Review: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation(SegNet) - incomplete
0
1. Introduction
- The motiviation of this paper is to solve the problem of max pooling and sub-sampling reduce feature map resolution.
- The encoder of SegNet is indentical to CNN of VGG16. In decoder, the proposed model used max-pooling indices from encoder.
3. Architecture
- The encoder of the model has 13 convolutional layer and each encoder layer has a corresponding decoder layer. Therefore there are 13 decoder layer. The output of final layer will be get through multi-class soft-max classifier and it will calculate probability of each class for a independent pixel
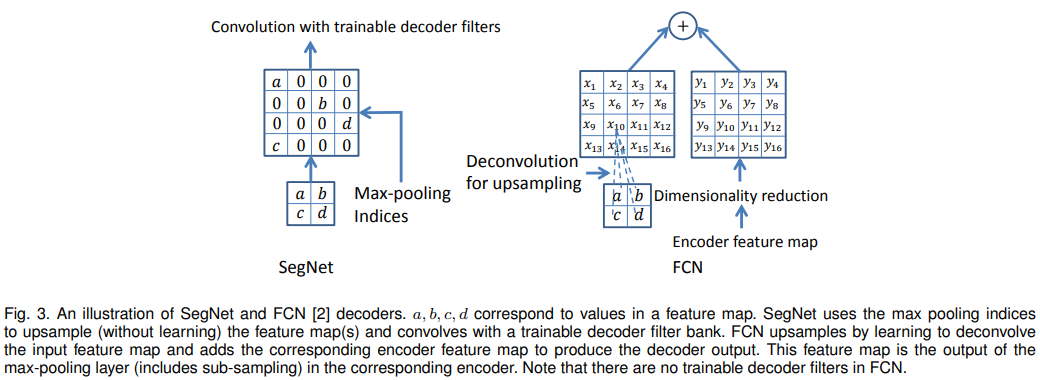
- In encoder, it is easy to loss boundary information of image during max pooling. Therefore, this paper proposed the method to store max-pooling indices for each encoder feature map.
- Decoder upsamples its input feature map using max pooling indices.(Figure 3) The final upsamples feature representation is fed to soft-max classifier. As a result, the output of the soft-max classifier will be (number of classess) dimentional output which represent probability for each class.
Reference
https://arxiv.org/pdf/1511.00561.pdf

호수공원