
본 글은 LLM을 추상적으로 이해하고 Bedrock에서 Fine-Tuning 실습하기 (1부)에서 이어지는 글입니다. 실습 내용이 포함되기에 AWS, Python에 대한 기본 지식을 요구합니다.
우리는 1부에서 자연어가 어떻게 숫자가 되는지, 그 숫자들이 어떻게 계산되고, LLM이 어떤 방식으로 의미를 학습하는지 차근차근 정리해봤습니다.
글 마지막엔 이미 거대한 데이터로 학습된 LLM을 내 목적에 맞게 조금만 바꾸는 방법, 즉 Fine-Tuning이라는 개념에 대해 살짝 언급햇습니다.
아래와 같은 궁금증이 들지 않나요?
“이걸… 직접 해보려면 뭐부터 알고 준비해야 하지?”
Fine-Tuning 기법도 워낙 많고, 어떤 방식을 선택할지도 고민입니다.
LoRA? Adapter? Full Fine-Tuning?
GPU 같은 자원은 기본이고, 병렬 처리, 모델은 어디서 어떻게 불러와야 하는지 등 알아야 할 것이 정말 많죠.
다행히도 모델을 로드하고, 학습시키고, 튜닝된 모델을 평가까지 할 수 있는 완전한 실습 환경이 클라우드에 준비돼 있습니다.
바로, AWS의 Bedrock입니다.
Bedrock이란?
Bedrock은 Amazon에서 제공하는 LLM 통합 플랫폼입니다.
여러 회사에서 만든 다양한 LLM(Claude, LLaMA, Titan 모델 등)을 불러올 수 있고,그 위에 내 데이터를 입혀 Fine-Tuning을 하거나, 튜닝된 모델을 평가하고 호출 할 수 있습니다.
또한 VPC 기반으로 네트워크를 격리할 수 있기 때문에,내부망에서만 배포하는 것도 가능합니다.
즉 Bedrock은 모델 호출 → 학습 → 평가 → 배포까지 한 플랫폼에서 이어서 해볼 수 있는 구조입니다.
Bedrock 요금 구조
서비스를 이용하기 전에 알아두어야 할 중요한 점은 "얼마나 비용이 드는지"와 "어떤 부분에서 비용이 발생하는지"입니다. 그래서 먼저 요금 구조에 대해 살펴보겠습니다.
몇 억~몇 백 억개의 파라미터를 가진 LLM을 구동하고 연산을 수행하려면 상당한 컴퓨팅 자원이 필요합니다. Bedrock의 요금 체계는 이러한 특성을 반영하여 다음과 같이 구성되어 있습니다.
1. 학습 비용
Fine-Tuning은 1부에서 다룬 "예측 → 오차(loss) 계산 → 내부 행렬 수정 → 다시 예측"을 반복하는 과정입니다. 몇 억 ~ 몇 백 억개의 파라미터에 대한 계산을 하려면 상당한 컴퓨팅 리소스가 필요하겠죠. 또한 학습이 완료된 모델을 어딘가에 저장해야할 필요도 있습니다. 요금 구조도 이에 맞춰져 있습니다.
- 학습(Training) 비용
- 학습 데이터의 총 토큰 수 × epoch 수만큼 연산이 발생합니다. 이 기준으로 요금이 부과됩니다.
- ex) 10,000 토큰 × 3 epoch → 30,000 토큰 처리 비용
- 모델 저장 비용
- 학습이 끝난 모델은 Bedrock 전용 저장소에 저장됩니다. 이 저장소도 월 단위로 과금됩니다.
- 모델 별로 가격이 조금씩 다르며, Haiku 모델 기준으로는 월 $20입니다.
2. 추론 비용 (모델 사용)
학습시킨 모델을 실제로 사용할 때도 컴퓨터 리소스가 필요하기 때문에 요금이 발생합니다. Bedrock에서는 Fine-Tuned 모델을 Provisioned Throughput 방식으로만 사용할 수 있으며, 처리량과 사용 시간 기준으로 요금이 부과됩니다.
