들어가며

작년 11월에 이직한 회사에 입사한 이후, 모든 신규입사자는 전환 평가를 위한 과제를 수행해야 한다는 안내를 받았다. 과제 요구사항은 쿠버네티스를 활용해 클러스터를 구축하고 요구사항에 맞는 여러 미들웨어를 배포하는 내용이었다. 이전에 AWS의 EKS를 조금 다루어봤던 기억에 자신감은 있었지만, 퍼블릭 클라우드를 사용하지 않고 Private 클러스터를 구축한다는 것은 결코 쉽지는 않았다. 이 과제를 수행하며 가장 인상 깊었던 트러블 슈팅 과정을 기록으로 남겨보고자 글을 작성한다.
...오잉?! Pod의 상태가...!

순탄하게 클러스터에 Kong Ingress(Ingress Controller)와 Jenkins, MariaDB, Redis까지 총 4개의 미들웨어 배포한 이후, 바로 다음 날에 문제가 발생했다. Running 상태로 서비스 중이던 Kong 관련 파드가 아래와 같이 Evicted 상태를 반복하고 있던 것이다.
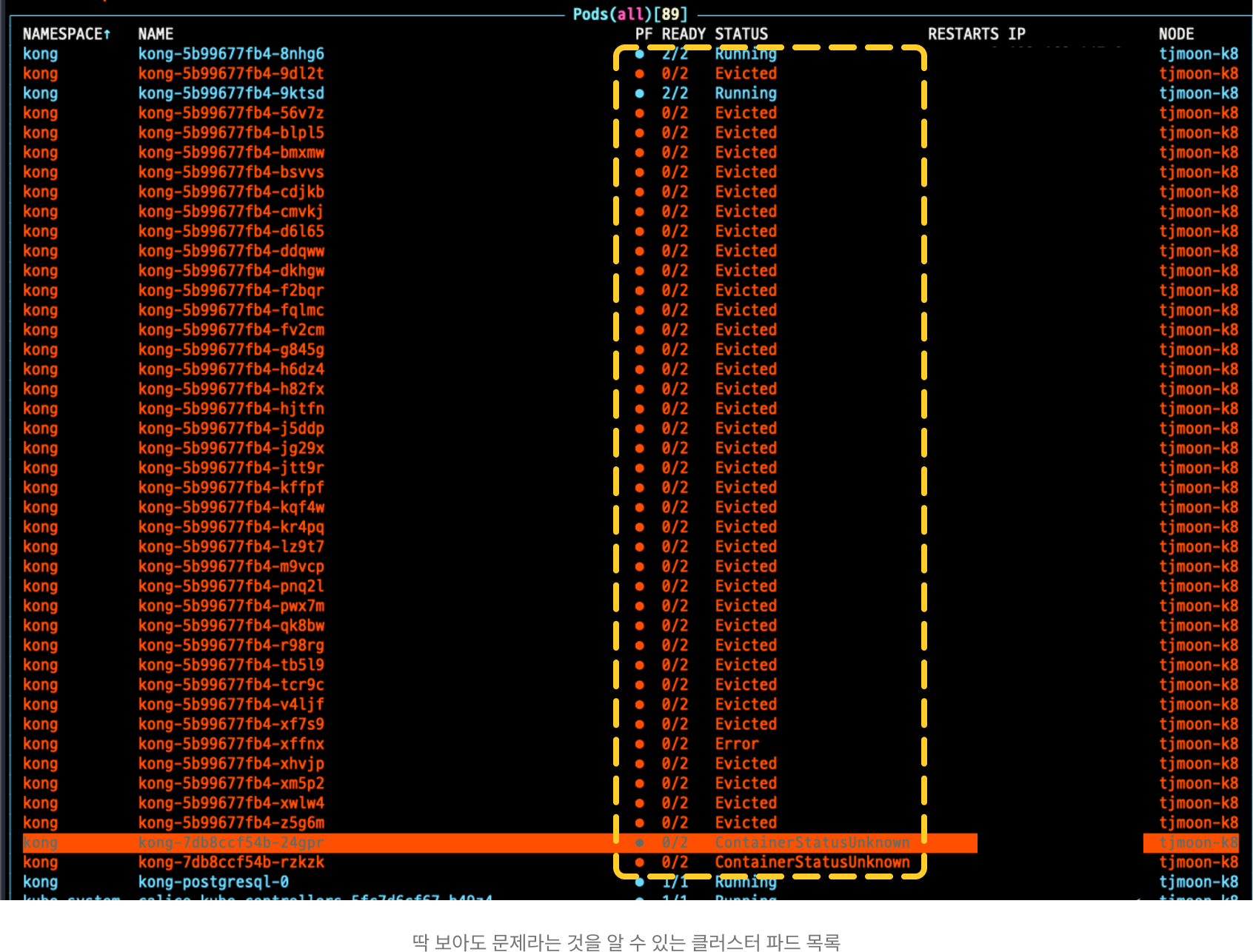
Evicted된 파드들부터 시작해서 Error나 ContainerStatusUnknown 상태로 변한 파드들도 있었는데, 이를 보고 처음엔 많이 당황했었다. 왜냐하면 클러스터에 각 미들웨어를 배포하는 명령만 입력했지, 별도로 클러스터를 건드린 적이 없었기 때문이다. 하룻밤 사이에 이게 무슨 일인가 싶었다. 네트워크 문제이거나 일시적 오류로 판단하고 파드를 모두 재시작해 보아도 결과는 동일했다.
Evicted 상태의 파드
아무래도 Evicted 상태로 변한 파드들이 제일 많았기에 Evicted 상태가 어떤 상태인지 궁금했다. 그래서 먼저 Evicted의 사전적 의미부터 찾아보았더니 Evicted에 대한 의미는 파드를 내쫓은 상태, 즉 파드를 추방한 상태라고 보아도 무방할 것이라고 생각이 들었다.
