔들이 존재한다. 대표적으로Flux.interval()이 있다.
4. JVM 스레드 생명주기: 유저 스레드와 데몬 스레드
- 유저 스레드(User Thread): 상위 스레드(메인 스레드 등)가 종료되어도 자신의 작업이 끝날 때까지 프로세스를 유지한다.
- 데몬 스레드(Daemon Thread):
Flux.interval()등이 생성하는 스레드로, 유저 스레드가 하나도 남지 않으면 JVM에 의해 강제 종료된다. 따라서 메인 스레드가 즉시 종료되는 환경에서는Thread.sleep()등으로 대기 시간을 주어야 데몬 스레드의 동작을 확인할 수 있다.
5. 오퍼레이터의 역할 및 흐름 제어
- 오퍼레이터의 기능: 데이터의 중간 변환, 스케줄링 적용, 그리고 퍼블리싱 자체를 컨트롤(예:
take(n)을 통한 데이터 개수 제한)하는 역할을 한다. - take(n): 지정된 n개의 데이터만 수신한 후 스트림을 종료한다.
- cancel: 서브스크라이버 스펙 중 하나로, 원하는 시점에 더 이상 데이터를 받지 않겠다고 선언하며 구독을 해지하는 메커니즘이다.
- 기타 도구:
Executors.newSingleThreadScheduledExecutor를 통해 주기적인 작업을 수행하는 스레드를 효율적으로 생성할 수 있으며, 가시성 문제를 위해volatile키워드 등의 자바 동시성 개념이 활용되기도 한다. - 참고 : volatile의 특성
- CPU 캐시가 아닌 메인 메모리에 올려두고 읽기/쓰기
- 여러 스레드들에 대한 가시성 확보
- 내 의도와 다르게 컴파일러가 최적화해버리는거 방지
6. 결론
Reactive Streams의 성능을 극대화하기 위해서는 스케줄러를 통한 스레드 분리 전략이 필수적이다. 특히 각 단계에서 발생하는 데이터 속도 차이를 고려하여 subscribeOn과 publishOn을 적재적소에 배치하는 설계 능력이 고수와 하수를 가르는 기준이 된다.
4강 (자바와 스프링의 비동기 기술)
자바 및 스프링 비동기 기술의 변천과 핵심 메커니즘
1. 자바 비동기의 기초: Future 인터페이스
1.1 Future의 개념과 제어
- 정의: 자바 비동기 작업의 결과를 나타내는 가장 기본적인 인터페이스다.
- 실행 메커니즘:
ExecutorService에서 스레드 결과를 부모 스레드로 전달받으려면execute()대신submit()을 사용해야 한다.submit()은 작업 완료 후 결과를 핸들링할 수 있는Future타입의 변수를 반환한다. - 동작 방식:
- Blocking:
Future.get()호출 시 결과가 나올 때까지 다음 인스트럭션을 진행하지 않고 대기한다. - Non-blocking: 결과가 결정되지 않았을 때
null을 반환하고 즉시 다음 라인으로 넘어가 실행을 지속하는 방식이다. (isDone()등을 통해 상태 확인 가능)
- Blocking:
1.2 Callable과 Runnable
- Runnable: 실행은 가능하나 결과값을 리턴할 수 없고, 예외 발생 시 외부로 던져 처리를 위임하는 기능이 부족하다.
- Callable: Runnable과 달리 값을 리턴할 수 있으며, 발생한 예외를 호출 측으로 넘겨 처리를 위임할 수 있다.
1.3 FutureTask와 Callback
- FutureTask: 비동기 작업 로직과 결과 데이터를 동시에 담고 있는 객체다.
- 오버라이딩:
new키워드로 객체를 생성할 때 뒤에 블록을 열어done()메서드를 오버라이딩하면, 부모 스레드에 결과를 넘기지 않고도 자식 스레드 내에서 비동기 작업 후속 로직을 직접 처리할 수 있다. - Callback:
CallbackFutureTask등을 구현하여 작업 완료 시점에 실행될 후크(Hook) 함수를 넘겨주는 방식이다. 예외 발생 시try-catch보다 에러 처리 콜백을 넘기는 것이 훨씬 우아(Graceful)한 방식이다.
2. 스프링 프레임워크의 비동기 기술 (전통적 방식)
2.1 @Async와 설정
- 구현: 비동기 메서드에
@Async를 붙이고AsyncResult<>(value)를 반환한다. 이를 위해 설정 클래스에@EnableAsync를 붙여 스프링 컨테이너에 알려야 한다. (AOP 기반 동작) - 실행 시점: 스프링 컨텍스트 로딩 직후 어떠한 로직을 수행시키고 싶다면
ApplicationRunner를 구현한 빈을 등록하면 된다.
2.2 ThreadPoolTaskExecutor 관리 전략 (필수 설정)
- 스레드 풀 할당 순서:
- CorePoolSize: 최초 요청 시 설정된 개수만큼 스레드를 생성한다. (런타임에 수정 가능)
- QueueCapacity: 코어 스레드가 가득 차면 큐 용량만큼 작업을 대기시킨다.
- MaxPoolSize: 큐까지 가득 차야 비로소 스레드 개수를 확장한다. (설정 안 하면 큐가 찼을 때 예외 발생)
- 주의사항:
@Async의 기본값인SimpleAsyncTaskExecutor는 요청마다 스레드를 새로 만드므로 실무에선 반드시ThreadPoolTaskExecutor를 빈으로 등록하고initialize()를 호출해 사용해야 한다.
