이전 글에서 살펴본 대로 DistributedDataParallel(DDP)는 data parallel training을 가능하게 해준다. Data parallel training은 multi-GPU에서 겹치지 않는 data batch를 받아 학습이 진행되는 방식이다. Pytorch에서 DistributedSampler가 data batch가 겹치지 않게 device에 할당되도록 하는 역할을 한다. model은 모든 device에 복제되고, 각각의 device에서 gradient를 계산하고 model은 동기화 되어 학습이 진행된다. model의 동기화를 유지하기 위해 ring all-reduce algorithm을 사용한다.
Ring All-Reduce Algorithm
Synchronized Data-Parallelism
모델의 동기화를 유지한 채 data-paralle training을 위한 graident 연산은 다음과 같은 주요 단계를 거친다.
- 각 GPU에서 mini-batch를 받아 loss function에 대한 gradient를 계산
- GPU간 통신을 통해 gradient들에 대한 mean을 계산
- model update
이때 gradient의 mean을 계산하기 위한 알고리즘으로 All-Reduce algorithm을 사용한다.
Algorithms of All-Reduce
All-Reduce algorithm은 모든 proeccess의 array를 하나의 array로 만들어(reduce) 모든 process에 만들어진 array를 반환하는 알고리즘이다.
를 전체 procees의 수라고 하고 을 각 process의 array length, 를 procees의 번 째 element라고 할때, result array 의 번 째 element 는 다음과 같다.
이때 는 binary operation으로 deep learning에서는 주로 SUM 연산을 사용한다.
다음은 가 4이고 이 4일 때의 예시 사진이다.
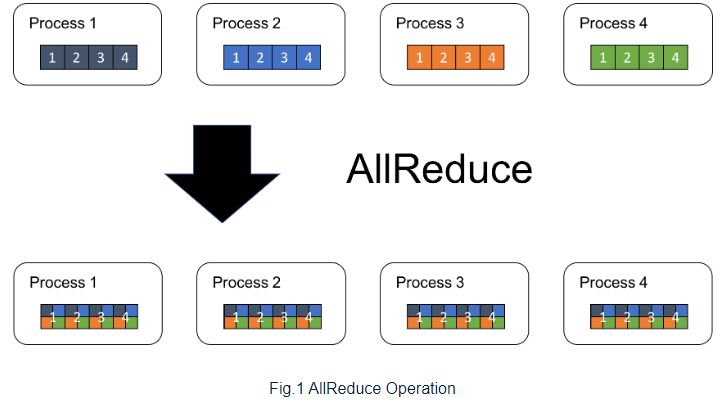
Ring All-Reduce
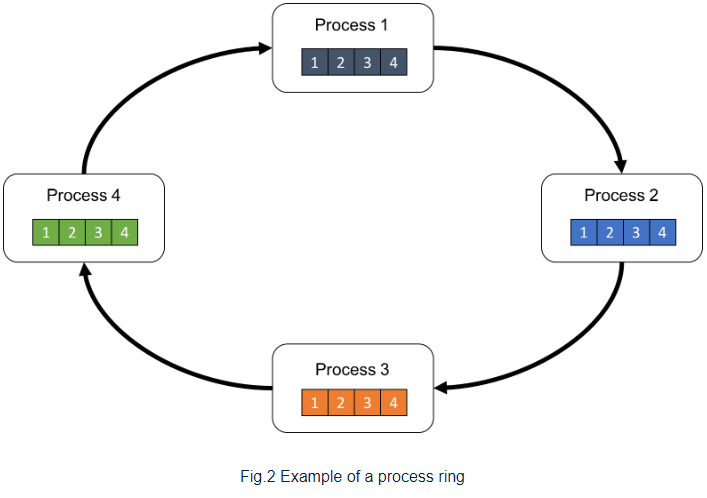
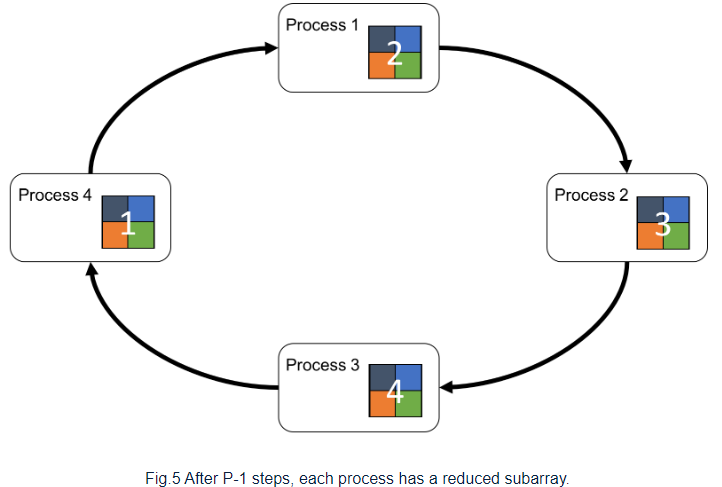
위에서 본 process를 하나의 ring으로 구성하면 다음과 같이 표시할 수 있다.