💡 ‘집을 내쫓다.’ 라는 의미로 특히 법에 의해 누군가를 집이나 땅을 떠나도록 강요하는 행위를 말한다.
그렇다면 파드를 추방하게 되는 조건은 도대체 무엇일까? 쿠버네티스의 Eviction에 대한 공식문서의 내용에서는 kubelet이 노드의 자원을 회수하기 위해 파드를 중단시키는 것이라고 말하고 있다. kubelet은 클러스터 노드의 메모리, 디스크 공간 등을 모니터링하는데, 이 자원들 중 하나 이상이 특정 수준에 도달하게 되면, 하나 이상의 파드를 중단시켜 자원을 회수한다고 안내하고 있다. 이를 통해, 내가 구축한 클러스터에도 동일하게 자원 관련 이슈가 발생한 것일 수도 있겠다는 생각에 파드의 Description을 확인해 보니 문제가 발생한 파드의 상태나 로그 등을 통해, 많은 정보를 볼 수 있었다.
DiskPressure 상태

파드의 Description을 보니 Condition과 Event 정보에서 해당 파드가 DiskPressure 되었다는 것을 친절하게도 안내해 주고 있었다. DiskPressure 상태가 되었다고 하니 디스크 자원과 관련된 이유 때문이라는 것을 대충 짐작해 볼 수 있었다. DiskPressure 관련 내용들도 공식 문서에서 쉽게 찾아볼 수 있었다.
🤔 DiskPressure란?
노드의 루트 파일 시스템 또는 이미지 파일 시스템의 가용 공간이나 inode 수가 축출 임계값에 도달한 상태를 말한다.
디스크 공간 부족 문제가 원인! 그런데..?

앞에서 언급한 대로 DiskPressure 상태를 확인했으니 실제로 디스크 공간을 확인해 보면 되겠다 싶어 바로 해당 노드의 디스크 사용량을 조회하였다. 필자는 당연하게도 디스크 가용 상태가 100%에 육박하는 디스크 풀 상태일 것으로 예상했지만, 그보다는 적은 86% 정도로 확인되었다.
💡 간단 요약
- 쿠버네티스 클러스터를 private 환경에 구축했다.