3. IO 모델 및 서블릿 비동기
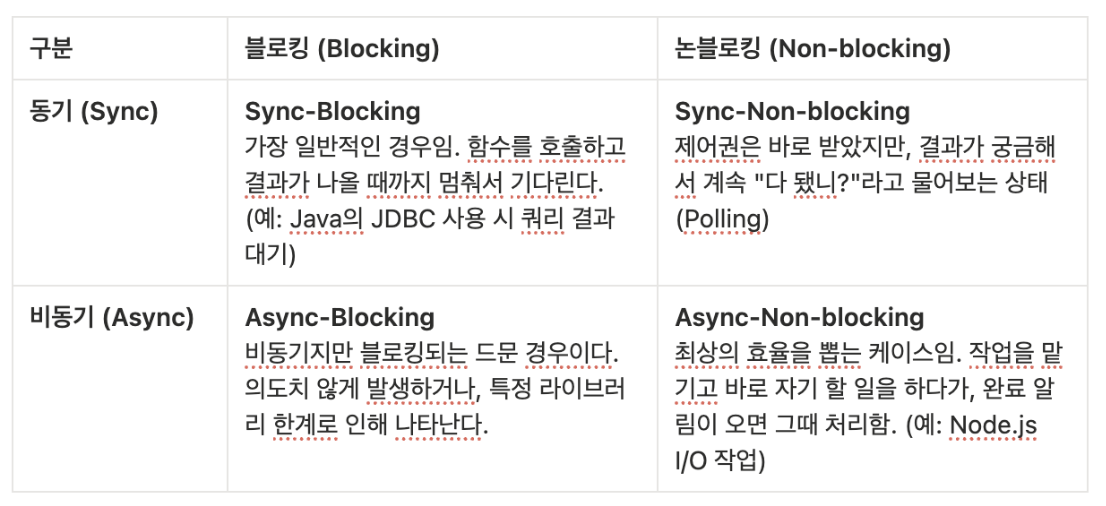
3.1 블로킹(Blocking) vs 논블로킹(Non-blocking) IO
- Blocking IO: IO 작업 시 스레드를 점유하며 데이터가 올 때까지 대기한다. 자바의
InputStream/OutputStream이 대표적이다. - Non-blocking IO: 서블릿 3.1부터 지원하며, 읽기/쓰기 시 스레드를 점유하지 않고 이벤트 기반으로 처리한다.
3.2 서블릿 비동기 기술 메커니즘 (NIO)
- 동작 원리: NIO 커넥터가 요청을 받아 서블릿 스레드를 할당한다. 작업이 오래 걸려 비동기로 넘기면, 작업 스레드(Worker)로 처리를 위임하고 서블릿 스레드는 즉시 반납된다. 처리가 완료되면 다시 서블릿 스레드를 할당받아
AsyncContext를 넘기고 최종 응답을 보낸 후 반납한다. - Callable 리턴: 컨트롤러에서
Callable로 감싸서 리턴하면 워커 스레드가 작업을 대신 수행하여 서블릿 스레드 풀의 처리율을 높인다. - DeferredResult: '스프링 비동기 기술의 꽃'. 특정 이벤트가 발생할 때까지 응답을 지연시켰다가 나중에 처리한다. 채팅방 구현이나 외부 API 대기 시 유용하며 내부적으로
ConcurrentLinkedQueue등을 사용한다. - ResponseBodyEmitter & SSE: 하나의 요청에 대해 응답을 여러 번 쪼개 보내는 스트리밍 방식이다. 브라우저가 이를 실시간으로 받아 화면에 렌더링할 수 있다.
4. 유틸리티 및 소소한 지식
- 자바 동시성:
AtomicInteger(원자성 보장),volatile(가시성 보장),awaitTermination(셧다운 후 나머지 스레드 종료 대기). - 예외 처리:
InterruptedException은 고의적인 중단 신호이므로Thread.currentThread().interrupt()로 플래그를 세워주는 것이 정석이다. - 스프링 유틸:
StopWatch로 시간을 측정하고,Objects.requireNonNull(param)으로 null 체크와 동시에 NPE를 던져 에러 위치를 명확히 한다. - 인프라 지식: 톰캣의 기본 Max 스레드는 200개이며,
JVisualVM툴을 통해 스레드 상태를 시각적으로 모니터링할 수 있다. - 함수형 프로그래밍: 클래스에 메서드가 하나뿐이라면 람다식이나 메서드 레퍼런스를 사용하여 코드를 간결하게 작성할 수 있다.
5. 결론 및 한계점
과거 비동기 방식은 비즈니스 로직과 비동기 제어 로직이 혼재되어 유지보수가 어려웠다. 이를 해결하기 위해 ListenableFuture(Spring 4.0), CompletableFuture(Java 8) 등이 등장했으며, 이는 현재의 리액티브 프로그래밍(Project Reactor)으로 진화하는 중요한 밑거름이 되었다.
5강 (비동기 RestTemplate과 비동기 MVC/Servlet)
비동기 RestTemplate과 서블릿 스레드 최적화 분석
1. 스레드 동기화 및 테스트 도구
1.1 CyclicBarrier: 스레드 동기화 제어
- 기능: 여러 스레드를 생성한 뒤, 특정 시점에 모든 스레드가 준비될 때까지 기다렸다가 "동시에" 실행시키고 싶을 때 사용한다.
- 메커니즘: 각 스레드에서
await()을 호출하면 블락(Block) 상태가 되며, 이 숫자가 지정한 수치에 도달하는 순간 모든 스레드의 블락이 풀리며 동시에 동작을 시작한다.
1.2 모니터링 및 테스트 환경 설정
- Java Mission Control (JMC): Oracle JDK에 번들로 포함된 강력한 툴이지만, 라이선스 문제로 인해 상업적 이용 시 주의가 필요하다.
- 로컬 멀티 톰캣 테스트: 한 PC에서 여러 톰캣을 띄워 테스트할 때는
System.setProperty()를 통해 서버 포트와 Max 스레드 개수 등을 오버라이드하여 설정할 수 있다.
2. 외부 API 호출의 비동기/논블로킹 진화
2.1 기존 방식의 한계 (Blocking)
- 외부 API 호출 시 응답이 지연(예: 2초)되면, 서블릿 스레드는 그동안 대기 상태에 빠진다.
DeferredResult나Callable을 써도 결국 워커 스레드를 추가로 생성해야 하므로, 대규모 요청 상황에서는 서버 자원 소모가 심해진다.
2.2 AsyncRestTemplate (Spring 4.0)
- 특징: 논블로킹을 지원하는 비동기 개념의 템플릿이다.
getForEntity호출 시ListenableFuture<ResponseEntity<T>>를 반환한다. - 장점: 서블릿 스레드를 즉시 해제할 수 있으며, 응답 후 처리할 콜백은 스프링 MVC가 알아서 관리한다.
- 한계: 내부적으로 요청당 별도의 스레드를 하나씩 생성하여 처리하기 때문에, 완전한 자원 최적화라고 보기는 어렵다.
