
들어가며
이번에 저희 팀에서 기존에 운용하던 모니터링 환경에 경고 관리 환경을 확장하기로 하여 설계하여 개발하고 있어요. 이번 글에서는 경고 관리 환경을 구성하며 시도했던 PoC 과정을 간단하게 소개해 보려 합니다.
문제 간단하게 살펴보기

현재 실무에서 개발하고 있는 프로젝트에서는 CI/CD 파이프라인 기능을 제공합니다. 그래서 운영 중인 서버 애플리케이션에서 Jenkins와 ArgoCD를 연계하는 비즈니스 로직이 포함되어 있지요. 그 외에도 소스 형상 관리, 이미지 관리, 정적 분석 등을 위해 GitLab, Harbor, SonarQube와도 어느 정도 결합되어 있습니다.
그러나 주요 기능을 제공하는 서버와 달리, 연계된 미들웨어들은 장애를 빠르게 탐지하고 대응하기 어려운 구조로 구축되어 있어서 언젠가는 이 문제를 해결해야 했어요. 그래서 이번 기회에 팀에게 해당 문제를 공유했고 “클라이언트를 통해서 감지하는 것은 너무 느리니, 인프라 레벨에서 신속하게 장애를 감지할 안전 장치를 마련하자”는 의견을 제안했어요. 이를 개발 티켓으로 할당받아 미들웨어 통합 경고 관리 방안을 모색하게 되었답니다.
그 과정에서 Prometheus와 AlertManager를 활용해 연계된 미들웨어들의 메트릭을 모니터링하여 자동화된 경고 관리 환경을 기획하고 설계하게 되었어요.
요구사항 정의하기
문제가 무엇인지 파악한 후에는 현재 상황을 기준으로 어떤 문제를 중점으로 해결할 것인지 트레이드 오프를 고려해야 했죠. 솔루션 설계를 위한 요구사항을 구체적으로 리스트업 해보았어요.
장애 탐지 속도 향상
기존의 미들웨어들은 애플리케이션의 클라이언트를 통해 감지된 장애나 인프라 담당자를 통해서만 문제를 파악할 수 있었습니다. 이는 문제가 발생한 후 이슈를 파악하기까지 시간이 오래 걸려 대응 속도가 느려지는 원인이 되었지요. 장애를 탐지하는 시간을 줄이기 위해, 인프라 레벨에서 미들웨어의 메트릭을 빠르게 모니터링할 수 있어야 합니다.
물론 장애가 발생했을 때, 경고 알림을 전달한다고 해서 장애를 해소시킬 수는 없어요. 다만, 장애를 신속히 파악하고 운영팀이 즉각 대응할 수 있게 하여 운영 환경 서비스의 회복 탄력성을 강화하는 역할을 해주어야 합니다.
중앙화된 경고 관리 체계
Jenkins, ArgoCD, GitLab 등 다양한 미들웨어를 사용하고 있지만, 각 시스템에서 독립적으로 장애 알림을 설정하고 관리하게 된다면 확장 및 유지보수 측면에서 꽤나 골치 아픈 일이 될 수 있어요. 그래서 중앙에서 모든 미들웨어의 경고를 한 곳에서 통합하여 관리할 수 있는 환경이 필요합니다.
유연한 경고 정책 설정
미들웨어마다 수집할 수 있는 주요 메트릭 형태는 다르기에 관리자 입장에서 경고 정책을 유동적으로 설정할 수 있어야 해요. Jenkins에서는 빌드 큐의 크기나 실행 중인 작업의 수를, ArgoCD에서는 애플리케이션 동기화 상태 등 각각의 미들웨어가 제공하는 고유한 메트릭들이 존재합니다.
이러한 다양한 메트릭들에 대해 운영 상황과 요구사항에 맞춰 경고 임계값과 조건을 손쉽게 조정할 수 있어야 합니다. 또한 경고 정책의 변경이 시스템에 즉시 반영되어야 하며 이 과정에서 발생하는 운영 부담이 최소화되어야 합니다.
경고 실용성 고려
단순히 많은 경고 알림을 생성하여 전달하는 것보다는, 실제로 대응이 필요한 중요한 경고만을 효과적으로 전달해야 해요. 너무 과다하게 많은 경고 알림은 오히려 중요한 경고를 놓칠 가능성이 커집니다.
중요한 경고를 놓치지 않도록 경고의 우선순위를 두거나, 같은 레벨의 경고를 어떤 기준으로 그룹화할 것인지 등을 잘 따져봐야 합니다.
요구사항을 좀 더 쉽게 정리하자면, 아래와 같이 표현할 수 있을 것 같아요.
"효과적인 미들웨어 장애 관리를 위해 신속한 장애 탐지, 중앙화된 경고 관리, 유연한 정책 설정, 그리고 실용적인 알림 전달을 갖춘 경고 관리 체계가 필요하다."
솔루션 분석
기존의 모니터링 시스템을 다시 한 번 리뷰하면서 요구사항을 만족하기 위한 두 가지 방안을 제안할 수 있었는데요. 현재 프로젝트 마감 기한이 많이 남지 않았기 때문에 현재 상황에서 쉽고 빠르게 개발할 수 있는 솔루션을 찾아야 했어요. 그리고 기존 모니터링 환경을 그대로 이용할 수 있는지도 중요하게 생각했습니다.
✅ Prometheus와 AlertManager 연계
프로메테우스와 AlertManager를 연계하는 방식은 기존 개발환경에 큰 공수없이 쉽게 시작할 수 있는 선택이었어요. 이미 프로메테우스를 통해 메트릭을 수집하고 있었기 때문에, AlertManager를 추가로 확장하는 것이 가장 가성비가 좋다고 판단했어요.
- 프로메테우스 오퍼레이터를 통해 PrometheusRule CR 관리가 가능하여 동적 설정이 용이하며, 경고 규칙 변경 시 프로메테우스 재시작 없이 자동으로 반영된다.
- 쿠버네티스 API를 활용한 경고 정책 CRUD 작업이 가능하다.
- 참고할 레퍼런스가 Grafana + AlertManager와 비교했을 때 상대적으로 많다.
❌ Grafana와 AlertManager 연계
Grafana를 통한 통합 관리도 매력적인 선택지였어요. 이미 구성된 모니터링 환경에는 Loki-Stack을 통해 Grafana 대시보드로 로그 정보를 시각화하고 있었기 떄문에, 단순히 메트릭뿐만 아니라 로그에 대한 경고 정책까지 통합하여 관리할 수 있겠다고 생각했습니다.
- 로그(Loki)와 메트릭(Prometheus) 모두를 Grafana에서 통합 관리하면 경고 관리 범위 확장이 용이하다.
- 그라파나 UI 기반 설정으로 인해 쉽고 직관적이지만, 제한적이다.
- 참고할 레퍼런스가 많지 않다.