- 여러 미들웨어를 배포하던 중 정상적이던 파드의 상태가 Evicted로 변해버렸다.
- 디스크 자원 공간 부족으로 인한 문제였음을 알게 되었다.
Eviction Threshold 조정하기
문제가 발생한 노드의 디스크 사용량은 디스크 풀 상태도 아닌 86% 정도임을 알게 되었다. 그런데 어째서 DiskPressure 상태가 되었는지 궁금해졌다.
쿠버네티스는 운영 중인 노드의 리소스 부족 현상을 위해서 Eviction Threshold를 제공하는데, 이는 전적으로 kubelet이 담당하여 모니터링을 통해 자원을 회수한다. 이러한 Eviction Threshold에 대한 구체적인 정보를 찾아 파드의 DiskPressure 원인을 파악할 수 있을 것이라 생각했다. Eviction Threshold를 잘 조정한다면 디스크 부족 현상을 완화시킬 수 있지 않을까라는 자신감과 함께 말이다.
Eviction Threshold란?
Eviction Threshold은 직역하면 축출 임계값으로 해석되는데, 사실 이는 무겁고 생소하게 느껴진다. 그래도 하나씩 해석해 보면 이해하기 조금 더 쉬워진다.
🧐 Eviction Threshold, 그대로 해석해 보면?
축출은 무언가를 강제로 내보내는 것을 뜻하고, 임계값은 특정 조건이 발생하거나 특정 동작이 시작되는데 필요한 최소 조건이나 기준 등을 의미한다.
k8s의 문서를 참고하지 않고 Eviction Threshold라는 용어만 놓고 보면 Eviction Threshold는 특정 자원의 사용량이 정해진 값을 초과할 경우 파드를 강제로 내보내는 기준이라는 것으로 이해되었다.
그래도 혹시 몰라 쿠버네티스 공식 문서와 ChatGPT는 Eviction Threshold를 어떻게 설명하고 있는지 알아보았다. 공식 문서에서는 kubelet이 축출 여부 결정을 내릴 때 사용하는 축출 임계값을 사용자가 임의로 설정할 수 있다. 라는 의미로, ChatGPT는 노드의 특정 자원이 부족해지면 어떤 파드를 제거할지를 결정하는 기준값을 설정하는 것이다. 라는 의미로 설명해주었다.
Eviction Threshold 기본정보와 Soft 방식과 Hard 방식에 대해서
Eviction Threshold는 [eviction-signal][operator][quantity] 라는 형식으로 표현할 수 있다. 각 요소들에 대해서 자세히 살펴보면 eviction-signal에는 nodefs.available이나 memory.available과 같은 축출 신호를, operator에는 <와 같은 관계연산자를, quantity에는 %로 임계값 기준 수치를 기입하여 설정할 수 있다.
그리고 Eviction Threshold는 Soft 방식과 Hard 방식으로 구분된다. Soft 방식은 관리자가 별도의 유예시간을 설정해 줄 경우, kubelet이 해당 유예 시간이 초과될 때까지 파드를 추방하지 않는다. 이에 반해 Hard 방식은 별도의 유예 시간 없이 정해진 임계값 조건이 충족되면 파드를 즉시 추방시킨다. 또한, Hard 방식의 경우 아래와 같은 기본 임계값을 제공한다.
imagefs.available<15%
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%여기서 명시된 eviction-signal 정보에 대해서 자세히 살펴보자.
imagefs.available: 노드의 이미지 파일 시스템에서 사용 가능한 디스크 공간이 전체의 15% 미만이면 DiskPressure 상태를 True로 활성화하는 옵션이다. 여기서 이미지 파일 시스템은 실제 이미지가 저장되는 곳을 가리킨다.memory.available: 노드의 사용 가능한 메모리가 100MB 미만이면 MemoryPressure 상태를 True로 활성화하는 옵션이다. 이 상태가 True라면, kubelet은 메모리가 부족한 상태를 해결하기 위해 불필요한 파드를 종료하게 된다.nodefs.available: 노드의 파일 시스템에서 사용 가능한 디스크 공간이 전체의 10% 미만이면 DiskPressure 상태를 True로 활성화하는 옵션이다. 노드 파일 시스템은 파드가 사용하는 볼륨, 로그, 파드 체크포인트 등이 저장되는 곳을 가리킨다.nodefs.inodesFree: 노드의 파일 시스템에서 사용 가능한 inode가 전체의 5% 미만이라면 DiskPressure 상태를 True 상태로 활성화하는 옵션이다. inode는 파일 시스템에서 파일이나 디렉토리를 식별하는 데 사용하는 객체이다.