2.3 Netty4ClientHttpRequestFactory를 통한 최적화
- 진정한 논블로킹: 추가 스레드 생성 없이 최소한의 스레드로 수많은 비동기 요청을 처리하기 위해 사용한다.
- Netty 메커니즘:
NioEventLoopGroup을 활용하며, 보통 (프로세서 코어 개수 * 2) 개의 워커 스레드만으로 효율적인 비동기 처리를 수행한다.
3. 비동기 콜백 구조와 DeferredResult의 결합
3.1 비동기 가공 및 연쇄 호출
- 비동기로 받은 데이터를 가공하여 리턴하려면
addCallback을 통해 성공/실패 콜백을 등록해야 한다. - 비동기 작업 중 발생하는 예외는 전파가 복잡하므로, 에러 핸들링 함수 내에서
DeferredResult에 에러를 위임하는 방식을 권장한다.
3.2 콜백 헬(Callback Hell)과 비즈니스 로직
- 비동기 응답 후 또 다른 비동기 요청을 보내는 연쇄 구조는 구현 가능하지만, 코드가 매우 복잡해지는 '콜백 헬' 현상이 발생한다.
- 이를 해결하기 위한 간결한 방식(Java 8 CompletableFuture 등)의 도입이 필요하다.
- 기존의 명령형 코드 스타일 → 함수형 코드 스타일
4. 데이터베이스 및 런타임 고려사항
4.1 JDBC의 비동기 한계
- 과거 상황 (2016년 기준): JDBC 스펙 자체가 블로킹 방식이라 순수한 논블로킹 구현이 불가능했다. MongoDB 등 일부 NoSQL만 논블로킹 드라이버를 제공했다.
- 현재 상황: JDBC 비동기 스펙(R2DBC 등)이 등장하여 관계형 데이터베이스에서도 논블로킹 통신이 가능해졌다.
4.2 성능 측정 주의사항
- 응답 시간 등을 테스트할 때는 반드시 워밍업(Warm-up) 단계를 거친 뒤 측정해야 정확한 데이터를 얻을 수 있다.
5. 소소한 지식 및 팁
- 복습:
Callable은Runnable과 달리 작업 결과를 리턴할 수 있고, 체크드 예외(Checked Exception)를 던질 수 있다는 점이 핵심이다. - 스레드 효율성: 우리가 추구하는 고수의 구조는 수백 개의 요청을 단 몇 개의 스레드만으로 지연 없이 처리해내는 것이다.
6강 (AsyncRestTemplate의 콜백 헬과 중복 작업 문제)
https://www.youtube.com/watch?v=Tb43EyWTSlQ&t=192s
1. 개요
AsyncRestTemplate을 이용한 비동기 호출 시 발생하는 콜백 헬(Callback Hell) 문제를 분석하고, 이를 해결하기 위해 직접 비동기 제어 클래스를 설계하며 함수형 스타일로 리팩토링하는 과정을 다룬다.
편한 방식을 쓰기 전에 가볍게 근간의 원리를 먼저 훑어본다는 느낌으로 본 강의를 수강했다.
2. 콜백 헬과 중복 작업 문제
2.1 중첩 콜백 구조의 한계
- 가독성 저하: 비동기 작업의 결과를 기반으로 다음 비동기 작업을 수행할 때, 콜백 안에 콜백이 들어가는 피라미드 형태의 구조(삼각형 코드)가 발생하여 가독성이 급격히 떨어진다. [03:12]
- 명령형 스타일: 비동기 작업 간의 의존성이 깊어질수록 코드가 복잡해지며, 비즈니스 로직과 비동기 제어 로직이 혼재된다.
2.2 에러 처리의 중복
- 각 단계의 비동기 작업마다
onFailure등 에러 처리 코드를 반복적으로 작성해야 하며, 전역적인 에러 정책을 적용하기 어렵다. [08:20]
3. Completion 클래스 설계 및 구현
비동기 작업의 흐름을 캡슐화하고 직렬적으로 체이닝(Chaining)하는 직관적인 구조로 개선해보기 위해 Completion이라는 제어 클래스를 직접 구현한다. 과정이 복잡한데, 일단 이해 기반으로 가볍게 훑어본다는 느낌으로 들었다.
3.1 핵심 체이닝 메서드
- from(): 비동기 작업의 시작점이다.
ListenableFuture를 받아Completion객체로 감싸서 리턴한다. [10:22] - andAccept(): 비동기 작업의 최종 결과를 소비(Consume)하고 흐름을 종료하는 메서드다. [15:31]
- andApply(): 앞선 작업의 결과를 받아 또 다른 비동기 작업을 수행하고, 그 결과를 다음 단계로 넘겨주는 메서드다. (Function 형태의 파라미터) [25:32]
3.2 다형성을 이용한 구조 분리
- 각 연산의 특성에 맞게 클래스를 분리하여 다형성을 적용한다. [38:33]
- AcceptCompletion: 결과를 소비하고 종료하는 역할.
- ApplyCompletion: 중간에서 데이터를 가공하거나 다음 비동기 작업을 연쇄적으로 호출하는 역할.
4. 에러 처리 메커니즘 (andError)
4.1 에러 시그널 전파
- 어느 단계에서든 에러가 발생하면 이후의 비즈니스 로직(andApply, andAccept)은 스킵하고, 가장 가까운 에러 처리 메서드(
andError)로 시그널을 전파한다. [43:45]- next의 error 핸들러를 호출해주는 느낌이라 로직 스킵이 가능
- 정상적인 흐름에서는
andError를 패스하여 다음 단계로 결과값을 전달한다. [45:11]- run에서 이전 작업의 결과를 그대로 넘겨주기만 하도록 구현해서 패싱 작업을 가능케 함
5. 제네릭(Generic)을 통한 타입 안전성 확보
- 다양한 반환 타입(ResponseEntity, String 등)에 대응하기 위해 타입 파라미터(T, S 등)를 적용한다. [59:00]
- 메서드 레퍼런스와 람다식을 활용하여 복잡한 타입 정의 없이도 간결하게 비동기 파이프라인을 구축할 수 있도록 개선한다. [01:10:00]
- 과정이 좀 복잡하긴 하지만, 이렇게 안하면 외부 API 호출같은게 아닌, 임의로 만든 비동기 작업을 기존 타입 하드코딩 로직으로는 타입 호환이 안되므로 어쩔 수 없이 제네릭으로 바꿔줘야하는 듯 하다.
