0. 서론
단일 ec2 서버에 빅데이터 분산처리를 위한 hadoop cluster서버를 구축할 일이 생겼다. 원래는 다른 서버에 데이터노드와 네임노드를 만들어야 하지만 나에게 서버는 하나 밖에 없어 우분투 이미지를 바탕으로 각각 하둡을 설치해 master 1개와 worker 2개를 컨테이너로 만들어 연결해 분산처리를 해줬다.
1. BASE설치 및 환경설정
먼저 각각의 노드들이 공통적으로 필요한 것들을 설치하고 공통적으로 필요한 설정들을 진행한다.
docker run -i -t --name hd-base ubuntu 먼저 우분투 이미지를 컨테이너로 실행시킨다. 이 컨테이너를 바탕으로 하둡을 설치해 각각의 머신으로 사용할 예정이다.
apt-get update ;
apt-get upgrade -y ;
apt-get install -y curl openssh-server rsync wget vim iputils-ping htop openjdk-8-jdkssh, vim, jdk8등 필요한 것들을 설치한다.
wget http://mirror.navercorp.com/apache/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
tar zxvf hadoop-3.2.3.tar.gz
rm hadoop-3.2.3.tar.gz
mv ./hadoop-3.2.3 /usr/local/hadoop/이후 하둡을 설치한다. wget을 이용해 원하는 버전을 다운받는다 나는 3.2.3버전을 받았다. 아래 사이트에서 원하는 버전의 하둡을 설치하자
하둡 설치이후 master, worker 모두에게 공통적으로 필요한 설정을 해줄 것이다.
a. 환경변수세팅
vi ~/.bashrc
아래 내용을 덧붙인다.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
편집기에서 나와 아래 명령을 실행시켜준다.
source ~/.bashrcb. core-site.xml세팅
vi $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master1:9000</value>
</property>
</configuration>c. yarn-site.xml 세팅
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>d. mapred-site.xml세팅
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>e. masters 세팅
masters파일이 없을 수도 있다. 당황하지 말고 그냥 master로 사용할 컨테이너의 이름을 넣고 저장하자 나는 master1으로 지정했다.
vi $HADOOP_HOME/etc/hadoop/masters
master1f. workers 세팅
master와 worker로 사용할 컨테이너들의 이름을 넣으면 된다.
vi $HADOOP_HOME/etc/hadoop/workers
master1
worker1
worker22. master, worker 컨테이너 생성
a. 이미지 커밋
docker commit -m "hadoop install in ubunu" <container id> ubuntu:hadoopb. 컨테이너 생성
sudo docker run -i -t -h master1 --name master1 -p 29870:9870 -p 28088:8088 -p 29888:19888 ubuntu:hadoop
sudo docker run -i -t -h worker1 --name worker1 --link master1:master1 ubuntu:hadoop
sudo docker run -i -t -h worker2 --name worker2 --link master1:master1 ubuntu:hadoopc. 컨테이너 ip확인
docker inspect worker1
docker inspect worker2 d. hosts설정
각각의 컨테이너 bash로 접속해 아래 내용을 추가해주자
vi /etc/hosts
아래 내용을 덧붙인다
<IP주소> master
<IP주소> worker1
<IP주소> worker23. master, worker ssh키 생성
master,worker들은 서로 통신이 가능해야 한다. 따로 비밀번호 입력 없이 ssh로 통신이 가능하도록 설정했다. 이 작업은 생성한 컨테이너 모두에서 해줘야 한다. 즉 master1, worker1, worker2 까지 모두 해줘야한다.
a. key생성
master1, worker1, worker2에서 모두 해야한다.
ssh-keygen -t rsab. key 복사
생성된 public키를 복사하고 출력되는 키를 복사해서 어딘가에 잘 보관해 두자 master1, worker1, worker2가 서로의 public키를 보유하고 있어야 하기 때문이다.
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
cat ~/.ssh/authorized_keysc. key 등록
복사해 뒀던 각각의 public키를 복사해 주자 아래 사진처럼 그냥 붙여 넣어주면 된다.
vi ~/.ssh/authorized_keys
d. 접속확인
ssh를 이용해 서로서로 비밀번호 입력 없이 접속이 가능한지 확인해보자 정상적으로 public키를 등록했다면 문제없이 접속이 가능할 것이다. 정상적으로 접속 된 경우 아래와 같은 화면이 나오고 root@ 뒤 아이디가 바뀐다. 중간에 fingerprint관련된 설정이 나올텐데 그냥 yes해주면 된다.