- 처리 단위는 MU(Model Unit) 기준입니다. 분당 처리 가능한 토큰 수로 정해집니다.
- 약정 없이 시간당 과금되며, 1개월 또는 6개월 약정을 걸면 할인 가능합니다.
3. 기타 비용
학습 데이터, 학습 결과, 로그 등은 S3에 저장됩니다. 이 역시 별도 과금이 됩니다.
- S3 스토리지: 학습에 필요한 모든 파일 저장 용도
자세한 가격 정보: AWS Bedrock 공식 가격 페이지
Bedrock Fine-Tuning 준비 체크리스트
Fine-Tuning을 하려면 몇 가지 조건을 미리 확인해야 합니다. Bedrock이라는 플랫폼을 사용한다고 해서 모든 것이 가능한 것은 아닙니다.
1. 지역 제한
현재(25년 5월 기준) Fine-Tuning은 다음 두 리전에서만 가능합니다:
- US East (N. Virginia)
- US West (Oregon)
2. 모델 제한
우리가 알고 있는 모든 모델을 Fine-Tuning에 사용할 수 있는 것은 아닙니다. Bedrock에서 제공하는 모델 중에서도 Fine-Tuning이 가능한 모델은 제한적이며, 모델이 지원하는 커스터마이징 유형 도 다릅니다. 예를 들어 어떤 모델은 Text-to-Text만 가능하고, 어떤 모델은 Text-to-Image를 지원하는 등 사용 목적에 따라 선택이 필요합니다. 자세한 사항은 아래 공식 문서를 참고 해 주세요.
AWS Bedrock 공식 문서: 모델과 커스터마이징 유형
실습하기
위에서 살펴본 제약 사항들을 염두에 두고, 이제 Bedrock에서 Fine-Tuning을 진행하며 이론적인 개념이 실제로 어떻게 적용되는지 확인해봅시다.
1부에서 설명한 Fine-Tuning의 핵심 과정인 "예측 → 오차 계산 → 행렬 수정 → 다시 예측"을 떠올려봅시다. Bedrock을 사용할 때 장점은 오차 계산과 행렬 수정이라는 복잡한 과정을 모두 자동으로 처리해준다는 것입니다.
그럼 우리가 해야할 일은 무엇일까요?
바로 우리가 원하는 방향성이 담긴 데이터를 준비하는 것입니다. 즉, 입력(Input) + 정답(Output) 쌍으로 구성된 학습 데이터가 있어야 합니다.
우리의 데이터를 모델에 반복해서 학습시키면, 모델은 "이런 질문엔 이렇게 대답해야 하는구나" 하고 패턴을 인식하게 됩니다. 모델마다 요구하는 데이터 포맷이 조금씩 다르므로 템플릿은 아래 문서를 참고해서 작성하고, S3에 업로드하면 됩니다:
AWS Bedrock 모델 커스터마이징 데이터 가이드
이번 실습에서는 Haiku 모델을 사용할 예정입니다. Haiku는 single-turn(단일 대화) 및 multi-turn(다중 대화) 형식을 지원하며, 학습 데이터는 .jsonl 형식으로 저장해야 합니다.
.jsonl은 JSON 객체 하나를 한 줄에 하나씩 적는 방식입니다. 각 줄이 하나의 학습 예제가 되는 구조입니다.