6. 짤막 지식
- Continuation Passing Style (CPS): 프로그램의 제어 흐름을 콜백(Continuation)으로 넘기는 방식으로, 비동기 프로그래밍의 근간이 되는 스타일이다. [34:48]
- Java 8 CompletableFuture: 이번 강의에서 직접 구현한
Completion클래스는 자바 8의CompletableFuture와 동작 원리가 유사하며, 실제 현업에서는 보다 정교하게 설계된CompletableFuture를 사용한다. [01:13:00]- 훨씬 간단하며, 비동기 작업 여러개의 결과를 리스트에 담고 그걸 리턴한다던가 하는 복잡한 작업도 수행 가능하게 된다고 함.
7. 시사점
복잡한 비동기 로직을 단순히 라이브러리 사용법으로 익히는 것에 그치지 않고, 내부 제어 구조를 직접 설계해 봄으로써 리액티브 프로그래밍의 핵심인 함수형 파이프라인과 비동기 흐름 제어의 원리를 깊이 이해할 수 있다. [05:00]
7강 (CompletableFuture : 스프링 5 리액티브 배우기 전, 마지막으로 배울 자바 비동기 프로그래밍 기술의 정점)
1. CompletableFuture의 기본 개념과 제어
1.1 명시적 완료 제어
- completedFuture(value): 이미 작업이 완료된 상태의
CompletableFuture객체를 생성한다. 호출 즉시 결과를 얻을 수 있다.
- 수동 완료 처리: 생성자로 객체만 만들어 둔 뒤,
complete(value)를 호출하여 비동기 작업을 명시적으로 완료시킬 수 있다.- (객체 만들고 완료 처리 따로 안된채로 get을 하면 워커스레드가 무한히 돌아가므로 get을 호출한 쪽에선 무한 대기하게 된다)
- 예외 완료 처리:
completeExceptionally(ex)를 호출하면 작업이 예외와 함께 종료된 상태가 되며, 이후 어딘가에서get()호출 시 해당 예외를 발생시킨다.
1.2 CompletionStage 인터페이스
- 역할:
CompletableFuture가 구현하는 핵심 인터페이스로, 하나의 비동기 작업이 완료되었을 때 그 결과에 의존하여 또 다른 작업을 수행하는 '단계(Stage)' 간의 연결을 정의한다.
- 연쇄적 호출(Chaining):
thenApply,thenAccept,thenRun등 대부분의 메서드가 다시CompletionStage(즉,CompletableFuture) 객체를 리턴한다.
- 의존성 관리: 덕분에 "A 작업이 끝나면 B를 하고, B가 끝나면 C를 하라"는 식의 의존성 있는 비동기 로직을 콜백 헬 없이 간결한 파이프라인 형태로 구성할 수 있다.
2. 함수형 인터페이스의 이해 (람다 활용의 기초)
CompletableFuture의 메서드들은 자바 8의 표준 함수형 인터페이스를 인자로 받는다. 이를 정확히 이해해야 어떤 상황에 어떤 메서드를 쓸지, 그리고 람다식을 어떻게 작성할지 결정할 수 있다.
학습 포인트: 인자로 넘길 때 람다 형식 (input) -> { body }에서 input과 리턴값의 유무는 아래 인터페이스들의 구조에 따라 결정된다.
| 인터페이스 | 파라미터(Input) | 리턴값(Output) | CompletableFuture 활용 예시 |
|---|---|---|---|
| Supplier | 없음 | 있음 | supplyAsync(Supplier<U> s): 비동기 작업 시작 및 결과 반환 |
| Consumer | 있음 | 없음 | thenAccept(Consumer<T> c): 결과값을 소비하고 종료 |
| Function | 있음 | 있음 | thenApply(Function<T, R> f): 결과값을 받아 다른 타입으로 변환 |
| BiFunction | 있음(2개) | 있음 | thenCombine: 두 개의 비동기 결과를 합쳐서 새로운 결과 반환 |
| Runnable | 없음 | 없음 | thenRun(Runnable r): 결과와 상관없이 특정 로직 수행 |
3. 비동기 작업 생성 및 체이닝 (Chaining)
3.1 작업 생성 메서드
- runAsync(Runnable): 파라미터를 받지 않고, 리턴값이 없는 단순 비동기 작업을 수행한다. 최초 시작점으로 쓰면 좋을 듯
- supplyAsync(Supplier): 비동기 작업 후 결과값을 리턴한다. 다음 체이닝 단계로 데이터를 넘겨줄 수 있어 활용도가 높다.
3.2 결과 가공 및 소비
- thenApply(Function): 직전 작업의 결과를 받아 가공한 뒤 새로운 값을 리턴한다. (Optional의 map과 유사)
- thenAccept(Consumer): 결과를 받아서 소비할 뿐, 별도의 값을 리턴하지 않는다. 보통 체이닝의 마지막 단계에서 사용한다.
4. map vs flatMap
4.1 map vs flatMap 한 줄 요약
- map: 알맹이를 변환해서 다시 봉투에 담아 준다. (1단계 변환)
- flatMap: 알맹이를 꺼내서 변환했는데 결과가 또 봉투라면, 봉투를 하나로 합쳐서 준다. (평탄화)
4.2 Optional에서의 결정적 차이
함수가 Optional을 리턴할 때 두 메서드의 차이가 명확해진다.
- map: 결과가 중첩됨 →
Optional<Optional<T>>(다루기 귀찮음)
- flatMap: 결과가 평탄함 →
Optional<T>(깔끔함)
| 구분 | map | flatMap |
|---|---|---|
| 핵심 역할 | 단순 값 변환 | 중첩 구조 방지 (평탄화) |
| 함수 리턴값 | 일반 객체 (T) | 컨테이너 객체 (Optional<T>) |
| 결과 형태 | Optional<Optional<T>> | Optional<T> |
| 사례 | thenApply | thenCompose |
5. 동기 vs 비동기 체이닝의 차이점
5.1 then~~~ vs then~~~Async
이 둘의 결정적인 차이는 "어떤 스레드에서 실행되느냐"에 있다.
-
thenApply (Map 느낌):
- 이전 작업이 이미 끝났다면 메서드를 호출한 스레드(예: 메인 스레드)에서 실행된다.
- 이 경우 메인 스레드 입장에서는 동기적으로 실행되는 것과 같다.