저는 Prometheus와 AlertManager 연계하는 방식을 선택했어요. Prometheus Operator가 지원하는 PromethuesRule 기반으로 경고 정책을 런타임 환경에서 Kubernetes API로 제어할 수 있는 이점이 매력적으로 느껴졌기 때문이에요. PrometheusRule CR를 통한 경고 정책 관리는 앞서 정의한 '유연한 경고 정책 설정'이라는 핵심 요구사항을 완벽히 충족시킬 수 있다고 판단했기 때문입니다.
시스템 아키텍처 구조
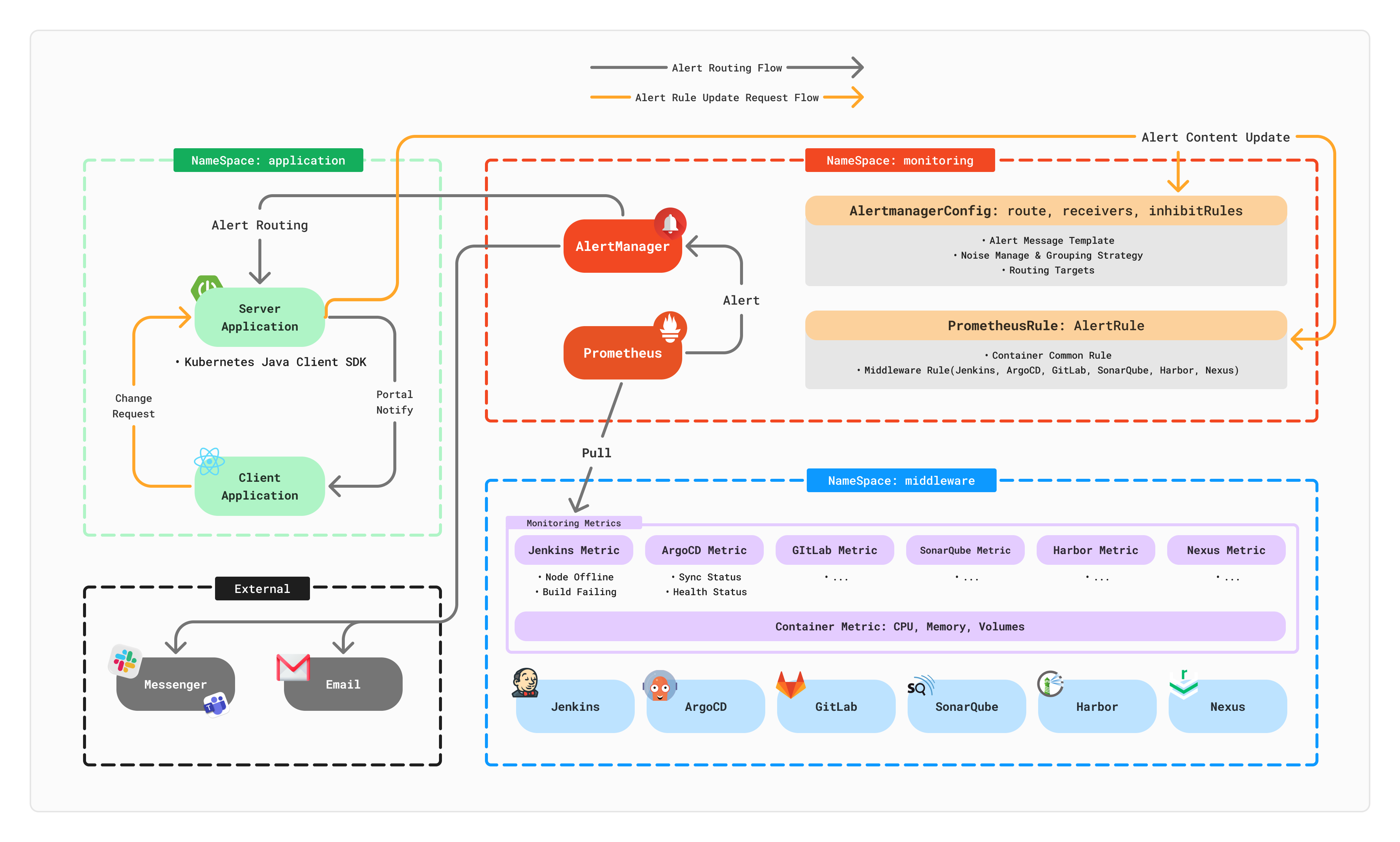
요구사항을 토대로 나름대로 경고 관리 환경 아키텍처를 도식화 해보았어요. 설계 초안이라 허술한 점이 많지만, 앞으로 개선할 점을 좀 더 편하고 쉽게 확장할 수 있는 관점에서 고민하고 그렸던 것 같아요.
- Prometheus:
- 운용 컨테이너 공통 메트릭 및 미들웨어별 주요 메트릭 수집
- 메트릭 기반의 경고 정책(PrometheusRule CR) 관리
- AlertManager:
- 경고 메시지 템플릿, 그룹화 전략, 알림 노이즈 방지, 라우팅 대상지 관리를 위한 알림 설정 (AlertManagerConfig CR) 관리
- Linked Server Applcation:
- Kubernetes Java Client SDK 활용
- 경고 정책(PrometheusRule CR) 변경 관리
- 알림 설정(AlertManagerConfig CR) 변경 관리
미들웨어 통합 경고 관리 환경 구성하기
어느 정도 요구사항과 실행계획을 세운 후에는 요구사항을 정말 만족할 수 있는지 빠르게 테스트 환경을 구성하고 싶어서 프로젝트의 CI/CD 파이프라인 기능을 제공하는 주요 미들웨어 중 하나인 Jenkins만을 대상으로 경고가 잘 전달되는지에 대한 PoC를 진행해 봤어요.
테크 스펙
해당 작업에서 사용한 주요 시스템들의 버전은 다음과 같습니다.
- Kubernetes:
v1.30.4- kube-prometheus-stack:
v0.79.2
- Prometheus
v3.1.0- AlertManger:
v0.27.0- Jenkins:
v2.462.3- ArgoCD:
v2.12.4
Prometheus 및 AlertManager 설정하기
먼저 kube-prometheus-stack 헬름 차트를 통해 프로메테우스 오퍼레이터를 배포합니다. Prometheus와 AlertManager 모두 기본 형상을 그대로 사용했어요.
특히, kube-prometheus-stack 헬름 차트에서는 ServiceMonitor와 PrometheusRule을 감지하는 방식을 ruleSelectorNilUsesHelmValues와 serviceMonitorSelectorNilUsesHelmValues로 제어할 수 있는데요. 이 두 값은 차트 기본 값을 유지하여 배포했어요.
# 헬름 차트 기본 값 유지
prometheus:
prometheusSpec:
ruleSelectorNilUsesHelmValues: true
serviceMonitorSelectorNilUsesHelmValues: true
ruleSelectorNilUsesHelmValues속성은 프로메테우스가 ServiceMonitor 리소스를 감지할 때 Helm 차트 값의 serviceMonitorSelector를 사용할지, 아니면 모든 ServiceMonitor를 감지 할지를 결정합니다.ruleSelectorNilUsesHelmValues속성도 동일하게 Helm 차트의 ruleSelector 값을 무시할지 말지를 결정해요.