Haiku 데이터 셋 예시
// 단일 대화(single turn) 예시
{
"system": "너는 친절한 쇼핑 도우미야.",
"messages": [
{"role": "user", "content": "여름에 입기 좋은 옷은?"},
{"role": "assistant", "content": "통기성이 좋은 반팔티가 적당합니다."}
]
}
// 다중 대화(multi-turn) 예시
{
"system": "너는 고객에게 친절하고 정확하게 제품 정보를 안내하는 쇼핑 도우미야.",
"messages": [
{ "role": "user", "content": "요즘 인기 있는 여름용 바지 추천해줘." },
{ "role": "assistant", "content": "네! 통기성이 좋고 얇은 린넨 소재의 와이드 팬츠가 요즘 인기 많아요. 특히 베이지나 카키 컬러가 많이 팔리고 있어요." },
{ "role": "user", "content": "가격대는 어느 정도야?" },
{ "role": "assistant", "content": "브랜드에 따라 다르지만, 보통 3만 원대에서 7만 원대 사이 제품들이 많이 판매되고 있어요." }
]
}실습 절차 정리
데이터 준비가 끝났으면 이제 콘솔에서 학습 Job을 만드는 일만 남았습니다.
- Bedrock 콘솔 접속 → 리전을 Virginia 또는 Oregon으로 설정
- Custom Models → Create fine-tuning job 클릭
- 모델 선택: Haiku
- S3 데이터 경로 입력 (.jsonl)
- Validation dataset (선택 사항으로 학습에 사용되지 않은 별도의 데이터)
- Hyperparameters 설정:
- Epoch: 전체 데이터를 몇 번 반복 학습할지
- Batch size: 한 번에 몇 개 예제를 학습할지
- Learning rate: 가중치를 얼마나 빠르게 조정할지
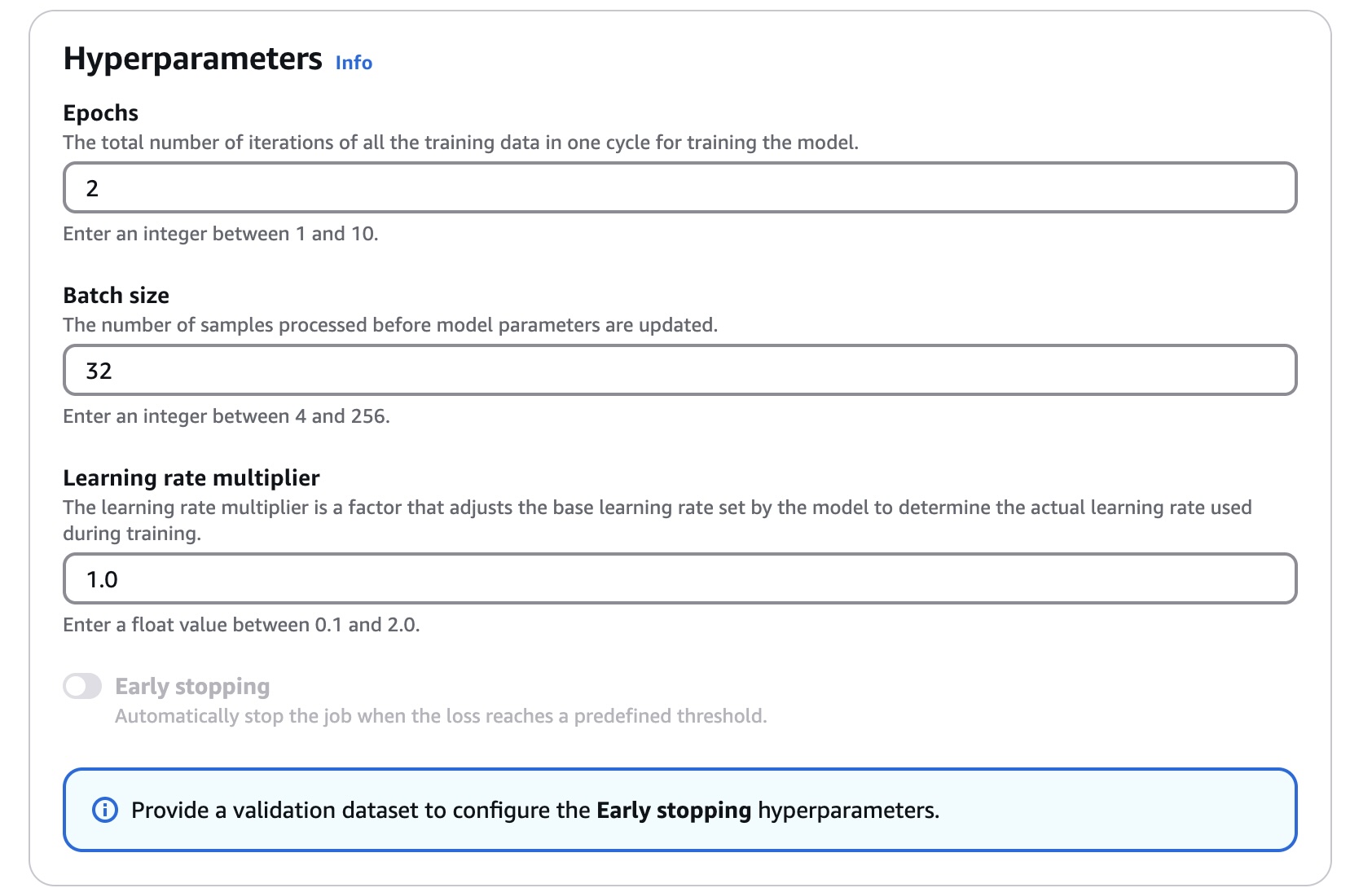
Hyperparameters와 Validation dataset에 대해 잠깐 설명하자면…
1부에서는 따로 설명하지 않았지만, 실제 Fine-Tuning 단계에서는 이 값들이 모델의 학습 결과에 큰 영향을 미칩니다.