DiskPressure 원인 파악 완료!

위 옵션 정보를 읽자 마자, 필자의 문제와 직접적으로 관련된 부분이 바로 eviction-signal로 지정된 옵션 중 하나인 imagefs.available라고 느껴졌다. 왜냐하면 문제가 발생한 필자의 노드 내 이미지 파일 시스템은 /var/lib/containerd 경로로, 별도로 외부의 볼륨 디스크를 마운트하지 않았기 때문에 루트 파일 시스템에 포함된다. 결국, imagefs.available 옵션 기본값으로 인해 디스크 가용량이 15% 미만이면 Eviction이 동작하게 된다.
그렇게 해당 노드 루트 파일시스템의 사용량이 86%로 실제 가용량이 14%가 되어 임계값의 범위인 15% 미만이라는 조건에 부합되기에 kubelet이 디스크 공간 부족 문제라고 판단하고 Eviction을 동작시켰다는 것을 알 수 있었다.
Hard 방식으로 Eviction Threshold 조정하기
앞서 루트 파일시스템 디스크 용량 부족으로 Eviction이 동작하여 파드들을 추방시켰다는 사실을 알게 되었다. 이후, 별도로 마운트할 수 있는 볼륨 디스크를 할당받기로 전달을 받았지만, 외부의 볼륨 디스크를 할당받기까지 가만히 있기보다는, 임시로라도 직접 Eviction Threshold를 조정해 보고 싶다는 마음에 즉각적으로 조정한 임계값을 반영할 수 있는 Hard 방식을 적용하여 추방된 파드들을 정상화시켜보았다.
필자는 kubelet 설정 파일에 EvictionHard 값으로 imagefs.available 설정을 10%로 변경하여 이미지 파일 시스템의 사용 가능한 디스크 공간이 10% 미만일 경우에만 Eviction이 동작되도록 했다. 그 과정은 다음과 같다.
- kubelet 설정 파일을 찾기 위해 kubelet 서비스가 시작될 때 참조하는 설정 파일을 찾는다.
$ sudo vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS KUBELET_CONFIG_ARGS=--config옵션으로 지정된 경로의 kubelet 설정파일에 원하는 Eviction Threshold 값을 기입하여 반영한다.
$ sudo vi /var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
...
kind: KubeletConfiguration
...
# 마지막에 evictionHard 구문 추가
evictionHard:
imagefs.available: 10%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%💬 기본값 15%로 적용되된 imagefs.available 설정을 10%로 바꾸어 설정해주었고, 나머지 설정들은 그대로 기입하였다.
- kubelet을 재시작한다.
systemctl restart kubelet
systemctl status kubelet💬 항상 서비스를 중단하거나 재시작할 때는 status를 확인하는 것이 습관되었다.