그래서 해당 속성의 값이 false가 되면 헬름 차트에서 설정한 값이 무시되어서 모든 네임스페이스에서 ServiceMonitor나 PrometheusRule 리소스를 자동으로 탐지하고 수집 대상에 추가하게 되어요. 그런데 출처도 모르는 커스텀 리소스를 자동으로 등록하는 것은 리스크가 있다고 판단해서 차트 기본 값 유지하기로 결정했습니다.
Jenkins 메트릭 수집 설정하기
먼저 젠킨스 시스템의 메트릭을 수집하기 위해서는 두 가지 설정이 필요합니다.
- 프로메테우스 메트릭 플러그인 설치
- ServiceMonitor 활성화
프로메테우스 메트릭 플러그인 설치
Prometheus metrics plugin을 설치한 후 젠킨스를 재구동 해줍니다. 이 후, /prometheus 엔드포인트로 curl 명령을 호출해보면 정상적으로 메트릭 정보를 조회할 수 있어요.
# TYPE default_jenkins_version_info gauge
default_jenkins_version_info{version="2.462.3",} 1.0
# HELP default_jenkins_up Is Jenkins ready to receive requests
# TYPE default_jenkins_up gauge
default_jenkins_up 1.0
# HELP default_jenkins_uptime Time since Jenkins machine was initialized
# TYPE default_jenkins_uptime gauge
default_jenkins_uptime 386816.0
# HELP default_jenkins_nodes_online Jenkins nodes online status
# TYPE default_jenkins_nodes_online gauge
...ServiceMonitor 활성화
메트릭을 수집할 수 있도록 엔드포인트를 개방했으니 프로메테우스가 젠킨스의 메트릭을 모니터링할 수 있도록 해주어야 겠죠? Jenkins 헬름 구성에서 prometheus.enabled 속성을 true로 변경하여 모니터링 대상이 될 수 있도록 합니다.
그리고 prometheus.serviceMonitorNamespace 속성에는 프로메테우스가 배포된 네임스페이스를 기입합니다. 프로메테우스에서 serviceMonitorSelectorNilUsesHelmValues: false 설정으로 인해 모든 네임스페이스를 감시하여 ServiceMonitor를 자동으로 만들어 주기 때문에 젠킨스의 prometheus.serviceMonitorNamespace 속성을 기입할 필요는 없으나 ServiceMonitor 리소스를 프로메테우스와 같은 네임스페이스에서 관리하기 위해 명시적으로 선언했어요.
prometheus:
enabled: true
serviceMonitorNamespace: "monitoring"이렇게 두 가지 설정을 마치면, 프로메테우스 UI 웹 콘솔의 Target health 메뉴에서 젠킨스에 대한 ServiceMonitor 리소스를 찾아볼 수 있습니다.
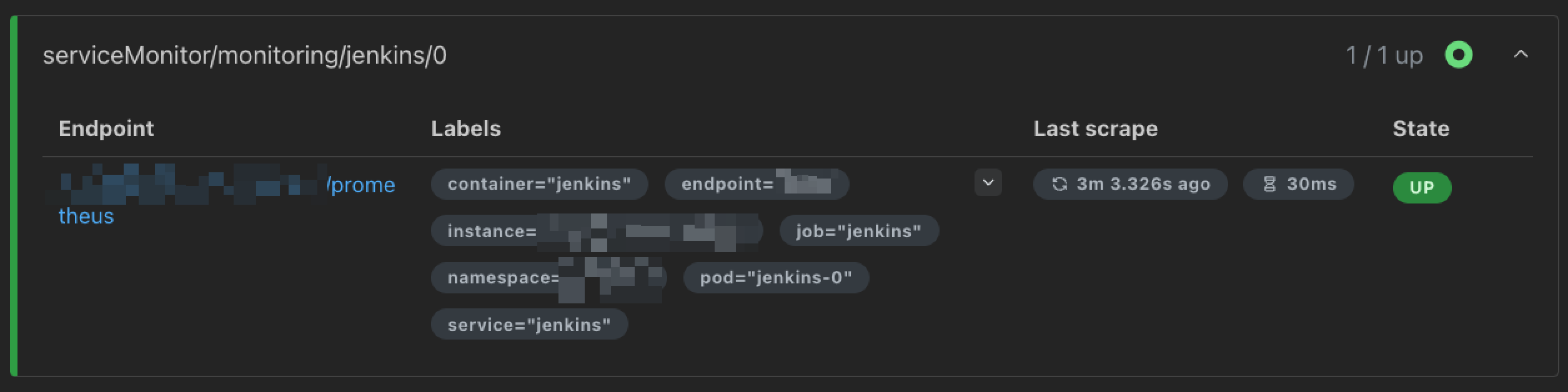
Q. 젠킨스에서 프로메테우스 메트릭 플러그인을 설치하지 않고 그냥 ServiceMonitor만 개방하면 되는거 아닐까?
ServiceMonitor만 생성해주면 프로메테우스에서 젠킨스의 메트릭을 알아서 추적해줄 것이라고 충분히 생각할 수 있겠네요. ServiceMonitor는 단지 프로메테우스에게 "여기서 메트릭을 수집하세요"라고 알려주는 설정일 뿐, 실제로 메트릭을 수집하도록 하지는 않습니다.
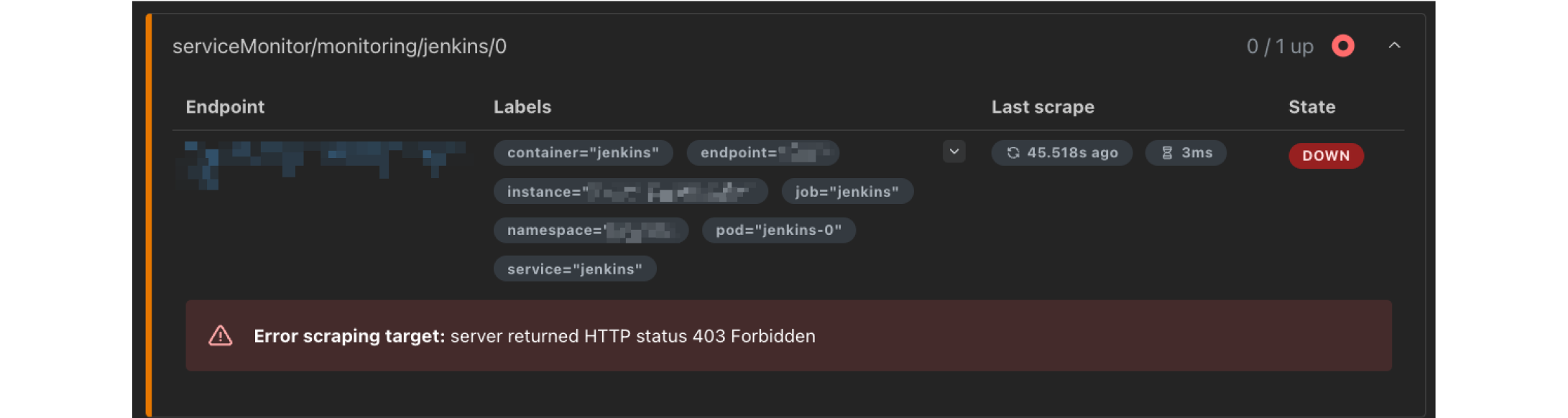
실제로 플러그인은 사용하지 않고 ServiceMonitor만 활성화하게 되면 위와 같이 프로메테우스 모니터링 대상으로 등록은 되어있지만, 메트릭을 수집할 수 없게 됩니다. 그래서 프로메테우스 메트릭 플러그인을 설치하여 젠킨스의 메트릭을 수집할 수 있도록 설정한 후, ServiceMonitor를 통해 프로메테우스가 자동으로 모니터링 대상으로 등록하도록 해야 합니다.
