
Intro
코딩하기 전에 펜부터 들자.
11월 1일부터 시작한 교육과정이 벌써 한달이 되었다. 한달이라는 짧지만 긴 시간동안 나는 어떤 자세로 교육에 임했고, 무엇이 부족했을까를 생각해보게 되었다.
이상하게도 부족하고 모자란 점들이 더 많이 떠올랐다. 특정 문제에 대해서 조급한 마음으로 먼저 키보드에 손을 올리고 코딩하게 되는 잘못된 습관이 있는데, 11월 한달 동안 이러한 습관을 제대로 고치지 못한 것 같아 아쉬움이 컸다.
또한, 문제해결을 위한 솔루션에 접근하기 위해선 무작정 코딩하는 것보다 해결과정을 먼저 고민해보고 이해하는 것이 중요하다는 것을 잘 알고 있었지만 쉽지 않음을 다시 한번 느꼈다.
하지만 동료들에게 알고 있는 지식들을 공유하는 과정을 통해서 배웠던 다양한 CS지식들을 내것으로 만들 수 있었고, 조금씩 꾸준히 공부하려는 마음가짐을 잡은 것 같아 뿌듯하기도 하다.
12월부터는 배우는 것과 별개로 개발자가 되기위한 비기너로서 좋지 않은 습관들을 줄이고 고치기 위해 항상 인지하려고 노력해야겠다.
Day - 19
클라이언트와 서버가 서로 통신하며 데이터를 교환하는 과정과 ORM을 통해 RDBMS를 이용하는 방식에 대해서 배우게 되었다.
클라이언트와 서버가 데이터를 교환하는 방식
클라이언트가 접속할 때마다 서버의 데이터를 받아오는 방식은 보통 실시간으로 데이터의 변경이 필요할 경우가 해당되는데 대표적인 서비스로 유튜브가 있다.
웹 애플리케이션에서 실시간으로 통신하기 위한 수단으로는 Polling/Long Polling과 Web Socket, SSE(Server Send Event) 등이 있다.
서버의 데이터를 로컬에 저장해두고, 로컬에 없다면 가져오는 방식은 데이터의 변화가 거의 없고, 오프라인 상태에서도 애플리케이션을 사용하고자 할 때 주로 사용한다. 캘런더나 메일같은 앱에서 사용하게 된다.
서버의 데이터를 로컬에 저장하고 로컬에 데이터가 없다면 서버에서 새로 받아와 다운로드한다. 반면에 로컬에 데이터가 존재하는 상태에서 데이터에 변경점이 생긴다면 변경된 데이터만 가져오는 방식으로 구현한다.
데이터가 변경된 경우엔 기본키 값들을 비교하여 서버에는 존재하나 클라이언트에 없으면 데이터를 가져오고, 서버에는 없으나 클라이언트에 존재하면 클라이언트에서는 삭제해야 한다.
실시간으로 통신하는 방식은 무엇이 있을까?
Polling이란?
Polling이란 Http 통신을 주기적으로 전송하여 서버에서 클라이언트로 전달할 메시지를 빠르게 가져오는 형태로 동작한다. 현재 많은 웹 사이트에서 일정한 주기를 가지고 요청과 응답을 주고받는 Polling 방식을 사용하고 있다.
Long Polling이란?
Polling과 같이 서버에게 주기적으로 요청을 보내는 것은 동일하지만 일정 주기대로 요청을 보내는 것이 아니라 처음 요청을 전송하면 서버에서 해당 요청에 대한 처리를 할 수 있는지 기다린다. 즉, 서버에서 time-out이 발생하기 전까지 응답을 전송하게 되면 클라리언트는 응답을 받고 요청을 보내는 방식으로 동작한다. 만약 time-out이 발생하게 되면 재요청을 보내게 된다.
Web Socket이란?
Web Socket이란 클라이언트와 서버간에 연결을 지속시키는 것이다. 즉 양방향 통신을 가능하게 해주는 기술이기에 클라이언트에서는 언제든지 요청을 전송할 수 있고, 서버에서도 언제든지 응답을 전송할 수 있다. 하지만 대규모 트래픽이 발생할 경우 서버는 클라이언트 수만큼의 연결을 유지해야 한다는 부담이 있다.
SSE(Server Send Event)란?
SSE란 서버가 클라이언트에게 비동기적인 데이터 전송을 가능하게 해주는 기술이다. 서버와 클라이언트가 최초 연결을 진행한 뒤 서버에서 클라이언트로 지속적으로 데이터를 전송할 수 있다. 서버에서 클라이언트로 새로운 데이터가 업데이트될 때마다 보낼 수 있지만, 클라이언트에서 서버로는 보내지 못한다는 단점이 있다.
웹 환경에서의 실시간 통신을 구현하는 방식에 대해 간단하게 알아봤는데, 어떤 방식이 더 좋을까?가 아닌 내가 구현하려는 서비스의 특징과, 서버 상황에 맞는 올바른 기술을 선택하는것이 중요 하다고 생각이 들었다.
