앞서 작성한 Transformer 포스트에 이어 자연스럽게 BERT를 소개하게 되었습니다. 내용은 제가 알고있고 이해한 대로 작성을 하였습니다. Transformer의 개념을 알고있는 상태라면 좀 더 이해하기 쉬울거라 봅니다.
NLP에서 한 획을 그은 모델로 평가되는 BERT는 2018년 구글에서 공개한 사전 훈련 모델이다. 이름 그대로 Transformer 구조를 이용하여 구현되었고 위키피디아 25억 단어, BooksCorpus 8억 단어와 같은 레이블이 없는 텍스트 데이터를 통해 훈련된 모델이다.
이 사전 훈련된 BERT모델에 실제 하고자 하는 태스크를 위한 적절한 신경망 한 층을 추가하여 파인 튜닝(Fine-tuning)을 진행하면 원하는 태스크에서 훌륭한 성능을 얻을 수 있다.
(덕분에 대용량의 데이터를 처음부터 직접 학습 시킬 필요가 없어 엄청나게 많은 자원과 시간이 필요한 부담이 없어짐)
이렇게 하여 얻어낸 모델의 대표 사례로 ELMo나 GPT-1 등 이 있다.
1. BERT의 구조
1) BERT 크기
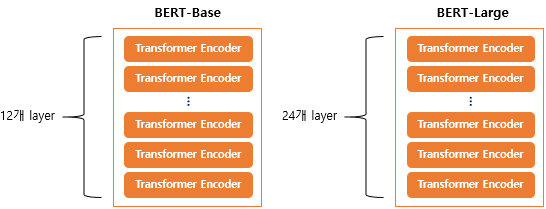
BERT의 기본 구조는 Transformer의 Encoder를 쌓아올린 구조이고 BERT는 Base 버전과 Lager버전 이렇게 대표적으로 2가지가 존재하는데, Base 버전은 위의 그림과 같이 encoder를 12개를 쌓은 구조이고, Large 버전은 24개를 쌓은 구조이다.
또 Base모델의 히든 레이어 차원 수 는 768개, Large모델은 1024개 이며, Base모델의 self attention head 수가 12개이고, Large모델은 16개 이다.
-
BERT Base Model
인코더 층 개수 : 12개
히든 레이어 차원수 : 768개
셀프 어텐션 헤드 수 : 12개 -
BERT Large Model
인코더 층 개수 : 16개
히든 레이어 차원수 : 1024개
셀프 어텐션 헤드 수 : 16개
2) BERT 입력
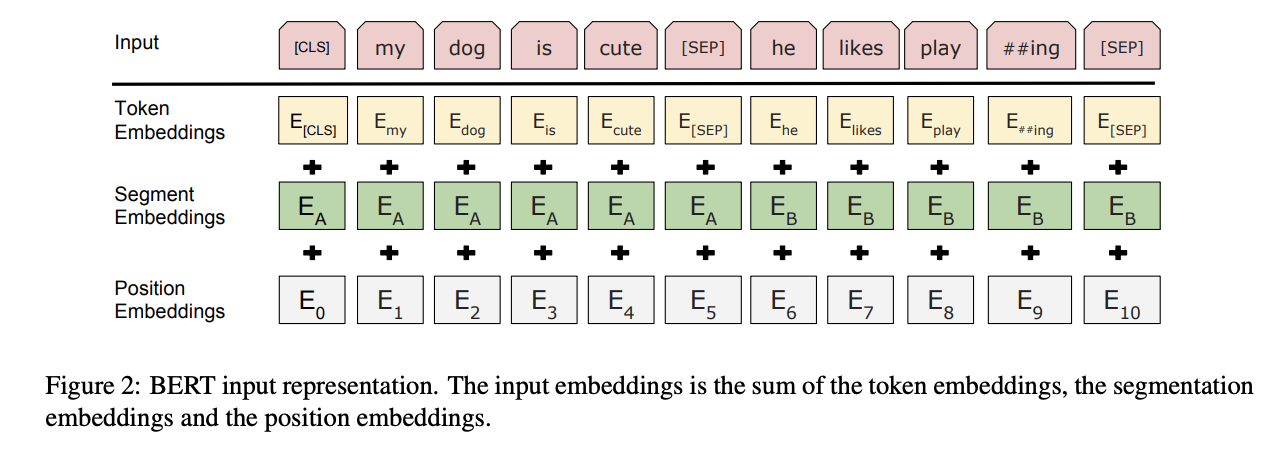
BERT의 입력은 일반적으로 위의 그림과 같이 Token Embeddings, Segment Embeddings, Position Embeddings 이 세가지를 더하여 사용한다.