💡 프로메테우스 네이티브를 사용하는 경우 젠킨스 모니터링 대상을 직접 프로메테우스 스크랩 설정에 추가해야만 모니터링 대상으로 등록이 가능했는데요. 프로메테우스 오퍼레이터는 쿠버네티스의 선언적 방식을 활용하기 때문에 젠킨스에서 ServiceMonitor라는 커스텀 리소스를 생성해주면 프로메테우스가 자동으로 모니터링 대상으로 추가해줍니다.
ETC. ArgoCD 메트릭 수집 설정하기
별도로 플러그인을 설치해야 했던 Jenkins와 달리, ArgoCD는 기본적으로 메트릭 엔드포인트를 노출하고 있기 때문에 ServiceMonitor만 활성화하면 프로메테우스가 메트릭을 수집할 수 있게 됩니다. ArgoCD는 쉽게 설정할 수 있었기 때문에 함께 설정했어요.
ServiceMonitor 활성화
ArgoCD에는 Jenkins와 동일한 이유로 네임스페이스를 프로메테우스가 배포된 네임스페이스로 지정했어요. 그리고 dex 서버를 제외한 모든 리소스 내 ServiceMonitor 속성을 활성화하는 명세를 추가했어요.
- Application Controller
- Repo Server
- Server
- ApplicationSet Controller
- Notifications Controller
- Redis (Metrics)
# dex 서버를 제외한 모든 리소스에 적용
serviceMonitor:
enabled: true
namespace: "monitoring"
additionalLabels:
release: "prometheus" 💬 Dex 서버는 SSO 기능을 제공하는 컨테이너입니다. 기본적으로 http-metric 포트를 개방하지 않는 것인지, ServiceMonitor를 생성해도 프로메테우스 Targets로 등록되지 않는 이슈가 있었습니다. 그래서 임시로 Dex 서버의 ServiceMonitor는 비활성화해 두었어요.
설정을 완료하고 ArgoCD를 재배포하니 프로메테우스에서 정상적으로 노출되네요.
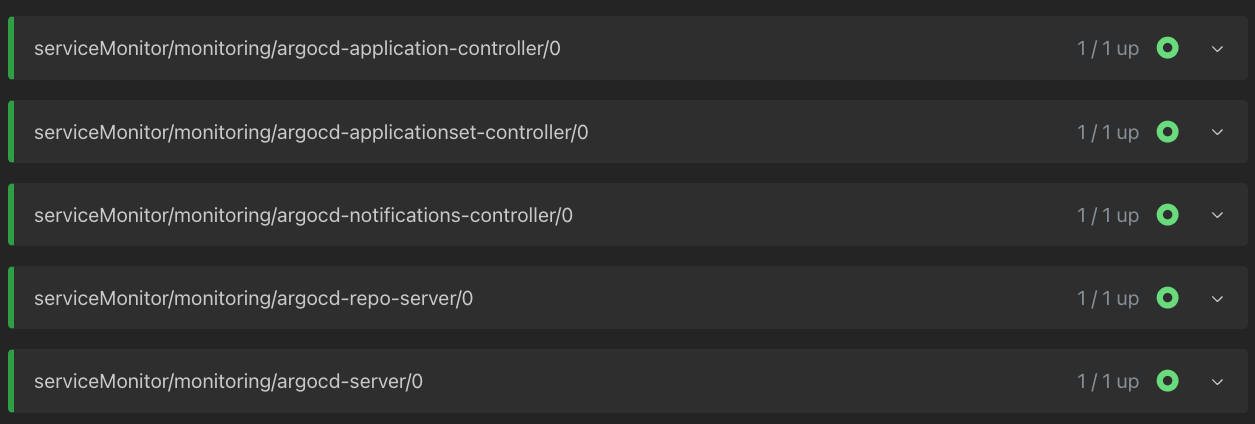
PrometheusRule Custom Resource로 경고 정책 정의하기
이제 프로메테우스에서 Jenkins의 메트릭을 수집하고 있으니 수집한 메트릭을 가지고 경고 정책을 세워볼까요? 유연한 경고 정책 설정이라는 요구사항을 위해서 PrometheusRule 타입의 커스텀 리소스를 생성합니다.
PoC 단계이기에 경고 지속 시간을 오래 두지 않고 즉시 경고를 발생시키기 위해 for는 모두 0m으로 설정했습니다.
Jenkins 경고 정책 CR 작성
Jenkins 경고 정책을 포함하는 커스텀 리소스를 작성하여 반영했어요. 경고 조건은 일단 하나만 넣어봤습니다.
- 경고 조건: 마스터 노드와 슬레이브 노드 중 1개 이상의 노드가 오프라인 상태일 경우 즉시 경고 발생!
# jenkins-alerts.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: jenkins-alerts
namespace: monitoring
labels:
release: prometheus
spec:
groups:
- name: jenkins-alerts
rules:
- alert: Jenkins Node Offline
expr: jenkins_node_offline_value >= 1
for: 0m
labels:
severity: critical
annotations:
summary: Jenkins is Down - offline (instance {{ $labels.instance }})
description: "Jenkins 노드 {{ $labels.instance }}가 오프라인 상태입니다. 현재 오프라인 노드 수: {{ $value }}대"Jenkins와 경고 정책 리소소를 반영해준 후, 프로메테우스에서 감지하는지 확인해볼게요.