ORM(Object Relational Mapping)은 무엇일까?
RDMS(관계형 데이터베이스)를 이용하는 방법은 여러가지가 있다.
데이터베이스 드라이버 사용SQL Mapper 형식으로 사용ORM 사용
ORM은 관계형 데이터베이스의 테이블을 클래스와 매핑하고, 테이블의 각 행들을 인스턴스와 매핑해서 사용하는 방식으로 SQL을 사용할 수도 있고 사용하지 않을 수도 있다. 일반적으로 SQL Mapper보다 성능이 뛰어나기 때문에 솔루션 및 서비스 개발에 주로 사용되지만 러닝커브가 짧지 않아 SI 업무에는 잘 활용하지 않는다.
이러한 ORM에 관하여 구체적으로 살펴보자.
ORM(Object Relational Mapping)이란 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말한다. 즉, 객체라는 개념을 구현한 클래스와 RDBMS에서 쓰이는 데이터인 테이블을 연결하는 것을 의미한다.
그러나 클래스와 테이블은 완벽히 호환되는 구조가 아니기에 두 구조간의 불일치가 발생하게 된다. 이를 ORM을 통해 프레임워크가 SQL로 변환하여 데이터베이스에 작업을 수행하는 방식으로 동작하는데, 객체간의 관계를 통해 SQL 쿼리문으로 변환하여 해결할 수 있게 된다.
따라서 ORM을 이용하게 되면 별도의 SQL 쿼리문을 작성할 피요없이 객체를 조작하여 직접적으로 데이터베이스를 다룰 수 있게 되는 것이다.
ORM을 사용하면 무엇이 좋을까?
-
비즈니스 로직에 집중할 수 있다.
객체 지향적인 코드를 작성할 수 있어 SQL문 작성에 드는 비용을 비즈니스 로직을 작성하는데 투자할 수 있게 된다. -
유지보수 및 재사용성이 향상된다.
ORM은 별도로 작성되어있어 객체로 작성할 수 있다. 작성된 객체를 재사용할 수 있기 때문에 개발자 입장에서 더 효율적으로 개발할 수 있다. -
DBMS에 대한 종속을 낮출 수 있다.
객체 간의 관계를 바탕으로 SQL을 자동으로 생성하기 때문에 RDBMS의 데이터 구조와 Java의 객체지향 모델 사이의 간격을 좁힐 수 있다. 개발자는 객체에만 집중할 수 있기 때문에 DBMS를 교체하는 작업에도 리스크가 적고 드는 시간도 줄어든다.
그렇다면 ORM은 완벽한 솔루션인가?
ORM을 사용하는 것은 편리할 수 있지만 충분히 설계하고 반영해야한다. 프로젝트 규모가 커지고 복잡해질수록 잘못 설계될 경우 큰 문제가 발생할 수 있다.그리고 복잡한 SQL문을 사용해야 할 경우엔 속도가 느리기 때문에 결국 기존의 SQL문을 사용해야 할 수도 있다.
ORM 프레임워크의 종류들
-
JPA/Hibernate
JPA(Java Persistence API)는 자바의 ORM 기술 표준으로 인터페이스의 모음이다. 이러한 JPA 표준 명세를 구현한 구현체가 바로 Hibernate이다. -
Sequelize
Sequelize는 Postgres, MySQL, MariaDB, SQLite 등을 지원하는 Promise에 기반한 비동기로 동작하는 Node.js ORM이다. -
Django ORM
python기반 프레임워크인 Django에서 자체적으로 지원하는 ORM이다.
ORM을 배우고 구현해보며 SQL 쿼리문 작성에 드는 시간을 프로젝트 구조화 및 비즈니스 로직에 투자할 수 있다는 점이 큰 메리트라고 느꼈다.
Day - 20
NoSQL의 한 종류인 mongoDB에 대해서 알아보고 활용해보는 시간을 가졌다. 이로 인해 RDBMS와 NoSQL이 데이터를 보관하는 방식에서 어떤 차이가 있는지 어느정도 이해할 수 있었다.
NoSQL은 RDBMS와 무슨 차이가 있을까?
NoSQL(Not Only SQL)이란 관계형 데이터베이스(RDBMS)보다는 제한성이 낮은 형태로 데이터 저장 및 검색을 위한 기술을 제공한다.
RDBMS와는 달리 테이블 간의 관계를 정의하지 않아 테이블 간 Join문을 사용할 수 없으며 RDBMS와 다르게 스키마가 존재하지 않아 자유롭게 데이터를 저장할 수 있다.
NoSQL 데이터베이스는 빅데이터와 실시간 웹 애플리케이션 개발에 활용되는데 SQL 쿼리를 사용할 수 있기에 "Not only SQL"로 불리기도 한다. Not Only SQL이라는 의미는 RDBMS가 갖고있는 특성뿐 아니라 다른 특성들을 부가적으로 지원한다는 것을 의미한다고 한다.