- 이전 작업이 아직 진행 중이라면 이전 작업을 마친 워커 스레드에서 이어서 실행된다.
- 이 경우에는 메인 스레드 입장에서 비동기!
- 이전 작업이 이미 끝났다면 메서드를 호출한 스레드(예: 메인 스레드)에서 실행된다.
-
thenApplyAsync (Map 느낌):
- 이전 작업의 완료 여부와 상관없이 항상 별도의 스레드(또는 지정된 스레드 풀)에서 작업을 수행한다.
- 두 번째 파라미터로
ExecutorService를 넘겨 특정 스레드 풀 정책을 적용할 수 있다.
- 이전 작업의 완료 여부와 상관없이 항상 별도의 스레드(또는 지정된 스레드 풀)에서 작업을 수행한다.
6. 고급 연산 및 에러 복구
6.1 thenCompose (FlatMap 느낌)
- 상황: 비동기 작업의 리턴 타입이 또 다른
CompletableFuture인 경우,thenApply를 쓰면 결과가 중첩된 구조(CompletableFuture<CompletableFuture<T>>)가 된다.
- 해결:
thenCompose를 사용하여 중첩된 껍질을 벗기고 단일한 스트림으로 평탄화(Flatten)한다.
- 리턴이 어떤 값 자체가 아니라 CompletableFuture 객체이어야 하는 경우도 존재하기 때문에(AsyncRestTemplate의 리턴을 매핑하고 난 결과 등), 이 활용 방식을 쓸 일이 분명히 있으니 익혀두자
6.2 exceptionally (에러 복구)
- 비동기 파이프라인 도중 예외가 발생했을 때 이를 가로채서 정상적인 결과값으로 복구하는 역할을 한다. 이를 통해 흐름을 끊지 않고 다음 작업을 지속할 수 있다.
→ 이 외의 CompletableFuture의 자세한 내용은 자바 API 문서를 읽어보자. 굉장히 좋은 정보들이 많다.
7. 실전 리팩토링: Spring 4.0과의 연동
7.1 ListenableFuture의 한계 극복
- 상황: 스프링 4.0의
AsyncRestTemplate은ListenableFuture를 리턴하며, 이는 자바의 표준 비동기 기법과 결합하기 어렵다.
- 해결:
ListenableFuture를CompletableFuture로 래핑하는 함수를 작성한다.- 성공 콜백 내에서
CompletableFuture.complete()를 호출하고, 실패 콜백 내에서completeExceptionally()를 호출하도록 설계한다.
- 성공 콜백 내에서
- 효과: 콜백 헬(Callback Hell)을 제거하고 선언적인 함수형 비동기 파이프라인을 구축할 수 있다.
- CompletableFuture는 비동기 작업을 나타내는 객체가 아니고, 완료되고 난 그 결과(에러 난 경우도 포함)를 나타내는 객체이기 때문에, 이 객체를 새로 하나 만들었다고 해서 추가적인 비동기 작업이 발생한다거나 그런거 아니니까 안심하자
- 이전 결과를 받아서 외부 API 호출하고 그걸 CompletableFuture로 랩핑한게 결과값이 될텐데, 바로 이럴 때 오늘 배운 thenCompose를 쓰면 된다!
8. 결론 및 2026년 기준 제언 (Current Status)
8.1 리액티브 프로그래밍으로의 진화
CompletableFuture는 강력하지만, 데이터가 단건이 아닌 스트림(Stream) 형태이거나 백프레셔(Backpressure)를 통한 흐름 제어가 필요한 복잡한 시나리오에서는 한계가 있다. 이를 완벽히 소화해 내기 위한 기술이 바로 스프링 5의 리액티브(WebFlux)와 Project Reactor이다.
8.2 2026년의 기술 환경 Note
- AsyncRestTemplate: 현재 시점(2026년)에서는 이미 오래전에 Deprecated 되었으며, 실제 실무에서는 WebClient나 최신 비동기 클라이언트를 사용하는 것이 표준이다.
- Virtual Threads: 자바 21 이후 도입된 가상 스레드 덕분에 비동기 프로그래밍의 복잡성 없이도 높은 처리량을 낼 수 있는 환경이 되었으므로, 상황에 맞는 기술 선택이 필요하다.
8강 (WebFlux)
1. WebFlux와 MVC의 공존 및 차이
1.1 의존성 및 우선순위
- 배타적 관계: 스프링 부트 설정에서
Web과Reactive Web은 동시에 사용할 수 없다. 만약 두 의존성이 모두 존재하면Web(MVC)이 우선 적용된다. 이는 스프링 부트 기동 시DispatcherServlet클래스의 존재 여부를 먼저 체크하기 때문이다. - 호환성: 기존 스프링 MVC에서 하던 대부분의 작업은 WebFlux에서도 동일하게 수행 가능하다.
1.2 클라이언트의 변화
- AsyncRestTemplate의 은퇴: 기존의 비동기 템플릿은 Deprecated 되었으며, 이를 WebClient가 완전히 대체한다.
2. WebClient와 Mono의 동작 메커니즘
2.1 리액티브 컨테이너: Mono
- 정의: 0개 또는 1개의 데이터를 담는 리액티브 컨테이너다.
Optional이나List에서 처럼, 데이터를 다루는 함수를 제공하며,Mono.just()를 통해 기확정된 값을 담을 수 있다. - 지연 실행 (Lazy Evaluation): 리액티브 스트림즈의 핵심 원칙에 따라, Publisher(Mono 등)를 생성했다고 해서 즉시 실행되지는 않는다. 반드시 누군가 구독(subscribe)해야 비로소 동작한다.
- 반환값이 Mono일 때, 그걸 스프링이 알아서 subscribe해서 응답을 만들어낸다. 즉 결과값Mono에 체이닝 된 퍼블리셔들이 연쇄적으로 다 구독된다. 그 밖의 것은 자동 구독해주지 않음.
- subscribe를 호출해주는 스레드도 비동기 작업을 처리하는 네티 워커 스레드랑 같다. (이것도 스케줄러로 변경 가능한 듯)
- 명시적으로 내가 실제 퍼블리싱을 수행시키려면 res.subscribe() 를 호출해주면 되긴 하는데 이건 권장하지 않는 방식임
- 반환값이 Mono일 때, 그걸 스프링이 알아서 subscribe해서 응답을 만들어낸다. 즉 결과값Mono에 체이닝 된 퍼블리셔들이 연쇄적으로 다 구독된다. 그 밖의 것은 자동 구독해주지 않음.