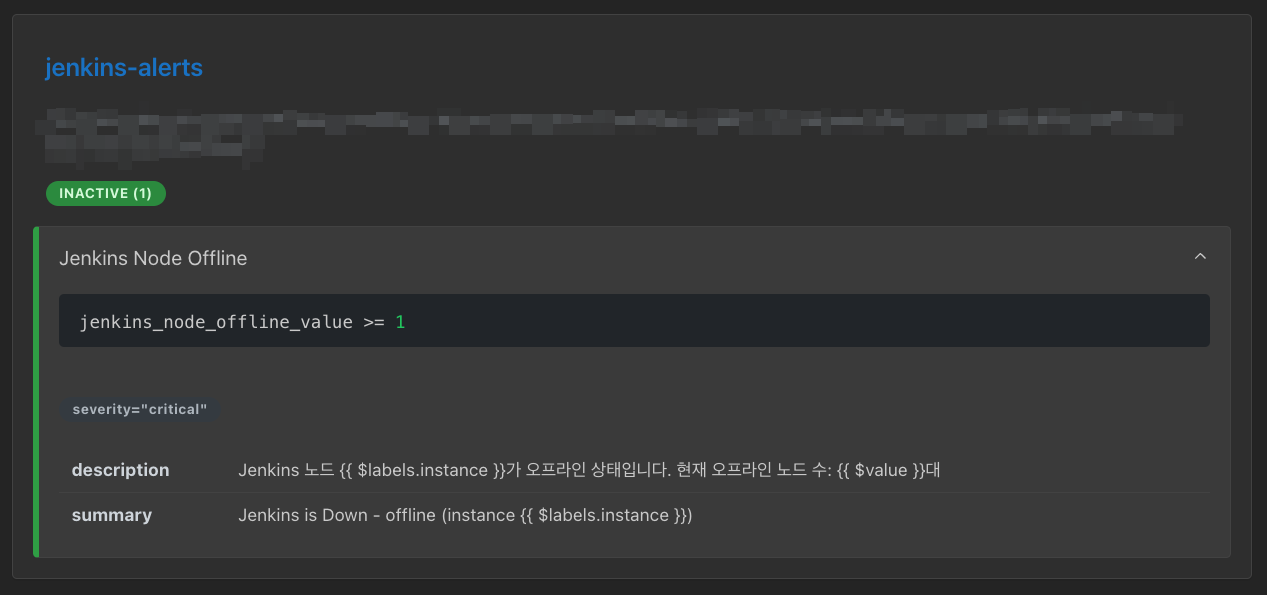
Jenkins-alerts라는 경고 정책 CR가 정상적으로 노출됩니다.
ETC. ArgoCD 경고 정책 CR 작성
ArgoCD 경고 정책은 2가지 정도를 등록했어요.
- 경고 조건:
- 동기화되지 않은 애플리케이션이 1개 이상일 경우 즉시 경고 발생!
- 모든 애플리케이션 중 하나라도 Healthy하지 않은 애플리케이션이 있을 경우 즉시 경고 발생!
# argocd-alerts.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: argocd-alerts
namespace: monitoring
labels:
release: prometheus
spec:
groups:
- name: argocd-alerts
rules:
- alert: Argocd Service NotSynced
expr: count(argocd_app_info{sync_status!="Synced"}) >= 1
for: 0m
labels:
severity: warning
annotations:
summary: ArgoCD Application Not Synced (instance {{ $labels.instance }})
description: "ArgoCD 애플리케이션이 동기화되지 않은 상태입니다. 애플리케이션: {{ $labels.name }} 현재 상태: {{ $labels.sync_status }} 네임스페이스: {{ $labels.namespace }} 미동기화된 애플리케이션 수: {{ $value }}개"
- alert: Argocd Service Unhealthy
expr: argocd_app_health_status{health_status!="Healthy"} == 1
for: 0m
labels:
severity: critical
annotations:
summary: ArgoCD Service Unhealthy (instance {{ $labels.instance }})
description: "ArgoCD 서비스가 비정상 상태입니다. 애플리케이션: {{ $labels.name }} 현재 상태: {{ $labels.health_status }} 네임스페이스: {{ $labels.namespace }} 프로젝트: {{ $labels.project }}"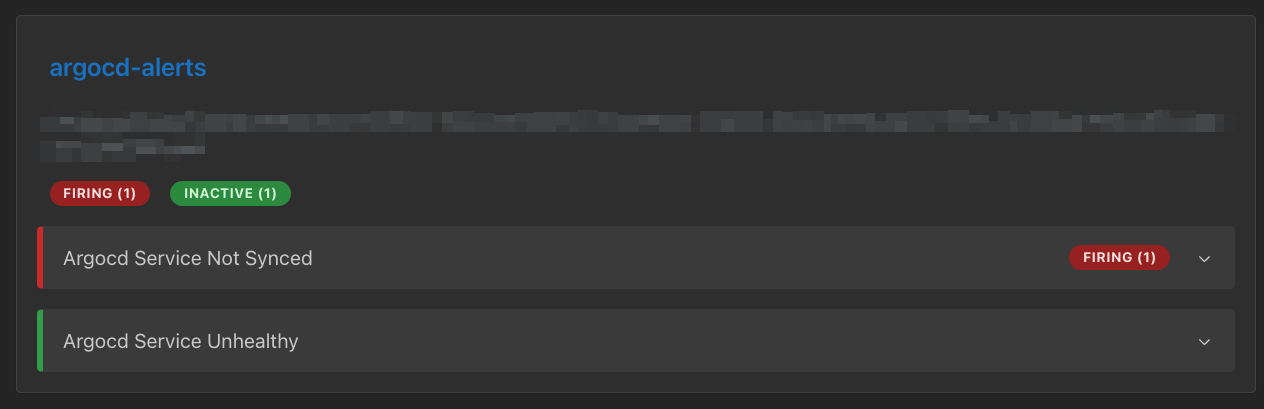
번외도 올려두었던 argocd-alerts도 잘 적용되었네요. 심지어 Not Synced 경고는 기존에 Sync되지 않은 애플리케이션들이 있어서 바로 경고 상태가 Firing로 변해있네요.
경고 발생 여부 테스트
그렇다면 저희가 정한 경고 정책에 임계치에 따라 inactive 상태의 경고가 Pending 상태를 넘어 Firing 상태로 변하게 되는지 테스트 해봅시다. 여기서는 ArgoCD는 제외하고, Jenkins 경고 정책이 제대로 반영되는지만 보겠습니다.