RDBMS VS NoSQL
RDBMS는 데이터 구조가 명확하고 불변성을 지닌 스키마가 중요한 경우 사용하는 것이 좋다. 또한 데이터 무결성 특징을 지니기에 중복되는 데이터가 없어 변경이 용이하여 데이터의 변경이 잦은 서비스에 적합하다고 할 수 있다.
NoSQL은 정확한 데이터 구조를 알 수 없지만 데이터가 변경 및 확장이 될 수 있는 경우에 사용하는 것이 적절하다고 볼 수 있다. 데이터 중복이 발생할 수도 있기 때문에 중복된 데이터를 변경할 경우 모든 컬렉션에서 수정 작업을 해야 한다. 결국 수정 작업(Update)이 적은 서비스에 바람직하다.
그리고 RDBMS는 엄격한 트랙잭션을 적용하지만, NoSQL은 느슨한 트랜잭션을 적용한다. 거래등의 부분적인 기능의 실패가 치명적일 경우는 RDBMS를 통해 강력한 트랜잭션을 활용해야하고, 채팅 같은 기능의 경우는 덜 강력한 트랜잭션을 활용해도 크게 영향이 없으니 빠르게 채팅을 주고받기 위해 NoSQL을 사용하기도 한다.
또한, 특정 컬렉션에 모든 데이터가 저장되는 형태로 데이터 중복이 허용되기에 분산을 시킬 경우 구간을 정해 저장하면 된다. 즉, 분산 저장(scale-out)이 가능하다는 장점이 있어 대량의 데이터를 저장해야 하는 시스템에서 주로 사용한다.
분산 저장(scale-out)이란?
더 많은 서버를 추가하여 데이터 베이스가 전체적으로 분산되는 것을 의미합니다 기존 서버만으로 용량이나 성능의 한계에 도달했을 때, 비슷한 사양의 서버를 추가로 연결해 처리할 수 있는 데이터 용량이 증가할 뿐만 아니라 기존 서버의 부하를 분담해 성능 향상의 효과를 기대할 수 있다.
NoSQL은 복잡한 거래가 없거나 비정형 데이터만을 저장하기 위한 용도로 사용된다.
NoSQL 분류
NoSQL을 하면 Document 기반의 MongoDB가 가장 먼저 떠오른다. MongoDB말고도 다른 NoSQL도 존재한다.
- Wide Columnar Store : Cassandra
- Document Store : MongoDB
- Key-Value Store : DynamoDB, Redis
- Graph Store: Neo4j
MongoDB에 대해서 알아보자.
MongoDB란 NoSQL Document 데이터베이스로 C++로 작성된 문서지향(Document-Oriented) 크로스 플랫폼이다.
MongoDB는 NoSQL의 특성을 지니고 있기 때문에 데이터를 정해진 스키마 없이 자유자재로 원하는 타입으로 넣을 수 있다.
기본적으로 MongoDB의 구조는 Database > Collection > Document > Field 계층으로 이뤄져있다.
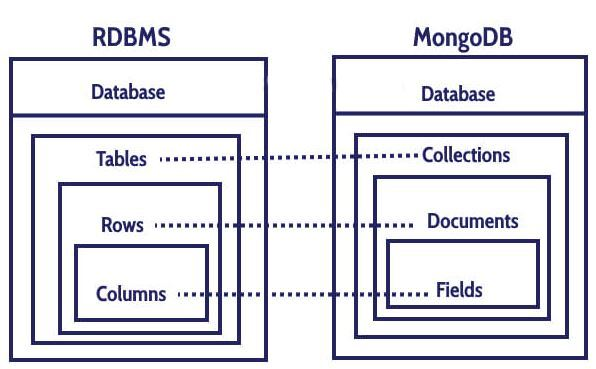
RDBMS와의 비교
RDBMS와 비교해보면 구조적인 차이는 크지 않지만 명시된 이름이 조금씩 다름을 알 수 있다.
| RDBMS | NoSQL |
|---|---|
| Database | Database |
| Table(Relation) | Collection |
| Row(Record, Tuple) | Document |
| Column(Attribute) | Field |
| Index | Index |
| Join | Embeding & Linking |
| Select 구문의 결과로 Row의 집합을 반환 | Cursor를 반환 |
MongoDB에서 Join문을 어떻게 구현할까?
RDBMS(관계형 데이터베이스)는 하나의 컬럼에 하나의 값만 입력할 수 있다. 다른 테이블의 데이터나 배열을 대입할 수 없기에 여러 테이블을 만들어야 하고 여러 정보들을 가져오기 위해서 Join문을 수행해야한다.
그에 반해 MongoDB는 Join문 대신 Collection에 최대한 많은 양의 데이터를 저장하는 것을 권장한다. 하지만 성능 측면에서 보면 하나의 Collection에 너무 많은 양의 데이터를 저장하면 크기가 너무 커지게 된다.