ssh master1
ssh worker1
ssh worker2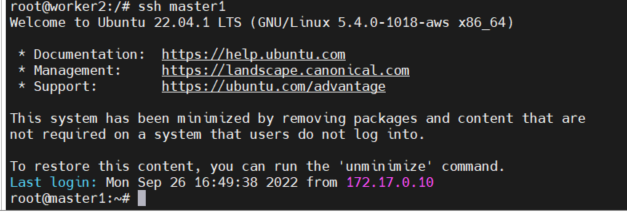
4. master 세팅
a. 디렉토리 생성
cd /usr/local/hadoop
mkdir -p hadoop_tmp/hdfs/namenode
mkdir -p hadoop_tmp/hdfs/datanode
chmod 777 hadoop_tmp/b. hadoop-env.sh 설정
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME='/usr/lib/jvm/java-8-openjdk-amd64'
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_RESOURCEMANAGER_USER=rootc. hdfs-site.xml 설정
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop_tmp/hdfs/datanode</value>
</property>
</configuration>5. worker 세팅
a. 디렉토리 생성
cd /usr/local/hadoop
mkdir -p hadoop_tmp/hdfs/datanode
chmod 777 hadoop_tmp/b. hadoop-env.sh 설정
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME='/usr/lib/jvm/java-8-openjdk-amd64'c. hdfs-site.xml 설정
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop_tmp/hdfs/datanode</value>
</property>
</configuration>6. 작동확인
a. hadoop 시작
master1에서 다음 명령어를 입력해 정상적으로 실행되는지 확인해보자
hdfs namenode -format
start-all.shb. jps명령어
각 노드에서 jps를 입력해본다. 다음과 같이 나오면 된다.
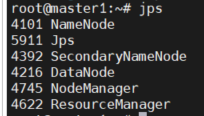
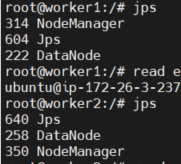
c. wordCount 실행
hdfs dfs -mkdir /input
hdfs dfs -copyFromLocal /usr/local/hadoop/README.txt /input
hdfs dfs -ls /input
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount /input/README.txt ~/wordcount-output혹시 hdfs dfs 명령어 입력시 다음과 같은 경고와 함께 명령어가 작동하지 않는다면
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
vi ~/.bashrc
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
를
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
로 수정해보자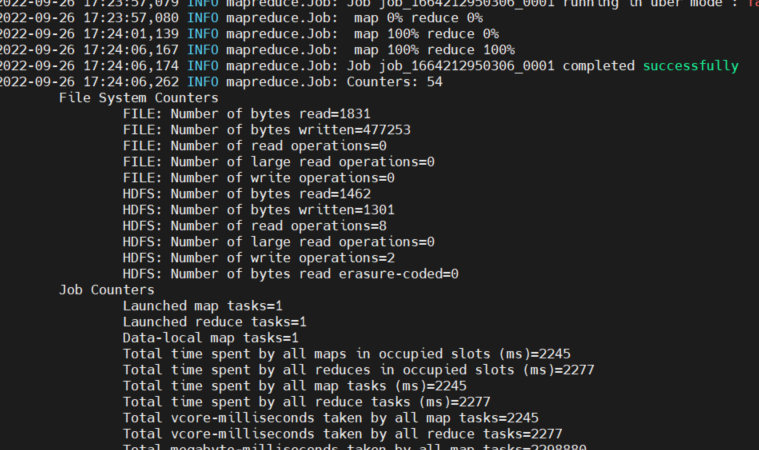
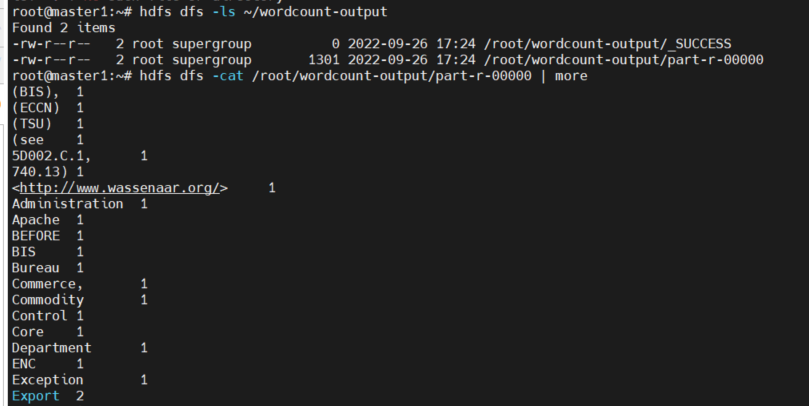
참고
https://it-sunny-333.tistory.com/79
https://eyeballs.tistory.com/144?category=748860
https://eyeballs.tistory.com/145
https://crmn.tistory.com/7