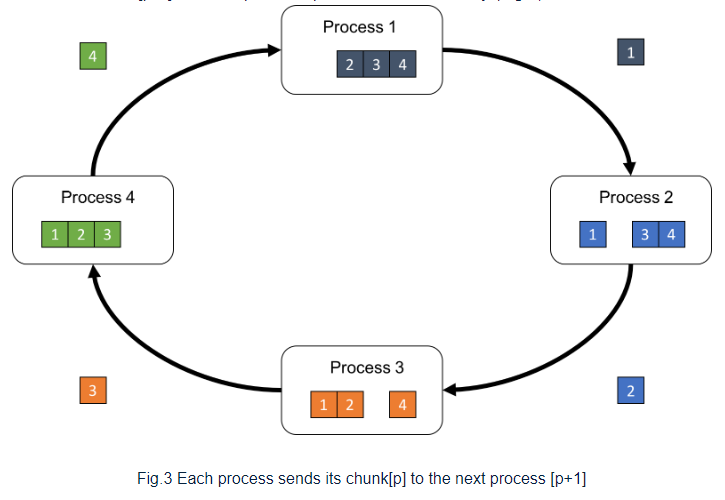
먼저 각각의 process 내 array를 subarray로 나눈다. 나누어진 subarray를 chunk라고 부르고 chunk[p]는 p번 째 chunk를 의미한다. 각 process의 chunk[p]를 다음 process로 보내고, 이전 process로 부터 chunk[p-1]를 받는다.
이전 process로 부터 chunk[p-1]을 받은 각각의 process는 자신의 process에 있는 chunk[p-1]과 reduce(binary operation, SUM)을 진행하고 다음 process로 넘긴다.
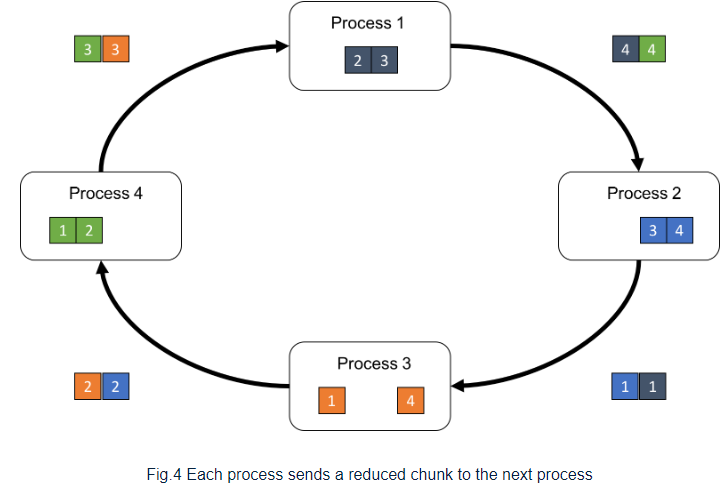
위의 recieve-reduce-send 과정을 P-1 번 반복하여 모든 process가 각 process의 다른 chunk를 얻도록 만들어 all-reduce algorithm을 마친다.
Why You should Prefer DDP over DataParallel(DP)
DP는 Pytorch의 오래된 data parallelism 방식으로 DDP에 비해 더 낮은 performance를 보여준다. 대신 코드 작성은 더 simple 하다.
다음은 DP와 DDP에 대한 비교 표이다.

참고 문서