결국 디스크 I/O가 많이 필요하게 되고 메모리의 캐시 효율이 떨어지게 되므로 요즘엔 N개의 Collection을 만들고 데이터를 나누어서 저장하기를 권장하는 편이다.
MongoDB에대 알아보며 느꼈던 생각을 정리하자면, JSON 구조로 이루어졌기에 데이터를 직관적으로 확인하여 이해할 수 있기에 어느정도 사용이 편리하다고 느꼈다. 또한, Schema-less 구조의 이점을 극대화할 수 있는 환경에서 다양한 형태로 데이터를 저장할 수 있고 데이터 모델 변경이나 필드를 변경하기에 유리한 상황이라면 MongoD를 적극적으로 이용해볼 수 있을 것이라고 생각이 들었다.
Day - 21
Mongoose라는 ODM 라이브러리에 대해서 알아보고 연동해보는 시간을 가졌다. 또한 로그인을 구현하면서 인증 및 인가에 대해서도 배울 수 있었다.
ODM(Object Document Mapping) 라이브러리 Mongoose란?
Node와 MongoDB를 사용하는데 Mongoose라는 ORM 라이브러리의 존재를 알게 되었다.
ODM(Object Document Mapping)이란?
ODM은 NoSQL에서 Document Database를 지원하기 위해 데이터를 변환하는 프로그래밍 기법으로 Relation 대신에 Document를 하나의 객체에 매핑하는 방식이다.
하나의 Document에 대한 구조를 만든 뒤 사용해야 하기에 NoSQL의 Collection은 어느정도 정형화된 구조를 지녀야 한다.
Mongoose란?
Mongoose는 Node를 기반으로 MongoDB에서 ODM을 사용할 수 있도록 도와주는 대표적인 라이브러리이다. Mongoose는 Sequelize와는 달리 Relation이 아닌 Document를 사용하기에 ODM이라고 불린다.
Object는 JavaScript의 객체이고, Document는 MongoDB의 문서인데 특정 문서를 DB에서 조회할 때 JavaScript 객체로 변환해주는 역할을 수행한다고 이해하였다.
MongoDB의 ODM의 종류는 Mongoose뿐만 아니라 Mongo.js 등이 존재하지만 Mongoose가 가장 많이 사용된다고 한다.
MongoDB에는 없던 스키마가 생겼다고?
Mongoose에는 MongoDB에서 없었던 Schema라는 개념이 추가되었다.
기존의 MongoDB에는 Collection에 스키마 제약없이 자유롭게 데이터를 넣을 수 있었지만 실수로 잘못된 데이터를 삽입하거나 존재하지 않는 필드에 데이터를 삽입할 수 있다는 단점이 있었다.
이러한 단점을 개선하기 위해 Mongoose는 MongoDB에 데이터를 삽입하기 전에 Node 서버 단에서 데이터를 한 번 필터링하는 역할을 수행한다.
필터링하는 역할의 예를 들자면 update 작업을 진행할때 $set 작성을 누락되지 않도록 방지해준다.
Authentication(인증)과 Authorization(인가)은 무엇이 다를까?

인증과 인가는 항상 함께 등장하는 개념이면서 동시에 헷갈리는 경우가 많다. 보안과 관련된 두 개념에 대해서 살펴보자.
Authentication(인증)이란?
인증은 특정한 사용자가 누구인지 확인하는 절차이다. 로그인 과정이 인증의 대표적인 에시이다.
인증에 관련된 예를 들어보자. 20대 직장인과 같이 특정 개체의 신원을 확인하는 과정이라고 이해하면 된다.
Authorization(인가)란?
인가는 권한과 관련된 부분으로, 사용자의 요청에 대한 처리를 실행할 수 있는 권한 여부를 확인하는 절차이다.
인가와 관련된 예시는 대리급 직책 이상부터 출입 가능 과 같은 것이다. 어떤 리소스에 접근할 수 있는지, 어떤 동작을 수행할 수 있는지를 검증하는 것이다.
인증 vs 인가
사실 인증과 인가는 동시에 진행해야 할 경우도 있다.
회사에 출근하면 찍는 지문 인식기는 내가 누구인지도 인식하면서, 내가 회사 출입문을 통과할 수 있도록 회사 내부 접근을 인가하기도 한다.
위 예시들처럼 특정한 경우에는 함께 사용되기에 많이 헷갈릴 수 있다고 생각한다. 그래서 인증은 인가로 이어질 수 있지만, 인가는 인증으로 이어지지 않는다는 점을 꼭 기억하자. 사용자의 신원이 증명되고 접근권한을 승인받을 수 있다고해도, 결국 인가 자체로 사용자를 인증할 수는 없기 때문이다.
Day - 22
인증을 위한 개방형 표준 프로토콜인 OAuth에 대해서 알아보고 배울 수 있었다. 더불어 인증 및 인가 절차에 대한 흐름을 파악하는 시간을 가질 수 있었다.