- Epoch: 전체 데이터셋을 몇 번 반복해서 학습할지 결정합니다. 너무 많으면 과적합(overfitting)이 발생하고, 너무 적으면 학습이 부족할 수 있습니다.
- Batch size: 한 번에 처리할 데이터 샘플 수입니다. 너무 크면 메모리 사용량이 급증하고, 너무 작으면 학습 속도가 느려집니다.
- Learning rate: 모델이 각 학습 단계에서 가중치를 얼마나 크게 조정할지 결정합니다. 너무 크면 학습이 불안정해지고, 너무 작으면 학습이 제대로 진행되지 않을 수 있습니다.
- Validation dataset
더 깊이 이해하고 싶다면 아래 키워드를 추가로 공부해보는 것을 추천드립니다.
Adam, SGD, Learning rate warmup, decay, Curriculum Learning, ...
지금 단계에서는 "모델이 데이터의 패턴을 효과적으로 학습하며, 과도하게 외우지 않도록 균형을 맞추는 과정"이라고 이해하면 충분합니다.
Hakiku model의 경우 Claude 3 Haiku 파인튜닝 모범 사례 및 교훈이 있으니 이를 참고하여 자신의 데이터에 맞게 설정해주시면 됩니다.
- IAM Role 설정
- S3에 접근하고 결과를 쓸 수 있는 권한을 가진 서비스 역할이 필요합니다.

모델 성능 평가하기
Fine-Tuning이 끝났습니다 🥳🥳
모델이 잘 작동하면 좋겠지만… 사실 막상 결과를 보면, 뭔가 조금씩 어긋날 때가 많습니다. 제대로 배운 줄 알았는데, 기대한 대답은 잘 안 나오는 느낌이죠.
그래서 여기서 중요한 게 하나 더 필요합니다. 바로, 평가입니다. 그럼 아래와 같은 의문이 듭니다.
“무엇을 평가할까?”
“그리고 그걸 어떻게 평가하지?”
다행히 유명한 벤치마크들이 있고, 손쉽게 자동화해주는 도구들이 존재합니다. Bedrock에서도 평가 기능을 제공하지만, 저의 경우 모델을 학습시길 때 Bedrock도 사용하고, Hugging Face로 Gemma도 직접 Fine-Tuning 했습니다. 이 두 모델에 대한 일관된 평가를 위해 자동화 도구인 lm-evaluation-harness를 사용했습니다.
lm-evaluation-harness 이란?
lm-evaluation-harness는 다양한 언어 모델을 통일된 프레임워크에서 평가할 수 있게 해주는 도구입니다. 주요 특징은 아래와 같습니다.