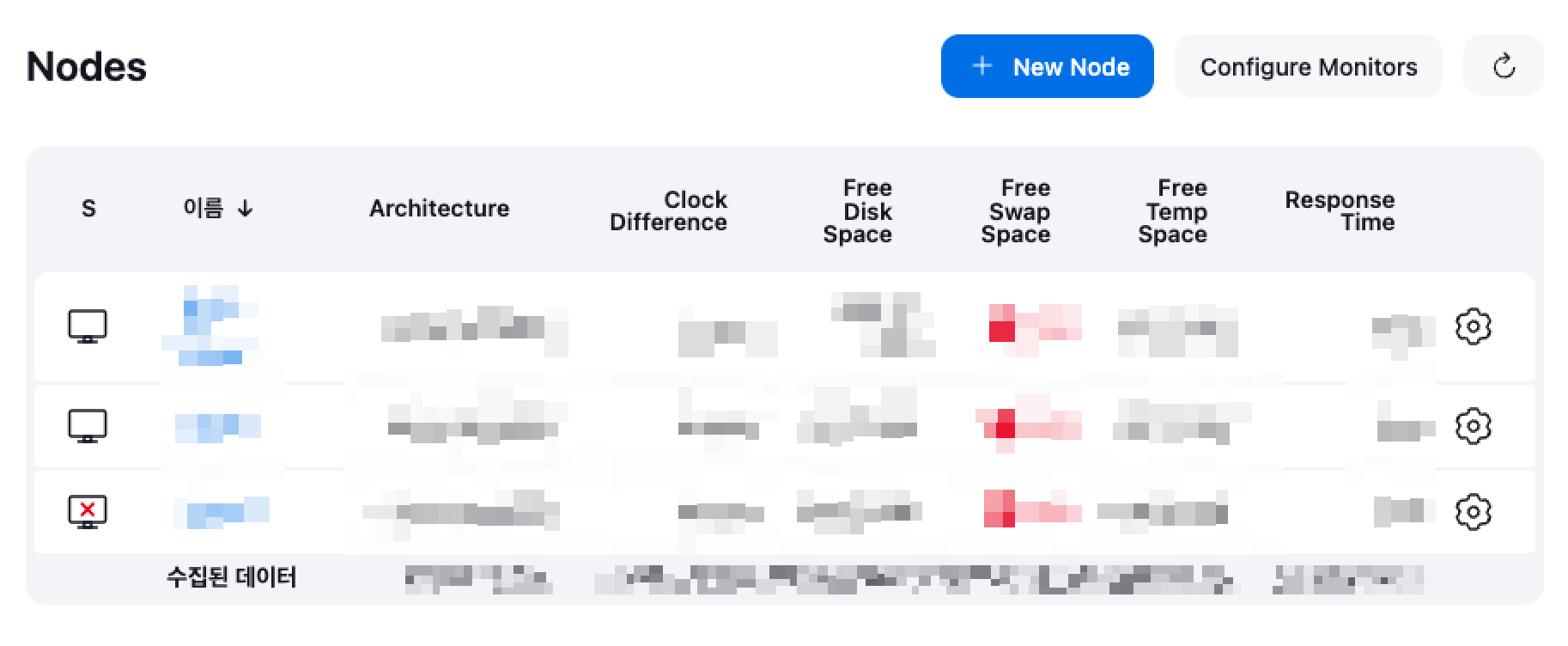
젠킨스의 슬레이브 노드 중 하나의 노드를 임시로 오프라인 상태로 변경합니다.
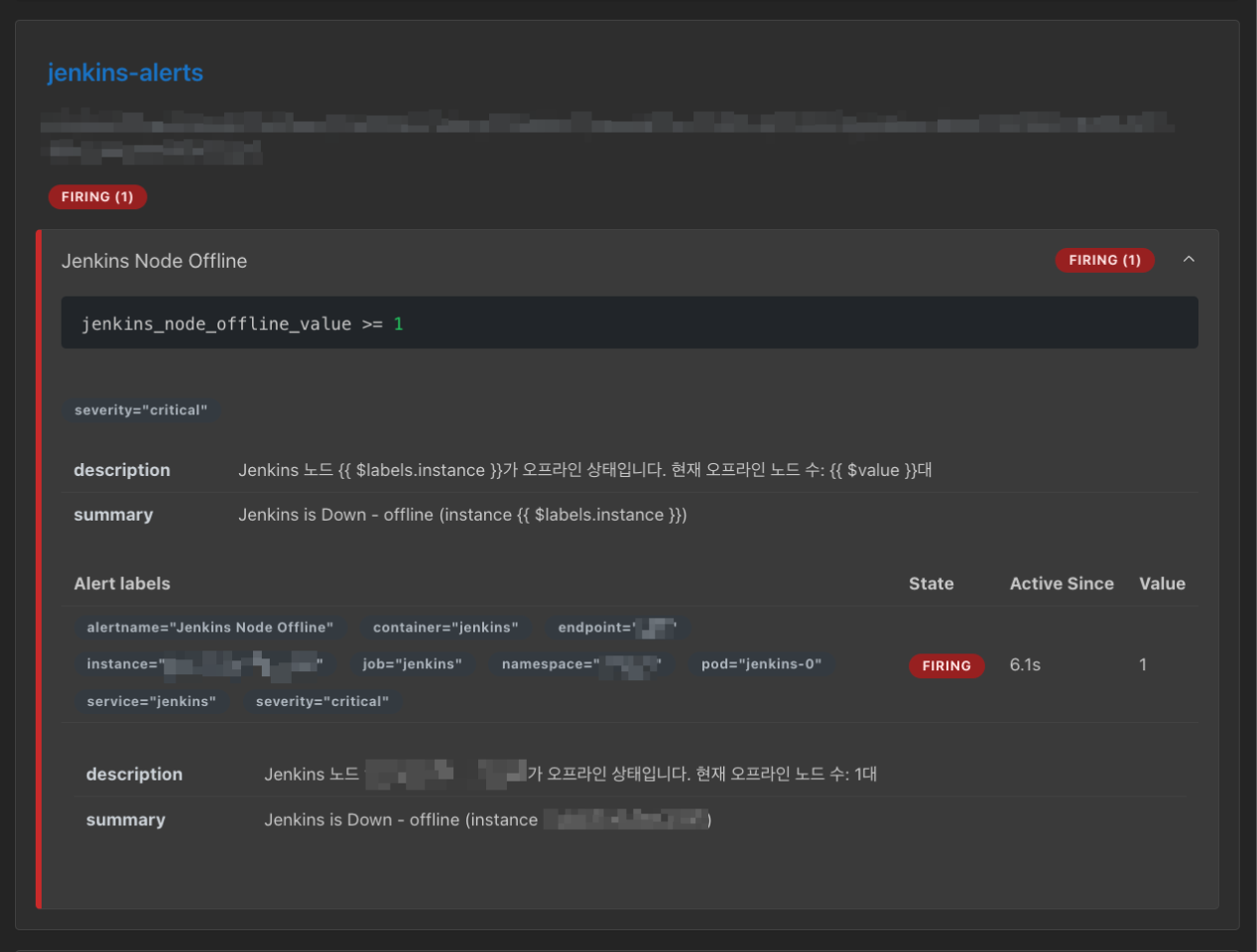
이후 프로메테우스의 Alerts를 다시 확인해보면, inactive 상태였던 jenkins-alerts가 firing 상태로 변경된 것을 알 수 있어요.