OAuth(Open Authorization)란?
위 사진은 OKKY 커뮤니티 로그인 화면이다. GitHub, Google, FaceBook, Naver, Kakao 와 같은 소셜 로그인 방식을 제공하는 것을 볼 수 있다.
요즘엔 Google이나 Kakao 등의 외부 소셜 계정을 가지고 바로 로그인이나 회원가입을 할 수 있는 웹 어플리케이션을 쉽게 접할 수 있는데 이 때 사용되는 프로토콜이 바로 OAuth이다.
OAuth는 인터넷 사용자들이 비밀번호를 제공하지 않고 다른 웹사이트 상의 자신들의 정보에 대해 웹사이트나 애플리케이션의 접근 권한을 부여할 수 있는 공통적인 수단으로서 사용되는 접근 위임을 위한 개방형 표준이다.
다른 애플리케이션에서의 사용자 정보를 보다 안전하게 사용하는 방법이라고 이해하면 된다. 사용자 정보를 가지고 있는 사용자, 즉 고객들이 안전하게 다른 애플리케이션의 정보를 가져와서 사용하기 위한 방식이다.
왜 OAuth를 사용하게 되었을까?
웹 서비스에 개인정보를 전송한다는 것은 잘 몰랐지만 보안적으로 좋지 않다고 한다. 해당 사이트가 안전한지, 나의 정보를 어디에 사용하는지 등을 확인해야 하는데, 제대로 알 수 없는 사이트들도 분명히 존재한다고 생각한다.
만약 내 정보의 사용처와 안전성이 고려되지 않는 서비스라면 사용자 입장에서는 이용하기 힘들 것이다. 그래서 이러한 점을 개선하기 위해 OAuth가 등장하게 되었다. 안전이 보장되는 대규모 기업들에게 개인정보를 보관하고, 해당 기업에서 정보를 확인하여 접근할 수 있는 Token만 발급하는 방식이기에 사용자는 큰 부담없이 안전하게 해당 사이트를 이용할 수 있게 된다.
Access Token(접근 토큰)이란?
OAuth에서 중요한 것들 중 하나가 바로 접근 토큰이다. 접근 토큰은 임의의 문자열로 이루어져 있는데 이 토큰의 주체는 토큰을 발급한 서버 뿐이다.
이 접근토큰을 이용해 토큰값과 매칭되는 사용자의 정보를 전송할 수 있다. 즉, 접근토큰을 발급 받았다는 것은 사용자의 정보를 전송하는 것을 동의한다라는 것과 같다.
OAuth 2.0은 무엇인가?
OAuth의 초창기 버전인 OAuth 1.0은 몇 가지 보안 이슈가 있었다. 그 내용은 다음과 같다.
- 웹이 아닌 모바일 애플리케이션에서 자원이 부족해 사용하기에 불편했다.
- 접근 토큰에 유효기간이 존재하지 않기 때문에 만료되지 않는 문제가 있었다.
위와 같은 문제들을 개선한 2.0 버전이 현재 대중적으로 사용되고 있다.
OAuth 1.0과 OAuth 2.0의 차이점
| 구분 | OAuth 1.0 | OAuth 2.0 |
|---|---|---|
| 참여자 | - 이용자 - 소비자 - 서비스 제공자 | - 자원 소유자 - 클라이언트 - 권한 서버 - 자원 서버 |
| 토큰 | - 요청 토큰(Request Token) - 접근 토큰(Access Token) | - 접근 토큰(Access Token) - 재접근 토큰(Refresh Token) |
| 유효기간 | 접근 토큰 유효기간 없음 | 접근 토큰에 유효기간이 존재하며 만료시에는 재발급 토큰을 이용한다. |
| 클라이언트 | 웹 | 웹, 앱 |
아무래도 안전하게 타사 서비스의 정보를 활용하기 위해서는 앞으로 어느정도 활용할 줄 알아야 한다고 느꼈다. 어떻게하면 안전하고 편리하게 서비스를 등록하고 토큰을 받아 토큰을 이용해 정보를 요청하는 절차를 구현 수 할지 고민하는 시간을 가져야 겠다.
API Server를 왜 분리할까?
Applicaion Server에는 두가지 방식으로 클라이언트에게 View 데이터를 전송할 수 있다.
서버에서 템플릿 엔진 등을 활용해 View를 만들어 클라이언트에게 전송하는 방법과 View에 필요한 데이터를 DB에서 가져와서 JSON 포맷으로 전송하는 방법이 있다.
그런데 View를 서버에서 구성하여 클라이언트에게 전송한다면 모바일 애플리케이션 환경을 구성해야 하는 등 클라이언트 구성요소가 변경될 때마다 그에 대응하는 서버를 구비해야 하기에 유지보수하기 매우 어렵다.
안드로이드 환경에서 동일한 서비스를 제공하고자 할 경우는 어떨까?
