
1. 강의 복습 내용
- 목표 :
- 기본 과제 1 : PyTorch Documentation 활용 & Custom Model 제작 (with 🦆부덕이)
- PyTorch 강의 2개 듣기- 결과 :
- 기본 과제 1 (△)
- PyTorch 강의 2개 듣기 (X)
2. 피어 세션
- 강의 학습 내용과 과제에서 다뤘던 헷갈리는 부분을 서로 토론함
1. gather 함수에서의 dimension이 의미하는 것?
→ indices가 참조할 dimension
2. 을 로 미분한 값이 왜 저렇게 나오는지에 대해
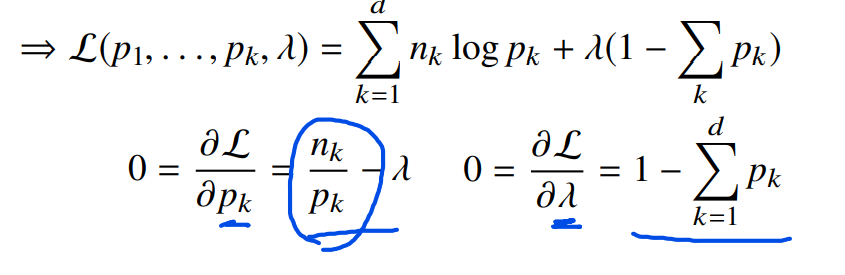
- 강의에서 나왔던 PyTorch template vs. Pytorch Lightning 차이점에 대해
3. 공부를 하며 고민한 내용, 고민 결과
torch.nn.Linear()에서 weight를(out_features, in_features)로 만들고 weight를 transpose시켜서input.matmul(weight.t())하는 이유는 뭘까? weight를 (in_features, out_features)로 만들어서 input.matmul(weight)하면 "불필요한 transpose 연산을 하지 않아도 되지 않는가?"
→torch.nn.Linear()공식문서 : https://pytorch.org/docs/master/_modules/torch/nn/modules/linear.html#Linear
결론
- 참고 : https://discuss.pytorch.org/t/why-does-the-linear-module-seems-to-do-unnecessary-transposing/6277
- backend side에서 BLAS(Basic Linear Algebra Subroutines)가 transposed matrices 연산을 지원하므로 transpose할 때 overhead(간접 비용)은 따로 들지 않음
→ "Transposition is free for gemm(general matrix multiply) calls"
→ 즉, transposing in forward pass는 overhead가 없지만, backward pass에서 less efficient함
- matrix multiplication의 second matrix를 저장할 때 transposed 형태로 저장하면 효율성을 더 상승시킴
→ multiplication routine이 메모리에 더 contiguous한(연속적인, 인접한) 방식으로 접근할 수 있어서 cache misses가 더 적음
→ https://stackoverflow.com/questions/18796801/increasing-the-data-locality-in-matrix-multiplication
4. 과제 수행 과정/과제 결과물에 대한 정리
5. 2번째 멘토링 (오후 8시 ~ 10시)
- 질의응답
- PyTorch Lightning 사용법 설명
- PyTorch로 구현된 VAE 코드를 PyTorch Lightning로 바꿔보기
- 심화과제 해설 (다음주로 변경)
6. 회고 🦆
- 오늘의 모더레이터 : 남규님
- 부덕이와 함께 한 PyTorch 과제의 분량에 압도당한 하루였음..
- 예상보다도 훨씬 많은 과제의 양과 PyTorch Documentation을 꼼꼼히 읽으며 공부하다 목표했던 PyTorch 강의를 수강하지 못했음
- 내일은 강의도 꼭 수강해보자

NLP ML Engineer, MLOps