2-1] Token Embeddings
토큰 임베딩은 입력 시퀀스 단어들을 임베딩 층에 통과시켜 히든 레이어 차원수의 크기를 지닌 임베딩 벡터로 만든다.
이를 위해 BERT에서는 WordPiece 서브워드 토크나이저를 사용한다.
WordPiece의 토큰화 방식은 자주 등장하는 단어는 단어 집합에 추가하고, 자주 등장하지 않는 단어는 더 작은 단위인 서브워드로 분리하여 단어 집합에 추가를 하는 방식이다.
이러한 방식은 기존의 토크나이저에서 자주 등장하지 않는 단어를 OOV(Out-of-vocabulary)로 처리하는 문제를 해결할 수 있다.
그래서 실제로 토큰화를 진행할 때 이미 만들어진 단어 집합이 있다는 전제로 해당 토큰이 단어 집합에 존재한다면 토큰을 분리하지 않고 그대로 진행하고, 해당 토큰이 단어 집합에 존재하지 않는다면 토큰을 서브워드로 분리하여 분리된 서브워드들 중 첫번째 서브워드를 제외한 나머지 서브워드의 앞에 "##" 을 붙여 토큰으로 사용한다.
예를들어 embeddings 라는 단어가 입력되었을 때 embeddings 라는 단어가 단어 집합에 존재 하지 않는다면 이를 단어 집합에 존재하는 서브워드 들로 분리를 시도하는데 em, ##bed, ##ding, #s 이런 서브워드가 단어 집합에 존재한다면 최종적으로 embeddings 라는 단어는 em, ##bed, ##ding, #s 로 분리된다.
그리고 모든 입력 시퀀스의 가장 앞에는 [CLS] 라는 토큰을 사용하는데, 이는 모든 단어 벡터 입력이 BERT의 모든 층을 거친 후에 모든 토큰의 문맥 정보를 가진 벡터가 된다.(모든 단어를 참고하는 벡터가 됨)
그리고 입력의 문장을 구분하는 역할로 [SEP] 이라는 토큰 또한 사용되고, 패딩 토큰을 뜻하는 [PAD] 또한 사용된다.
2-2] Segment Embeddings
Segment Embeddings는 두 개의 문장 입력이 필요한 태스크를 위한 임베딩이다. 쉽게 말해 입력된 두 개의 문장을 구분하기 위해 첫번째 문장(첫번째 [SEP] 토큰을 만나기 까지)에는 0 으로 임베딩, 두번째 문장(그 다음 [SEP] 토큰 까지)에는 1 로 임베딩 한다.
위의 그림에서는 0대신 A, 1대신 B 로 표현 하였음
2-3] Position Embeddings
Transformer 에서는 Positional Encoding(포지셔널 인코딩)을 사용하여 단어의 위치 정보를 참고하도록 하였다. BERT는 이를 학습을 통해 얻는 포지션 임베딩(Position Embedding) 방법을 사용한다.
첫번째 입력 토큰부터 차례대로 0, 1, 2, 3... 으로 임베딩하여 임베딩 값을 얻어낸다.
이렇게 하여 얻어낸 모든 임베딩 값들을 모두 더하여 BERT의 입력 벡터로 사용한다.
2. BERT의 사전 훈련 (Pre-training)
BERT의 사전 훈련 방식은 크게 2가지로 나뉜다.
- 마스크 언어 모델(Masked Language Model, MLM)
- 다음 문장 예측(Next Sentence Prediction, NSP)
1) 마스크 언어 모델((Masked Language Model, MLM)
BERT의 사전 훈련 시 입력으로 들어가는 텍스트 단어들의 15%의 단어들을 무작위로 마스킹([MASK])을 한다. 그리고 이 마스킹 된 단어들을 예측하도록 훈련한다.
쉽게 말해 입력 문장에서 단어 몇개를 가려놓고 이 단어들이 뭔지 맞춰 보라는 식으로 훈련을 하는 것이다.
그러나 15%에 선정된 모든 단어들을 다 마스킹 하는것은 아니고 선정된 단어들 중 80%는 [MASK] 토큰으로 마스킹, 10%는 무작위의 단어로 변경, 나머지 10%는 변경하지 않고 그대로 둔다.