2.2 WebClient 요청 체이닝
- 함수형 스타일:
client.get().uri(...).exchange()와 같이 메서드당 하나의 역할만 위임하여 체이닝하는 방식을 취한다.- exchange : 이 앞에까지는 HTTP 요청을 만든거고, exchange로 이걸 실제로 보내서 응답을 받겠다는 행위를 명시하는 것
- ClientResponse는 ResponseEntity랑 비슷한거라 보면 된다.
- 자동 구독: 컨트롤러가
Mono를 리턴하면, 개발자가 직접subscribe()를 호출할 필요가 없다. 스프링 WebFlux가 내부적으로 최종 시점에 구독을 수행하여 응답을 만들어낸다. - 여러 비동기 작업을 연속적으로 체이닝할 때 flatmap을 활용하면 된다.
3. 연산자(Operator) 활용 및 가공
- flatMap의 필요성:
Mono<ClientResponse>를Mono<String>으로 변환할 때,map을 쓰면Mono<Mono<String>>이 된다. 이때flatMap을 사용하여 중첩된 구조를 평탄화(Flatten)해야 한다. - 비동기 작업 연동: 시간이 오래 걸리는 비즈니스 로직(함수)은
@Async와CompletableFuture를 반환하도록 설계하고, 이를Mono.fromCompletionStage()를 통해 리액티브 흐름에 결합한다.- @Async를 쓸 땐 꼭 클래스 쪽에 @EnableAsync 걸어주자
- 별도의 스레드 풀 정책 빈에 등록해서 지정하거나, 스케줄러를 활용해서 별도 스레드를 지정해서 쓰자. @Async의 기본 값 스레드는 운영 상에서 절대 쓰면 안되는 스펙이기 때문
- doOnNext: 퍼블리셔 흐름 중간에 부수 효과(Side-effect)를 주기 위해 사용한다. 주로 로그 기록 등에 적합하다.
4. 서버 인프라: Tomcat vs Netty
4.1 Tomcat (Servlet 기반)
- 모델: Thread-per-request (요청 1개당 스레드 1개 할당).
- 특징: Blocking I/O 중심이며 구조가 직관적이다. 스레드 수가 동시 처리 능력을 제한한다.
4.2 Netty (NIO 기반)
- 모델: Event Loop (소수의 스레드로 수많은 연결 처리).
- 특징: Non-blocking I/O를 사용하는 NIO(New I/O) 방식이다. 읽을 데이터가 없어도 스레드가 멈추지 않고 즉시 리턴되는 Non-blocking 모드를 지원하며, WebFlux의 기본 서버로 사용된다.
4.3 참고
- 서블릿(Servlet)
- Java 웹 요청을 처리하는 표준 인터페이스
doGet/doPost형태로 HTTP 요청 처리- 서블릿 컨테이너(Tomcat 등)에서만 동작
- Spring MVC의
DispatcherServlet도 서블릿임
- 서블릿 컨테이너
- 서블릿 객체 관리
- 요청 수신 → 스레드 할당 → HttpServletRequest/Response 생성
- 필터/인터셉터 처리
- Tomcat/Jetty/Undertow 등이 해당
5. 리액티브 체인의 실제 구독 구조
리액티브 환경에서의 역할 분담은 다음과 같다.
- Repository: 데이터의 원천이자 Publisher 제작자.
- Service: 여러 퍼블리셔를 결합하고 가공하는 조립자.
- Controller: 조립된 퍼블리셔를 최종적으로 반환하는 자.
- WebFlux (DispatcherHandler): 실제 Subscriber이자
subscribe()를 실행하는 주체.- [subscribe()하는 스레드] = Netty 이벤트 루프
- DB 드라이버: 백프레셔 프로토콜을 준수하며 데이터를 실제로 Push하는 공급자.
핵심 포인트: 실제 데이터 흐름은 오직 WebFlux가 마지막에 수행하는 subscribe() 단 한 번에 의해 트리거된다.
6. 아키텍처에 대한 오해 바로잡기
- 계층 구조와 프레임워크: 'Controller–Service–Repository'라는 계층 구조는 특정 프레임워크(Spring MVC)의 전유물이 아니다. 이는 설계 패턴일 뿐이며 WebFlux에서도 그대로 사용 가능하다.
- MVC의 진의: 스프링 MVC와 WebFlux의 차이는 "서블릿 기반인가, 리액티브 기반인가"라는 웹 요청 처리 방식(Architecture)의 차이일 뿐이다.
7. 소소한 지식 및 팁
- NIO의 3대 요소: Channel(통로), Buffer(저장소), Selector(이벤트 감지).
- 스케줄러 설계: 가벼운 동기 로직이 비동기 워커 스레드에 방해를 주지 않도록
BoundedElastic스케줄러 등을 적절히 할당하는 설계 능력이 중요하다. - 무거운 작업의 스레드 분리 (
thenApplyAsync등)- 활용 케이스: 이번 단계에서 처리할 작업이 시간이 오래 걸리는(Heavy) 경우에 사용한다.
- 핵심 전략: 무거운 로직을 별도의 워커 스레드에서 돌리도록 설정함으로써, 이전 단계까지 사용되던 논블로킹 IO 스레드(Netty 이벤트 루프)를 즉시 해방시킨다.
- 이점: 해방된 IO 스레드는 대기하지 않고 즉시 다른 네트워크 요청을 처리하러 갈 수 있어, 서버 전체의 처리율을 극대화할 수 있다.
9강 ( Mono의 동작 방식과 block() )
1. 개발 환경 및 실습 팁
학습 효율을 높이기 위한 기본적인 설정 및 구성 방식은 다음과 같다.
- Lombok 설정: IntelliJ 설정에서 'Enable annotation processing'을 체크하고 플러그인을 설치해야 정상적으로 동작한다.
- 컨트롤러 구성: 별도의 클래스를 만들지 않고
@SpringBootApplication어노테이션이 붙은 메인 클래스에@RestController를 함께 붙여 테스트용 컨트롤러로 활용할 수 있다.