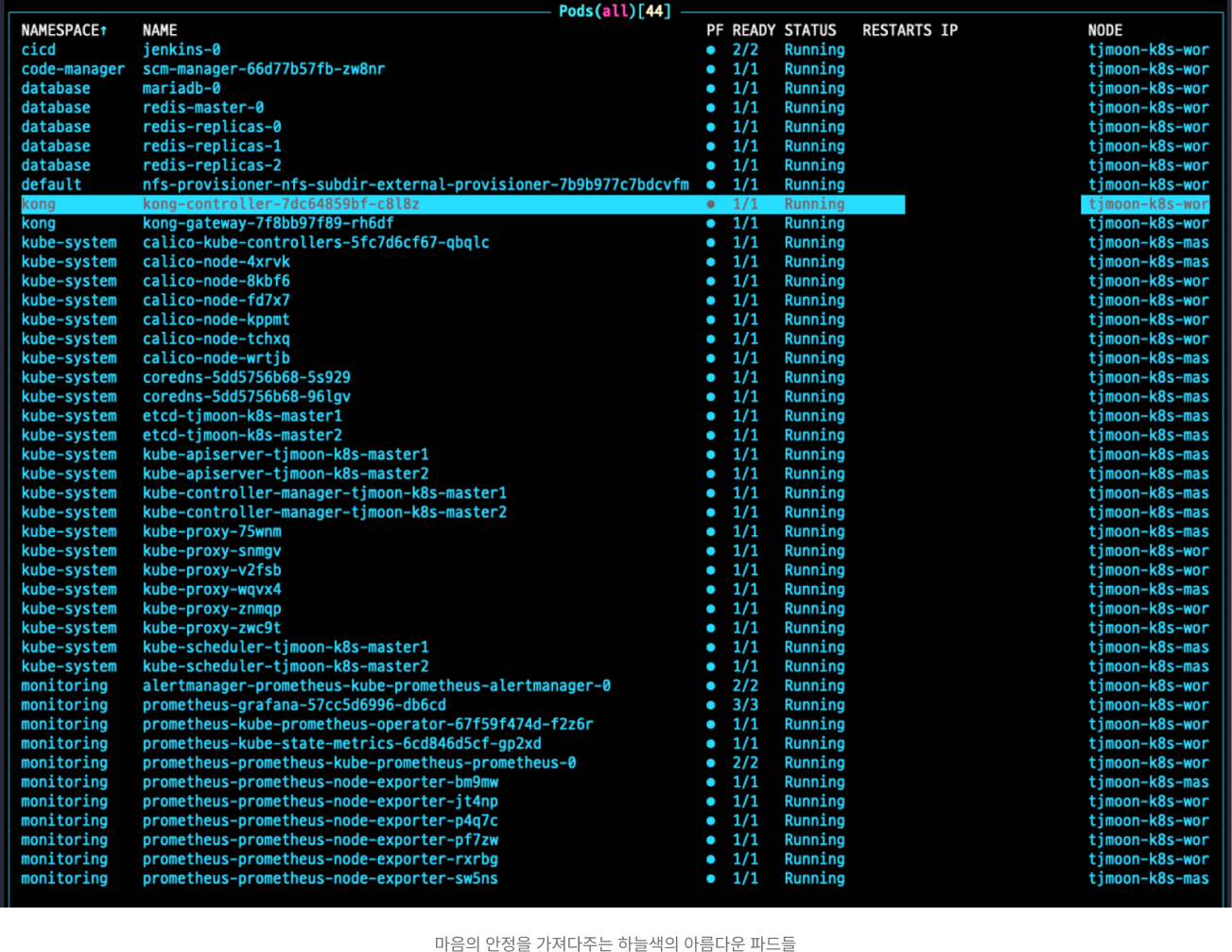
kubelet을 다시 시작하고 비정상적으로 동작하던 파드들을 모두 재시작해주니 클러스터의 모든 파드들이 정상화되었다.
👀 최초
Evicted되었던 Kong 파드와 kong-controller 파드명이 다른 것은 디스크 자원 문제가 아니고 Kong 릴리스가 잘못되었던 것으로 착각하여 다른 릴리스로 배포했기 때문에 이름이 다른 파드가 배포되었음을 알린다. 트러블 슈팅에 미숙하여 쓸데없는 시간을 낭비했다.
💡 간단 요약
- 루트 파일 시스템의 디스크 공간이 86%로 Eviction Threshold 기본값인 85%를 초과하여 발생한 문제임을 알게 되었다.
- Eviction Threshold의 Hard 방식으로 임계값을 조정했더니 Evicted 되었던 파드들이 정상화되었다.
파드의 추방(Eviction)을 막을 수 없다면?

Eviction이 동작하여 파드가 추방되는 것을 방지하기 위해 다음과 같은 방법을 생각해 보았다.