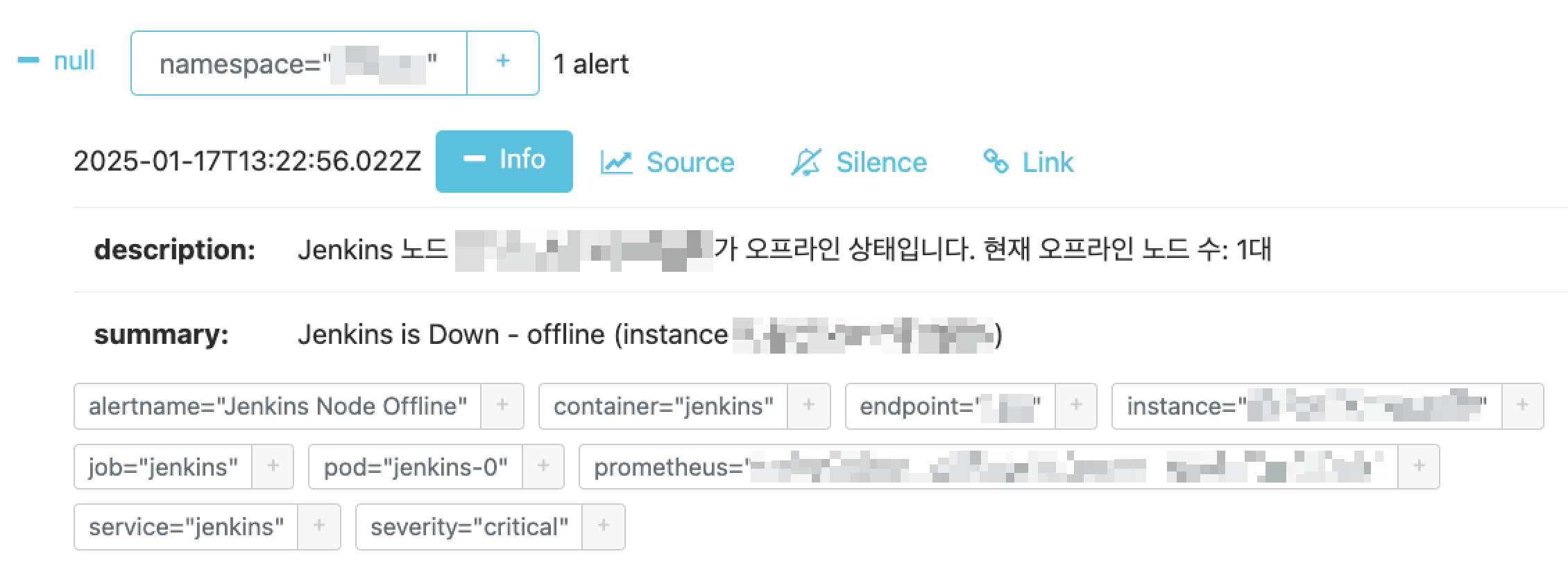
마지막으로 발생한 경고가 AlertManager까지 잘 전달되었음을 볼 수 있네요.
AlertmanagerConfig CR로 수신 설정 정의하기
프로메테우스가 Jenkins의 메트릭을 감지하여 경고 정책에 설정된 조건을 만족할 경우 경고를 발생시켜 AlertManager까지 전달되었으니 이제 클라이언트에게 알림을 전달해볼 수 있을 것 같아요.
# alertmanager-messenger-config.yaml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: alert-config
namespace: monitoring
labels:
release: prometheus
spec:
# 라우팅 규칙 설정
route:
groupBy: ['alertname', 'namespace', 'severity'] # 경고들을 분류하는 그룹화 기준을 정의
groupWait: 30s # 첫 경고 발생시 대기 시간, 해당 시간동안 쌓인 경고 한 번에 전송
groupInterval: 5m # 같은 그룹의 다음 알림까지 대기 시간
repeatInterval: 4h # 해결되지 않은 경고를 다시 알리는 반복 주기 시간
receiver: alert-notifications
routes:
- receiver: alert-notifications
matchers:
- name: severity
value: critical
- receiver: alert-notifications
matchers:
- name: severity
value: warning
# 대상지(수신자) 설정
receivers:
- name: alert-notifications
# 슬랙 웹훅 설정 - 시크릿 주입
slackConfigs:
- apiURL:
name: slack-webhook
key: url
channel: '#2_웹훅'
sendResolved: true
title: |-
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .CommonLabels.alertname }}
text: |-
*Alert Details:*
• Severity: {{ .CommonLabels.severity }}
• Description: {{ .CommonAnnotations.description }}
{{- if .CommonLabels.instance }}
• Instance: {{ .CommonLabels.instance }}
{{- end }}
{{- if .CommonLabels.namespace }}
• Namespace: {{ .CommonLabels.namespace }}
{{- end }}AlertmanagerConfig CR에는 라우팅 규칙과 대상지 설정, 메시지 템플릿을 명세했어요.
route:
groupBy: ['alertname', 'namespace', 'severity'] # 경고들을 분류하는 그룹화 기준 특히, route.groupBy 속성에는 경고들을 분류하는 그룹화 기준을 정의해요. 예를 들어, Jenkins Node Offline이라는 경고가 monitoring 네임스페이스에서 critical 심각도 수준으로 발생했다면, 이 세 가지 기준이 동일한 다른 경고들과 함께 그룹화됩니다.
slackConfigs:
- apiURL:
name: slack-webhook
key: url
channel: '#2_웹훅'
sendResolved: true 그리고 경고 라우팅 대상지는 슬랙으로 테스트를 진행했어요. 2_웹훅이라는 채널로 경고 알림을 전달하도록 설정했고, 슬랙 URL은 시크릿으로 관리하고 있어서 시크릿의 url 값으로 주입하도록 설정했습니다. 그리고 sendResolved 속성을 true로 설정하여 장애가 해결되었을 경우 해결 상태(Resolved) 알림을 제공할 수 있도록 했어요.
title: |-
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .CommonLabels.alertname }}
text: |-
*Alert Details:*
• Severity: {{ .CommonLabels.severity }}
• Description: {{ .CommonAnnotations.description }}
{{- if .CommonLabels.instance }}
• Instance: {{ .CommonLabels.instance }}
{{- end }}
{{- if .CommonLabels.namespace }}
• Namespace: {{ .CommonLabels.namespace }}
{{- end }}마지막으로 슬랙으로 알림을 전송할 때의 메시지 템플릿이에요. title 속성에는 상태를 대문자로 표시하고 경고의 수를 함께 표시하도록 설정했어요. (Ex. [FIRING:2]) text 속성에는 긴급성을 바로 파악할 수 있도록 심각도(Severity)를 먼저 표시했고, 상세 설명(Description)를 보여주도록 했어요. 그리고 Instance 및 Namespace 정보가 존재하면 함께 알려줍니다.
경고 발생시키기
이렇게 Prometheus와 AlertManager를 운영중인 환경에서 PrometheusRule 및 AlertmanagerConfig 커스텀 리소스를 선언하여 Jenkins와 ArgoCD의 메트릭을 기반으로 정해놓은 임계 값 조건을 만족했을 때 경고를 발생시켜 슬랙으로 알림을 제공하는 과정을 작업해보았어요.