2. 동기 및 비동기 코드의 실행 순서 분석
log.info("pos1");
Mono m = Mono.just(generateHello()).doOnNext(c->log.info(c)).log();
log.info("pos2");
return m
private String generateHello() {
log.info("method generateHello()");
return "Hello Mono";
}
출력결과:
pos1
method generateHello()
pos2
... (Mono log 오퍼레이터 관련 출력)
Hello Mono (doOnNext 에서의 출력)
... (Mono log 오퍼레이터 관련 출력)리액티브 코드 내에 동기적인 로직이 혼재될 경우, 코드의 선언 방식에 따라 실행 시점이 달라진다.
2.1 Mono.just()의 즉시 실행 특성
- 현상:
Mono.just(generateHello())와 같이 작성하면, 비동기 파이프라인이 구독(Subscribe)되기 전이라도generateHello()메서드가 즉시 호출된다. - 원인: 자바의 메서드 호출 원칙에 따라,
just()메서드의 파라미터 값을 결정하기 위해 안쪽의 메서드가 먼저 실행되기 때문이다.
2.2 지연 실행(Lazy Evaluation) 구현
- 해결책:
Mono.fromSupplier(() -> generateHello())와 같이 람다(함수) 형태로 넘겨야 한다. - 효과: 이렇게 하면 실제로 구독이 일어나는 시점에만 해당 메서드가 실행되어 진정한 비동기 논블로킹 흐름을 탈 수 있다.
3. 구독(Subscription)의 다중성
Publisher(Mono, Flux)는 하나 이상의 Subscriber를 가질 수 있으며, 각 구독은 독립적인 실행 흐름을 만든다.
- 이중 실행 문제: 개발자가 코드 내에서
m.subscribe()를 호출하고, 그m(Mono)을 다시 컨트롤러에서 리턴하면 로그가 두 번 찍힌다. - 이유: 리턴된 Mono를 스프링 WebFlux가 최종 응답을 만들기 위해 한 번 더 구독하기 때문이다. 따라서 특별한 이유가 없다면 중복 구독은 피해야 한다.
4. Hot vs Cold Publisher
데이터 소스의 성격에 따라 Publisher의 타입을 두 가지로 분류할 수 있다.
- Cold Publisher: 어떤 Subscriber가 구독하든 항상 처음부터 똑같은 데이터를 생성해서 제공한다. (예: 정적 데이터 소스, 일반적인 DB 쿼리 결과)
- Hot Publisher: 구독 시점과 상관없이 실시간으로 흐르는 데이터를 제공한다. Subscriber는 구독한 시점부터 발생하는 데이터만 받을 수 있다. (예: 실시간 유저 액션, 주식 시세 스트림, 라이브 방송)
5. Mono의 block() 메서드와 주의사항
5.1 block()의 동작 원리
- 메커니즘:
block()은 내부적으로subscribe()를 호출한다. 퍼블리셔 파이프라인을 끝까지 실행시켜 최종 데이터를 얻어낼 때까지 호출 스레드를 멈춰 세운다. - 네이밍의 의미: 결과가 나올 때까지 스레드를 차단(Block)한다는 점을 강조하기 위한 직관적인 명명이다.
5.2 사용 시 발생하는 문제점
- 중복 연산: 앞서 언급한 대로 WebFlux가 리턴값을 다시 구독하기 때문에,
block()으로 한 번 실행하고 Mono를 리턴하면 무거운 작업이 두 번 수행될 수 있다. - 성능 저하: 논블로킹 환경에서 스레드를 점유하여 대기시키는 것은 리액티브 프로그래밍의 본래 목적(적은 스레드로 고효율 유지)에 어긋난다.
- 대안:
block()을 써서 값을 꺼내기보다,map이나flatMap등을 통해 파이프라인 안에서 데이터를 처리하고 최종 Mono 자체를 리턴하는 습관을 들여야 한다.
6. 결론
Mono의 동작 방식을 정확히 이해하지 못하고 just()나 block()을 남용하면 비동기 프로그래밍의 이점을 잃게 된다. 특히 실행 시점의 차이(Lazy vs Eager)를 명확히 구분하고, 프레임워크가 제공하는 자동 구독 메커니즘을 적극 활용하는 설계가 필요하다.
7. 복습 : 자바&스프링 비동기 스펙 간단 비교 분석
① Future (The Pioneer)
- 한계:
isDone()으로 계속 묻거나,get()으로 결과가 나올 때까지 스레드가 멈춰서 기다려야한다. - 비유: 요리를 주문하고 주방 앞에서 나올 때까지 멍하니 서 있는 것과 같다.
② ListenableFuture (Callback Style)
- 특징: 구글에서 만든 개선판이다. 작업이 끝나면 실행할 "콜백 함수"를 등록할 수 있어
get()의 기다림을 줄였다. - 한계: 여러 비동기 작업을 조합하기 시작하면 콜백 지옥(Callback Hell)에 빠질 수 있다.
③ CompletableFuture (Functional Pipeline)
- 특징: 자바 8에서 도입된 비동기 끝판왕이다.
thenApply,thenCombine등을 이용해 여러 비동기 작업을 마치 파이프라인처럼 연결할 수 있다. - 장점: 별도의 외부 라이브러리 없이도 세련된 비동기 로직 작성이 가능하다.
④ Mono & Flux (Reactive Streams)
이 둘은 스프링 WebFlux의 핵심으로, 데이터의 '흐름(Stream)'에 집중한다.
- Mono: "결과가 아예 없거나, 딱 하나 있거나." (비동기 단건 응답)
- Flux: "결과가 여러 개 계속 나올 수 있음." (비동기 리스트, 실시간 스트림)
- 차별점: Lazy(지연 실행) 속성이 있어,
subscribe()를 호출하기 전까지는 아무 일도 일어나지 않는다. 또한 백프레셔(Backpressure)를 지원해 데이터 쏟아짐을 제어할 수 있다.
10강 ( Flux의 특징과 활용 방법)
1. Flux의 개념과 Mono와의 차이
Flux는 0개부터 N개의 데이터를 발행할 수 있는 Publisher다. 기존 MVC에서 List<T>를 반환하던 것과 개념적으로 유사하지만, 리액티브 관점에서는 큰 차이가 있다.
- Flux vs Mono\<List\<T>>:결과적 유사성: 클라이언트가 최종적으로 받는 데이터 뭉치는 비슷해 보일 수 있다.