예를들어
My dog is cute and pretty 라는 문장에서
[cute] 라는 단어가 15%에 선정되었다고 할때
80%는 [MASK]으로 마스킹
My dog is cute and pretty -> My dog is [MASK] and pretty
10%는 무작위의 단어로 변경
My dog is cute and pretty -> My dog is angry and pretty
10%는 변경하지 않고 그대로 둔다
My dog is cute and pretty -> My dog is cute and pretty이렇게 변경하여 입력에 들어가게 되는데 실제로 학습되는 예시는 쉬운 설명을 위해 위키독스의 글에 적힌 예시를 그대로 사용 한다.
'My dog is cute. he likes playing'
라는 문장을 사용하여 예시를 들것이다.
먼저 'dog' 라는 단어 한개가 15%의 확률에 선정되어 변경되는 경우의 예시를 보자.
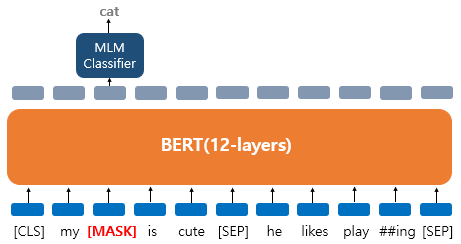
위의 그림은 'dog' 라는 토큰이 [MASK]로 변경되어서 입력으로 들어가 BERT 모델이 [MASK] 토큰의 위치에 있던 원래 단어를 맞추고자 하는 상황이다.
이런 경우 손실 함수를 통해 손실값을 계산하는 과정에서 15%의 확률에 든 'dog' 토큰을 제외한 나머지 토큰은 손실값 계산에 영향을 주지 않게 된다.
즉 손실값에 영향을 주는것은 15%의 확률에 들어 변경된 'dog' 토큰 위치의 출력층 벡터 뿐이다.
그럼 다음 예시로 단어 한개가 아닌 여러개의 단어가 15%의 확률에 들어 변경되거나 그대로 사용되어 진다고 치자.
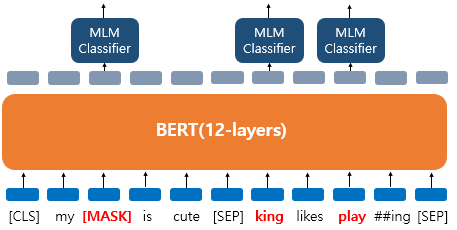
위의 그림에서 보면
- 'dog' 토큰이 [MASK]로 변경됨
- 'he' 토큰이 무작위 단어 'king' 으로 변경됨
- 'play' 토큰은 15%에 선정은 되었지만 변경되지 않고 그대로 사용됨
이런 경우 'dog', 'he' 토큰은 물론이고 변경되지 않은 'play' 토큰 또한 예측 및 손실값 계산에 사용된다. 왜냐면 이 BERT모델은 'play' 라는 토큰이 무작위 단어로 변경된 상태인지, 변경되지 않고 그대로 들어온 단어인지 모르기 때문이다.
2) 다음 문장 예측(Next Sentence Prediction, NSP)
BERT는 두 개의 문장이 주어 졌을 때 이 두개의 문장이 서로 이어지는 문장인지를 맞추도록 훈련시키는데, 두 개의 문장 간의 관계를 이해하도록 훈련되는 방식이다.
이를 위해 문맥상 서로 이어지는 문장 두 개와 이어지지 않는 문장 두 개의 선정 비율을 1:1 로 하여 훈련을 하게 된다.
예를들어
이어지는 문장의 예시는
- 첫번째문장 : 나는 밥을 먹었다
- 두번째문장 : 그리고 디저트도 먹었다
- 라벨 : 이어짐
이어지지 않는 문장의 예시는
- 첫번째문장 : 나는 밥을 먹었다
- 두번째문장 : 날씨가 정말 흐리다
- 라벨 : 이어지지않음입력으로 사용할때는 첫번째 문장과 두번째 문장 사이에 [SEP] 라는 문장 구분을 위한 토큰을 사용하고 두번째 문장의 끝에도 [SEP] 토큰을 사용한다.
그리고 문장이 이어지는지 아닌지를 위한 출력은 입력의 [CLS] 토큰 위치의 출력층에서 출력되도록 한다.
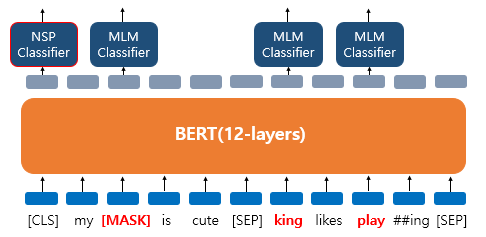
그래서 그림과 같이 MLM과 NSP 두가지의 훈련 방식은 동시에 이루어 질 수 있게된다.

최고의 포스팅입니다!!