그렇다면, 정말 슬랙으로 알림이 잘 오는지 확인해야겠죠? 먼저 젠킨스 경고 정책으로 만들었던 Jenkins Node Offline 경고를 발생시키기 위해 다시 한 번 젠킨스 슬레이브 노드 하나를 오프라인 상태로 변경해줄게요.
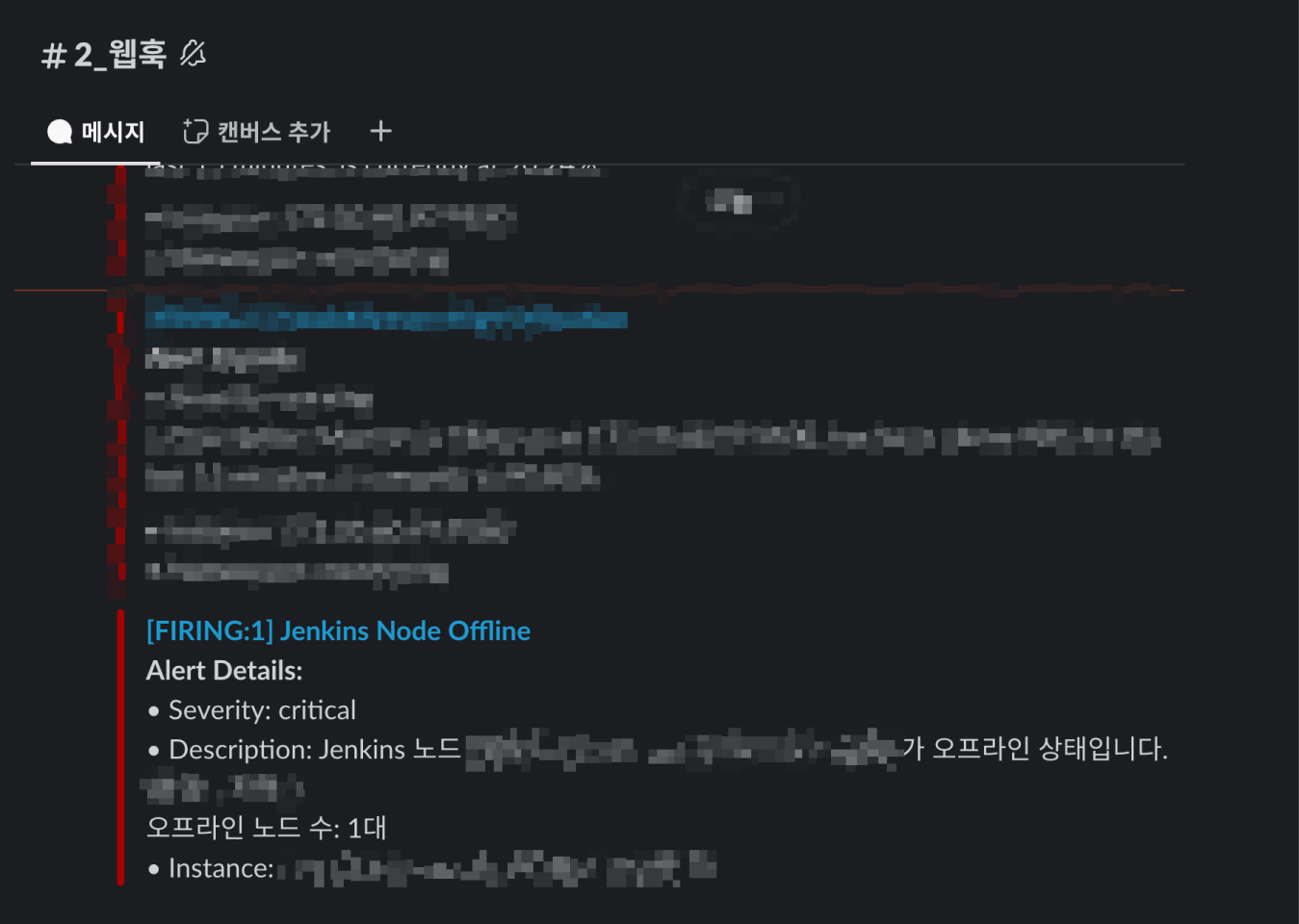
설정한 경고 발생 대기 시간이 지나니 슬랙 채널로 메시지가 잘 왔네요. 여기까지의 PoC 과정을 정리해보면 다음과 같아요.
- 기존에 운영 중이던 프로메테우스 네이티브 버전을 오퍼레이터 버전으로 마이그레이션
- 미들웨어(Jenkins, ArgoCD 등) 메트릭 수집 엔드포인트 개방
- 런타임 환경에서 동적으로 관리할 주요 경고 정책(PrometheusRule) 및 알림 설정(AlertmanagerConfig) 커스텀 리소스(CR) 정의
AS-IS
사실 PoC는 복잡한 구성으로 진행한 것이 아니라 앞으로 해야할 작업이 더 많아요. 인프라 레벨의 작업은 그리 많지 않겠지만, 서버 개발 작업에서도 재미있게 개발할 만한 작업들이 남아있답니다.
- 미들웨어가 운용되는 컨테이너 메트릭 기반의 공통 경고 정책 확장
- Jenkins, ArgoCD, GitLab, SonarQube, Harbor, Nexus의 주요 메트릭을 기반으로 경고 정책 추가
- 알림 노이즈 방지 전략 및 그룹화 전략 구체화
- 미들웨어 연계 서버 애플리케이션에서 k8s API SDK를 통해 런타임 환경에서 선언적으로 경고 정책 CR 및 알림 설정 CR 변경 관리할 REST API 설계/개발
- k8s API를 통해 접근하는 연계 서버 애플리케이션의 RBAC 정책을 두어 권한 최소화 및 접근 제어
마치며

24년 중반기부터 팀 동료들에게 조금씩 어필하고 있던 경고 관리 환경 구축의 중요성을 전파했고, 설득하여 개발 업무 티켓으로 할당받아 일하게 되어 기쁘고 감사할 따름입니다. 백엔드 커리어를 주력으로 개발하다가 인프라 레벨에서 DevOps나 SRE 개발을 병행하다보니 서버 개발만큼 가치있고 성취감을 크게 느끼고 있어요.
이번 작업을 통해 팀 동료들이 개발 중에 발생하는 장애 탐지 시간을 단축하고, 경고 관리의 일관성을 확보하여 운영 효율성을 보장받을 수 있기를 바랍니다.
다음 글은 서버 애플리케이션에서 Kubernetes Java Client 등의 SDK를 이용해 런타임 환경에서 커스텀 리소스를 동적으로 관리할 수 있는 비즈니스 로직을 개발한 작업을 기록으로 남길까 생각하고 있어요.
⏳ 이번 글은 4일동안 10시간을 투자하여 작성했습니다.
참고자료