- Flux의 강점:각 데이터 개별 요소에 대해 리액티브 연산자(Operator)를 적용할 수 있으며, 전체 데이터가 준비될 때까지 기다리지 않고 하나씩 즉시 흘려보낼(Stream) 수 있다. - 필수 설정: Flux로 스트림 데이터를 보내려면
@GetMapping의produces속성에MediaType.TEXT_EVENT_STREAM_VALUE를 반드시 지정해야 한다. 이를 누락하면 스트림이 아닌, 전체 데이터를 다 만든 뒤 한꺼번에 통째로 응답하게 된다.
2. Flux 생성 및 크기 제어
2.1 다양한 생성 함수
- fromIterable(): 이미 존재하는 컬렉션을 기반으로 Flux를 생성한다.
- fromStream(): 자바 8의
Stream을 기반으로 생성한다. 이때Stream.generate()와 조합하면 무한 스트림을 만들 수 있다.
2.2 스트림 크기 제한
- limit(n): 스트림의 크기를 명시적으로 정의한다.
- take(n): 무한 스트림 상태에서 처음 n개의 데이터만 가져오고 구독을 종료한다.
3. Flux.generate()를 통한 정밀한 스트림 생성
자바 8의 Stream 스펙에 의존하지 않고, Flux 고유의 스펙으로 데이터를 동적으로 생성하는 방식이다.
- sink: 데이터가 흘러가는 통로를 의미하며,
sink.next()를 통해 다음 데이터를 스트림에 태운다. - 상태 기반 생성 (Stateful Generate):
- stateSupplier: 초기 상태 값을 생성하는 함수.
- generator (BiFunction): 현재 상태를 바탕으로 데이터를 생성(
sink.next)하고, 다음 상태 값을 리턴하여 순환시킨다. 연속적인 ID 부여 등에 매우 유용하다.
4. 스트림 결합과 시간 제어 (zip & interval)
4.1 delayElements()와 SSE
- 기능: 각 엘리먼트 발행 사이에 딜레이를 준다.
- 특징: 내부적으로 별도 스레드에서 블로킹 없이 대기하며, 서버 측에서 Server-Sent Events(SSE)를 테스트하거나 특정 간격으로 밀어줄 때 유용하다.
4.2 Flux.zip()의 마법
두 개의 서로 다른 데이터 스트림을 하나로 묶어주는 연산자다.
- Flux.interval: 일정 간격으로 이벤트 발생시키면서 0부터 1씩 늘어나면서 데이터 스트림 만들어내는 용도인 듯
- 시간 제어:
Flux.interval()과zip을 결합하면, 인터벌의 주기에 맞춰 데이터가 하나씩 발행되도록 강제할 수 있다. 인터벌의 값(0, 1, 2...)은 버리고 데이터만 취하는 식으로 딜레이 효과를 낸다. - 데이터 병합: 서로 다른 마이크로서비스(예: 서버 A의 프로필 정보 + 서버 B의 스코어 정보)에서 가져온 데이터를 유저 ID 기준으로 순서만 맞다면 하나로 묶어 완전한 객체를 가공해낼 때 매우 강력하다.
5. 소소한 지식 및 실무 팁
- 네이밍 센스:
sink라는 표현은 데이터가 흘러들어가는 '싱크대'나 '수조'를 연상하면 이해가 빠르다. - 설계 철학: 서버에서
delayElements()를 거는 것은 리소스를 사용하는 일이므로, 단순한 화면 표시용 딜레이라면 클라이언트 사이드에서 처리하는 것이 더 낫다. 서버 측 딜레이는 비즈니스 로직상 필요하거나 SSE 표준을 지킬 때 주로 사용하자.
6. (참고) SSE 개념
6.1 SSE(Server-Sent Events)란?
전통적인 HTTP 통신은 클라이언트가 요청(Request)을 보내야만 서버가 응답(Response)을 주는 '단방향' 방식이다. 하지만 SSE는 한 번 연결을 맺고 나면, 서버가 클라이언트에게 지속적으로 데이터를 스트리밍할 수 있게 해준다.
6.2 핵심 특징
- 단방향 통신 (Server → Client): 서버에서 클라이언트로만 데이터를 보낼 수 있다. (클라이언트가 서버로 보낼 땐 별도의 HTTP 요청 필요)
- 표준 HTTP 사용: 특별한 프로토콜 없이 기존의 HTTP 프로토콜 위에서 동작한다.
- 자동 재연결: 클라이언트(브라우저)가 연결이 끊어지면 자동으로 재연결을 시도한다.
- 텍스트 기반: 기본적으로
text/event-stream형식의 텍스트 데이터를 주고받는다.
6.3 SSE vs WebSocket 비교
실시간 통신하면 떠오르는 웹소켓(WebSocket)과 비교해 보면 용도가 명확해짐
| 구분 | SSE | WebSocket |
|---|---|---|
| 통신 방향 | 단방향 (Server → Client) | 양방향 (Full-duplex) |
| 프로토콜 | 표준 HTTP | 별도의 WS 프로토콜 |
| 난이도 | 구현이 매우 단순함 | 구현 및 관리가 비교적 복잡함 |
| 재연결 | 브라우저가 자동 지원 | 직접 구현해야 함 |
| 주요 용도 | 알림 서비스, 뉴스 피드, 주가 지수 | 채팅, 멀티플레이어 게임 |
6.4. WebFlux에서의 SSE 구현
강의에서 배운 대로, WebFlux에서는 Flux를 사용하면 SSE 구현이 쉬워짐
- Produces 설정: 컨트롤러에서 리턴 타입을
MediaType.TEXT_EVENT_STREAM_VALUE로 지정하기. - Flux 리턴:
Flux.interval()등을 이용해 주기적으로 데이터를 발행하는 퍼블리셔를 반환하기. - 작은 팁: SSE는 클라이언트가 브라우저 창을 닫으면 서버 쪽의
Flux구독도 자동으로 해제(cancel)돼서 리소스 관리가 효율적임
6.5 요약
- SSE는 "서버 전용 라디오 방송"이라고 보면 된다.
- 채팅처럼 주고받는 게 아니라, 서버의 상태 변화를 실시간으로 클라이언트에게 알릴 때 아주 좋다.
- WebFlux의
Flux와 시너지가 좋다.