- 자원 디스크 공간 증설
- Eviction Threshold 조정
그런데 디스크 공간을 증설하지 못하는 상황을 간과할 수 없을뿐더러, Eviction Threshold를 조정하는 것도 일시적으로는 도움이 될 수 있지만, 장기적인 관점에서 보면 디스크 풀 상태가 되었을 때 동일한 문제가 발생하기에 적절한 해결책이라고 볼 수 없다. 그래서 만약에, 운용 중인 클러스터에서 핵심 비즈니스와 관련된 파드가 추방된다면 너무나 큰 문제일 것이다. 그래서 Eviction을 어쩔 수 없이 허용해야 할 경우, 그나마 덜 중요한 파드가 추방되는 것이 그나마 차선책이 될 것으로 보여진다.
파드의 우선순위 알아보기
필자의 클러스터에서 추방된 파드는 Kong 관련 파드이다. MariaDB나 Redis, Jenkins 파드도 실행 중이었는데 어째서 그 많은 파드 중 Kong 파드가 추방된 걸까? 이는 파드의 우선순위와 큰 관련이 있다. 파드의 우선순위란 말 그대로 파드의 중요도를 지정하는 것을 말한다. 파드의 우선순위에 대한 공식 문서의 설명은 다음과 같다.
💡 파드는 우선순위를 가질 수 있다. 우선순위는 다른 파드에 대한 상대적인 파드의 중요성을 나타낸다. 파드를 스케줄링할 수 없는 경우, 스케줄러는 우선순위가 낮은 파드를 선점(축출)하여 보류 중인 파드를 스케줄링할 수 있게 한다.
필자의 클러스터 내 파드들을 배포할 때 별도로 우선순위(Priority)를 지정하지 않았는데, 이로 인해 우선순위가 낮은 파드 중 하나인 kong 파드가 축출되었다고 예상해볼 수 있었다. 그렇다면 배포된 모든 파드들의 우선순위는 어떻게 지정되어 있을까?
$ kubectl get pods --all-namespaces -o jsonpath="{range .items[*]}{'\n'}{.metadata.name}{':\t'}{.spec.priority}{end}"
# jenkins-0: 0
# scm-manager-66d77b57fb-zw8nr: 0
# sonarqube-postgresql-0: 0
# sonarqube-sonarqube-lts-0: 0
# mariadb-0: 0
# redis-master-0: 0
# redis-replicas-0: 0
# redis-replicas-1: 0
# redis-replicas-2: 0
# nfs-provisioner-nfs-subdir-external-provisioner-7b9b977c7bdcvfm: 0
# kong-controller-7dc64859bf-c8l8z: 0
# kong-gateway-7f8bb97f89-rh6df: 0
# alertmanager-prometheus-kube-prometheus-alertmanager-0: 0
# prometheus-grafana-57cc5d6996-db6cd: 0
# prometheus-kube-prometheus-operator-67f59f474d-f2z6r: 0
# prometheus-kube-state-metrics-6cd846d5cf-gp2xd: 0
# prometheus-prometheus-kube-prometheus-prometheus-0: 0
# prometheus-prometheus-node-exporter-jt4np: 0
# prometheus-prometheus-node-exporter-l447k: 0
# prometheus-prometheus-node-exporter-p4q7c: 0
# prometheus-prometheus-node-exporter-pf7zw: 0
# prometheus-prometheus-node-exporter-rxrbg: 0
# prometheus-prometheus-node-exporter-sw5ns: 0 우선순위 값이 2000000000 혹은 2000001000로 지정된 Kubernetes 시스템 컴포넌트들을 제외한 Jenkins, Kong, MariaDB, Redis, SonarQube, NFS-Provisionor, Prometheus 파드들은 모두 0으로 동일한 우선순위 값으로 지정되어 있다.
이와 같이 파드의 우선순위와 같을 때는 QoS 클래스(Quality of Service class)나 우선순위(Priority)를 기반으로 축출 여부를 결정하는데 먼저 생성된 파드나 더 오랫동안 실행된 파드가 먼저 축출될 가능성이 높지만, 이는 쿠버네티스 내부 스케줄링 알고리즘에 의해 결정되는 사항이기에 항상 보장되지는 않는다고 생각한다. 사실 QoS 클래스와 우선순위를 고려한 동일 우선순위 축출 여부에 대해서는 추가적인 학습이 필요하다고 느껴져 이번 글에서는 자세히 다루지 않는다.