안드로이드 화면은 서버에서 렌더링할 수 없기 때문에 별도의 안드로이드 프로젝트를 개발해야 하고 서버에 안드로이드를 위한 소스코드가 추가되어야 한다. 그렇다면 안드로이드 환경을 대응하는 URL을 생성해서 처리해야 하는데 동일한 요청에 대한 URL이 2개가 생성하게 된다.
이러한 점을 개선하기 위해 서버와 클라이언트를 분리하여 서버에서는 필요한 데이터만을 전송해주는 API 서버 형태로 구축해야 한다. 이로 인해 클라이언트에서 다양한 환경이 추가적으로 구축되더라도 서버에 영향을 주지 않게 된다.
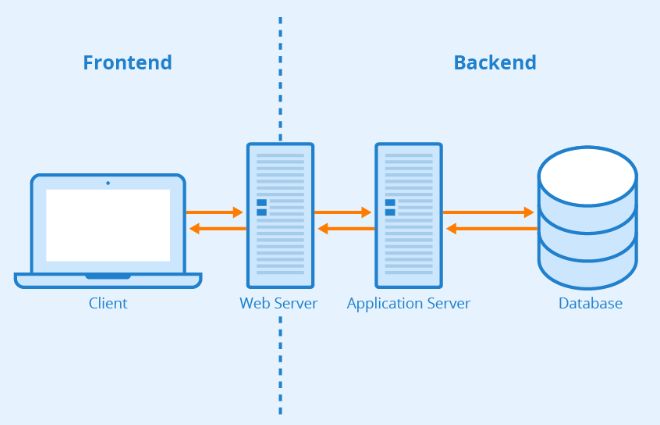
위 사진에서의 Application Server가 별도로 화면을 렌더링하여 클라이언트에게 전송하지 않고 데이터만 전송한다면 API Server라고 불린다.
하지만 API 서버를 클라이언트 단과 분리하여 사용한다면 클라이언트에게 필요한 데이터만 찾아서 전송하면 되기에 클라이언트의 크고 작은 변경에도 큰 영향을 받지 않는다.
Day - 23
토큰 기반의 인증 방식인 JWT에 대해서 배웠다. 토큰을 활용한 인증 방식을 적용하는 웹 서비스 대부분에서 이용하는 방식이기에 꼭 잘 배우고 적절하게 활용할 줄 알아야 한다고 느꼈다.
정해진 데이터를 삽입할 때는 ENUM을 사용하라고?
위키피디아에서 살펴본 ENUM의 개념은 다음과 같다.
ENUM(Enumerated Type)이란?
ENUM이란 Enumerated Type의 줄임말로 열거형이라고 부르기도 하는데 컴퓨터 프로그래밍에서 열거형(enumerated type, enumeration)은 요소, 멤버라 불리는 명명된 값의 집합을 이루는 자료형이다. 열거자 이름들은 일반적으로 해당 언어의 상수 역할을 하는 식별자이다.
여기서 상수라 함은, 변하지 않는 값으로 정수, 문자열 및 그 외 자료형도 얼마든지 상수로 정의할 수 있다는 것이다.
boolean 자료형을 예로 들자면 false와 true 값이 미리 정의된 열거형으로 볼 수 있다. boolean형 뿐만 아니라 많은 프로그래밍 언어에서 사용자들이 새로운 열거형을 정의할 수 있게 하고 있다.
왜 ENUM을 사용할까?
앞에서 알아본대로 ENUM은 서로 연관된 상수 값들의 집합이다. 상수는 변하지 않는다는 특징을 지니기에 무슨 연관을 가지는지 모르는 값들을 좀 더 단순하게 이용하여 가독성을 높일 수 있다.
아래의 JavaScript 코드를 살펴보자.
switch(fruit) {
case 1 :
console.log("apple");
break;
case 2 :
console.log("grape");
break;
case 3 :
console.log("banana");
break;
}case 1과 console.log("apple")로 출력한 "apple"이 어떤 관련이 있는지는 개발자 입장에서 이해하기 어렵다.
위 코드에서 상수를 활용한다면 이러한 상관 관계를 명확하게 해줄 수 있다.
// 상수 이용
const APPLE = 1;
const GRAPE = 2;
const BANANA = 3;
switch(fruit) {
case APPLE :
console.log("apple");
break;
case GRAPE :
console.log("grape");
break;
case BANANA :
console.log("banana");
break;
}위 코드와 같이 상수를 이용한다면 case 조건과 출력문의 관계가 좀 더 명확해지고 관련이 있음을 알 수 있다.
다만, const로 선언된 APPLE, GRAPE, BANANA는 각각 독립된 변수이기에 한번에 관리하기는 어려울 수도 있다. 만약 코드가 길어진다면 더욱이 유지보수하기엔 어려움이 있다.
이 상황에서 ENUM을 사용한다고 어떻게 될까?