- 60개 이상의 학술 벤치마크를 지원하며, 수백 개의 세부 태스크와 변형이 구현되어 있음
- Hugging Face, vLLM 등 다양한 모델 로딩 방식 지원
- OpenAI API 등 상용 API 지원
- 커스텀 벤치마크 생성 가능: 템플릿만 맞추면 나만의 벤치마크도 쉽게 등록하고 코드로 테스트할 수 있음
Bedrock Haiku 평가 시 주의사항
Bedrock의 Haiku 모델을 평가할 때는 몇 가지 주의사항이 있습니다.
- loglikelihood 기반 평가는 지원하지 않습니다.
loglikelihood는 정답 토큰이 나올 확률을 계산해 점수화하는 방식인데, Haiku API에서는 이 기능을 제공하지 않습니다. - generate_until 기반 평가만 가능합니다.
주어진 문맥에서 모델이 우리가 원하는 정답 문자열을 정확히 생성했는지를 기준으로 평가하는 방식입니다. - lm-evaluation-harness에서 Bedrock API를 바로 호출할 수 있는 구현체는 기본으로 제공되지 않습니다.
직접 bedrock.py 모듈을 만들어 붙여야 합니다.
참고로, 저는PR과 API Model을 참고해서 bedrock.py 모듈을 직접 작성했습니다. 그리고 모델 평가를 위해 커스텀 벤치마크도 만들어 사용했습니다.
그럼 이제 아래와 같은 Python 코드로 Bedrock 모델을 바로 평가해볼 수 있습니다. (물론 CLI 환경에서 Bash 명령어로도 실행할 수 있습니다)
import lm_eval
from lm_eval.models.bedrock import BedrockChatLM
# 사용할 Bedrock 모델 ID 입력 (예: 'anthropic.claude-3-haiku-20240307-v1:0')
model_id = ""
# 평가할 태스크 리스트 지정 (예: ["kmmlu", "kobest"] 등)
tasks = []
# Bedrock 모델 래퍼 객체 생성
lm_obj = BedrockChatLM(
model=model_id,
base_model="haiku",
max_gen_toks=2048,
temperature=0,
)
# 평가 실행
results = lm_eval.simple_evaluate(
model=lm_obj,
tasks=tasks,
num_fewshot=0,
)
...해당 평가를 실행 하하고 결과를 저장하면 아래와 같은 파일을 받을 수 있습니다!
{
"results": {
"kmmlu_direct_criminal_law": {
"alias": "kmmlu_direct_criminal_law",
"exact_match,none": 0.355,
"exact_match_stderr,none": 0.03392091008070854
},
"kmmlu_direct_education": {
"alias": "kmmlu_direct_education",
"exact_match,none": 0.57,
"exact_match_stderr,none": 0.04975698519562426
},
....결론
지금까지 LLM의 기본 원리부터 Bedrock을 활용한 Fine-Tuning, 그리고 실제 평가까지 차근차근 함께 살펴봤습니다.
물론 여기서 다룬 내용은 전체 그림을 이해하기 위한 추상적인 수준이라, 실제 LLM을 깊이 이해하려면 공부할 게 정말 많습니다.
하지만 큰 틀을 이해한다면, 앞으로 세부적인 기술을 배울 때 이게 왜 필요한지, 어디에 쓰이는지를 파악하는 데 도움이 될 것이라 생각합니다.
LLM과 Fine-Tuning의 세계는 생각보다 훨씬 넓고, 깊습니다.
이 글이 그 첫발을 내딛는 데 작은 디딤돌이 되었으면 좋겠습니다.
긴 글 읽어주셔서 정말 감사합니다 :)