💡 QoS 클래스는 파드의 CPU 및 메모리 요청과 제한에 따라
Guaranteed,Burstable,BestEffort의 세 가지 클래스로 분류된다. Eviction(축출) 동작 시 ,BestEffort로 지정된 QoS 클래스의 파드가 가장 먼저 제거되며, 그 다음으로Burstable클래스의 파드가 제거된다.
그렇게 이번에 Eviction이 동작했을 때는 Kong 파드가 축출되었지만, 또 다음 Eviction이 동작하게 된다면 어떤 파드가 추방될지 알 수 없다는 것이 가장 치명적인 취약점이라는 생각이 들었다.
중요도가 높은 파드에게 우선순위 부여하기
필자 스스로 고민해 보고 운용 중인 파드의 우선순위를 매겨본 결과 Kong 파드는 Ingress Controller의 역할을 수행하여 클라이언트 요청을 클러스터 내부 서비스로 라우팅해야 한다. 그래서 Kong 파드가 축출될 경우, 클러스터 운용에 큰 문제가 생길 것으로 판단하여 일반적으로 애플리케이션 운영에 직접적인 영향을 미치지 않는 모니터링 도구인 Prometheus 및 Grafana 파드의 우선순위를 낮게 조정하려 한다.
공식 문서 가이드를 따라 PriorityClass를 생성하여 부여하기 전 기존의 PriorityClass를 조회해보았다. 쿠버네티스는 기존에 system-cluster-critical 과 system-node-critical라는 두 개의 PriorityClass를 제공한다. 이들은 지금 무시해도 무방하다.

바로 Kong 파드의 우선순위를 부여해줄 PriorityClass해당 매니페스트 파일을 작성하고 배포하여 PriorityClass를 생성해주자.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-kong
value: 1000000
globalDefault: false
description: "이 프라이어리티클래스는 Kong 서비스 파드에만 사용해야 한다."
이후 Kong 파드의 메니페스트에 앞서 배포한 high-priority-kong 정보를 명시해주어야 하는데 필자의 Kong 파드는 Helm을 이용해 설치 및 배포했기 때문에 pull 받아온 릴리스 정보가 담긴 values.yaml 파일에 명시해주었다.
controller:
priorityClassName: high-priority-kong위와 같이 Kong 릴리스 정보를 변경한 후 helm upgrade 명령을 통해 kong 릴리스를 재배포 해주었더니 정상적으로 만들어준 PriorityClass 정보가 반영되어 1000000이라는 우선순위 값을 지닌 Kong 파드로 배포되었다.

Kong 파드의 우선순위 정보가 변경되었으니 추후 예상치 못한 Eviction이 발생했을 경우 서비스 라우팅을 담당해야할 Kong 파드는 우선순위가 지정되지 않은(우선순위 값이 0인) 파드들 보다 축출 우선순위 대상에서 멀어졌다고 볼 수 있다.
마치며
쿠버네티스 클러스터 운영에 필요한 노드 자원의 리소스가 충분했다면 이번 Eviction Treshhold와 관련된 이슈는 영영 만나지 못했을 지도 모른다. 오히려 클러스터 운영시 자주 겪을 수 있는 문제라고 느껴지니 재미있게 트러블 슈팅 과정에 몰입했던 것 같다.
아직도 쿠버네티스에 대한 러닝 커브는 산처럼 느껴진다. 단순히 하나의 애플리케이션을 개발하는 관점과는 보다 고차원적인 부분들이 많아 이해력을 늘리는 비용이 많이 들지만, 클러스터 내부 핵심 워크로드 리소스나, 객체들에 대해서 이론적으로 추상적이었던 내용들을 직접 클러스터를 구축해보며 어느 정도 구체화해가고 있는 것 같다.
참고자료