// ENUM 객체 활용
let Fruit = {
APPLE:1,
GRAPE:2,
BANANA:3
}
let fruit = 2;
switch(fruit) {
case Fruit.APPLE :
console.log("apple");
break;
case Fruit.GRAPE :
console.log("grape");
break;
case Fruit.BANANA :
console.log("banana");
break;
}ENUM을 통해 수정한 코드를 보면 case 조건의 Fruit.APPLE과 출력문 APPLE의 관계는 더욱 명확해졌다. 즉, 가독성이 훨씬 나아졌음을 알 수 있다. 또한 독립된 변수로써 선언되어있던 APPLE, GRAPE, BANANA를 Fruit라는 ENUM 객체 내에서 관리할 수 있기에 유지보수도 전보다 유리해졌다.
ENUM을 알아보며 느꼈던 생각을 정리하자면, 상수들을 쉽게 관리할 수 있기에 개발자 입장에서 많은 비용과 시간을 아낄 수 있기에 필수적으로 사용해야 한다고 느꼈다. 앞으로 상수들을 사용해야 하는 상황이 있다면 꼭 ENUM을 잘 고려하여 적용해야겠다.
JWT(Json Web Token)에 관하여

JWT에 대한 공식 사이트의 소개를 살펴보았다.
JWT(JSON Web Token)란?
JWT(JSON Web Token)는 당사자 간에 정보를 JSON 개체로 안전하게 전송하기 위한 간결하고 독립적인 방법을 정의하는 개방형 표준(RFC 7519)이다. 이 정보는 디지털 서명되어 있으므로 확인하고 신뢰할 수 있으며 JWT는 시크릿(HMAC 알고리즘 포함)이나 RSA 또는 ECDSA를 사용하는 공개/개인 키 쌍을 사용 하여 서명할 수 있다.
JWT에 대해서 다시 한번 정리하자면, 사용자를 인증하고 식별하기 위한 토큰 기반의 인증방식이라고 보면 된다.
JSON 데이터 구조를 Base64 URL-safe Encode로 인코딩하여 표현된 토큰으로써 클라이언트에서 JWT 토큰을 서버로 전송하면 서버는 서명을 받은 JWT를 서명을 검증하는 절차를 거치고 검증이 완료되면 응답을 주는 방식으로 이루어진다.
Base64 URL-safe Encode는 일반적인 Base64 Encode 에서 URL 에서 오류없이 사용하도록 '+', '/' 를 각각 '-', '_' 로 표현한 것이다.
JWT의 구조는?
JWT의 핵심은 토큰 자체에 사용자의 권한정보나 서비스 사용을 위한 정보가 포함되어 있다는 점인데, Header, Payload, Signature 3가지 문자열의 조합으로 구성되어 있다.
- Header
Header에는 JWT에서 사용할 타입과 해시 알고리즘의 종류가 담겨있다. alg에는 서명 암호화 알고리즘을 작성하고, typ에는 토큰 유형을 작성한다.
{
"alg": "HS256",
"typ": "JWT"
}- Payload
Payload에는 서버에서 첨부한 사용자 권한정보와 데이터가 담겨있다. 서버와 클라이언트가 주고받는 애플리케이션에서 실제로 사용될 정보가 담겨있다고 보면 된다.
정해진 데이터 타입은 없지만 대표적으로 Registered claims, Public claims, Private claims로 구분된다.- Registered claims는 미리 정의된 클레임으로 iss(issuer:발행자), exp(expireation time:만료시간), sub(subject:제목), iat(issued At:발행시간), jti(JWI ID)가 포함된다.
- Public claims는 사용자가 정의할 수 있는 클레임 공개용 정보 전달을 위해 사용한다.
- Private claims는 정보를 공유하기 위해 만들어진 사용자 지정 클레임으로 외부에 공개되도 상관없지만 해당 유저를 특정할 수 있는 정보들을 담는다.
- Registered claims는 미리 정의된 클레임으로 iss(issuer:발행자), exp(expireation time:만료시간), sub(subject:제목), iat(issued At:발행시간), jti(JWI ID)가 포함된다.
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
- Signature
Signature에는 Header, Payload를 Base64 URL-safe Encode 인코딩을 수행한 후 Header에서 정의한 알고리즘 방식으로 암호화한다. 또한 서버가 가지고 있는 유일한 개인 키(Private Key)로 서명한 전자서명이 담겨있다.
Header와 Payload는 단순히 인코딩된 값이기 때문에 제 3자가 복호화 및 조작할 수 있지만, Signature는 서버 측에서 관리하는 비밀키가 유출되지 않는 이상 복호화할 수 없다. 따라서 Signature는 토큰의 위변조 여부를 확인하는데 사용된다.
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)위에서 살펴본 Header, Payload, Signature을 통해 JWT를 생성하게 되면 아래와 같은 문자열이 된다.

왜 JWT를 사용할까?
서버와 클라이언트 애플리케이션이 분리되어 서로 도메인이 다르다면 쿠키와 세션은 사용할 수 없다. 별도의 설정을 하게되면 쿠키를 공유할 수는 있지만 보안 이슈가 발생할 수 있다.
서버와 클라이언트의 도메인이 다를 경우 세션을 이용해서 사용자 인증을 할 수 없다. 그래서 서버에서 클라이언트에게 키를 발급하고 클라이언트는 서버에게 요청할 때마다 키를 전송하여 인증된 사용자라는 것을 알려주어야 한다.
그런데 키는 평문으로 전송하게 되면 중간에 탈취하여 사용할 수 있기 때문에 키와 클라이언트 URL을 합쳐 하나의 암호화된 문장을 생성하여 전송한다면 서버는 이를 해독하여 키와 클라이언트 URL을 확인할 수 있다.
만약 다른 곳에서 키를 탈취하여 데이터를 요청한 경우 클라이언트 URL이 다르기 때문에 인증된 사용자가 아님을 검증할 수 있게 된다.
API 서버나 로그인을 이용하는 시스템에서 매번 인증을 하지 않고 서버와 클라이언트가 정보를 주고받을 때 HttpRequestHeader에 JSON 토큰을 넣어 인증하는 JWT 토큰 인증방식을 사용해 다른 로그인 시스템에 접근 및 권한 공유가 가능하기에 쿠키보다 좋은 성능을 제공한다.
JWT에 대해서 알아보았는데, 최근 웹서비스에서 대중적으로 사용되고 있고 어느정도 규격이 정해져있기에 다양한 클라이언트에서 활용하기가 좋지만 마냥 JWT가 좋은 것은 아니다.
JWT의 단점에 대해서 살펴보면 먼저 토큰 자체에 정보를 담고 있기에 위험하고 Payload가 많아진다면 토큰이 커져 서버에 부하를 줄 수 있게 된다. 그리고 토큰이 재발급되기 전까지는 사용자 정보가 수정되어도 적용되지 않는 문제가 있다고 한다.
그래도 Restful에서 요구하는 무상태(stateless)을 잘 지킬 수 있는 방법 중 하나이고 많은 서비스에서 사용되어지고 있기에 꼭 활용하고 다룰 줄 알아야 한다고 느꼈다.
Final..
한달이라는 짧은 시간동안 배운 지식들을 복기해보자.
XHTML, CSS, HTML5, JavaScript를 배우며 프로그래밍 기초 지식을 배웠다. 그리고 Node.js를 활용해 서버단을 구현하면서 RDBMS의 MariaDB, NoSQL의 MongoDB를 연동해보았다.
단순히 서버 프로그래밍에만 집중하는 것이 아니라 클라이언트와 서버간의 데이터 통신을 위해 데이터베이스에 대한 이해도도 높일 수 있었다.
그리고 ORM인 Sequelize와 ODM인 Mongoose도 반영해보았다. ORM과 ODM을 통해서 DBMS에 대한 종속성을 낮출 수 있는 방식에 대해서 배울 수 있었다.
또한, 쿠키와 세션, 인증(OAuth) 및 인가(JWT) 과정을 배우고, 구현해보며 다양한 보안 정책들에 대해서 나름대로 인지하고 어떻게 적용해야 할지 고민하는 시간들을 가지게 되었다.
혹여 잘못된 내용이 있다면 지적해주시면 정정하도록 하겠습니다.게시물과 관련된 소스코드는 Github Repository에서 확인할 수 있습니다.
참고자료 출처
- https://kim-jong-hyun.tistory.com/m/94
- https://codingjuny.tistory.com/55
- https://broccoli45.tistory.com/46
- https://gmlwjd9405.github.io/2019/02/01/orm.html
- https://geonlee.tistory.com/207
- https://inpa.tistory.com/entry/ODM-%F0%9F%93%9A-%EB%AA%BD%EA%B5%AC%EC%8A%A4-%EC%82%AC%EC%9A%A9%EB%B2%95-%EC%A0%95%EB%A6%AC
- https://www.zerocho.com/category/MongoDB/post/5963b908cebb5e001834680e
- https://okky.kr/login?returnUrl=%2F
- https://velog.io/@undefcat/OAuth-2.0-%EA%B0%84%EB%8B%A8%EC%A0%95%EB%A6%AC
- https://inpa.tistory.com/entry/WEB-%F0%9F%93%9A-OAuth-20-%EA%B0%9C%EB%85%90-%F0%9F%92%AF-%EC%A0%95%EB%A6%AC#OAuth%EB%9E%80?
- https://maily.so/grabnews/posts/b2341a
- https://blog.dalso.org/language/web/6523
- https://en.wikipedia.org/wiki/Frontend_and_backend
- https://joooosan.tistory.com/75
- https://inpa.tistory.com/entry/WEB-%F0%9F%93%9A-JWTjson-web-token-%EB%9E%80-%F0%9F%92%AF-%EC%A0%95%EB%A6%AC#JWT_(JSON_Web_Token)
