
1. Enum (열거형)
Public static final 형식의 상수를 마치 클래스 다루듯 만든 것을 의미한다.
public enum Grade {
BASIC,
VIP
}Member 클래스 안에 각 Member마다 등급을 정해주기 위해 Grade enum을 만들었다.
상기 BASIC, VIP는 static 변수를 참조하는 것처럼 활용할 수 있다.
@Test
void join() {
//given
Member member = new Member(1L,"memeberB", Grade.VIP);
//when
memberService.join(member);
Member findMember = memberService.findMember(1L);
//then
Assertions.assertThat(member).isEqualTo(findMember);
}//given 부분에 Grade.VIP로 활용된 모습을 볼 수 있다.
이 Enum은 기본적으로 String이고, switch문에서도 활용할 수 있다.
public static final과 달리 서로 다른 enum으로 만들면 간단하게 같은 이름의 상수도 구분할 수 있다.
public static fianl은 같은 이름의 상수가 있을 경우 이를 구분짓기가 조금 복잡해진다. (그래도 안쓰는건 아님)
| 리턴 타입 | 메소드(매개변수) | 설명 |
|---|---|---|
| String | name() | 열거 객체가 가지고 있는 문자열을 리턴, 리턴되는 문자열을 열거타입을 정의할 때 사용한 상수 이름과 동일 |
| int | ordinal() | 열거 객체의 순번(0부터 시작)을 리턴합니다. |
| int | compareTo(비교값) | 주어진 매개값과 비교해서 순번 차이를 리턴합니다. |
| 열거타입 | valueOf(String name) | 주어진 문자열의 열거 객체를 리턴합니다. |
| 열거배열 | values() | 모든 열거 객체들을 배열로 리턴합니다. |
2. 어노테이션 (Annotation)
이 어노테이션이 얼마나 많은 일을 해주는지 캬캬
어노테이션은 클래스에 붙이든, 메서드에 붙이든, 변수에 붙이든 다양한 조건에서 많은 일을 해준다.
게터세터를 대신 만들어준다던가, 메서드가 오버라이드인걸 알려준다거나, 이게 테스트 메서드인걸 알려준다거나 한다.
- 컴파일러에게 문법 에러를 체크하도록 정보 제공
- 빌드시 자동으로 코드를 생성해주기도 함
- 런타임에 특정 기능을 실행하도록 정보 제공
대충 이 정도를 지원해준다.
표준 애너테이션
자바에서 기본적으로 제공하는 애너테이션임.
| 표준 애너테이션 | 설명 |
|---|---|
| @Override | 컴파일러에게 메서드를 오버라이딩하는 것이라고 알림 |
| @Deprecated | 앞으로 사용하지 않을 대상을 알릴 때 사용 |
| @FunctionalInterface | 함수형 인터페이스라는 것을 알림 |
| @SuppressWarning("옵션") | 컴파일러가 경고메세지를 나타내지 않음 |
메타 애너테이션
애너테이션을 정의할 때 사용하는 애너테이션임.
| 메타 애너테이션 | 설명 |
|---|---|
| @Target | 애너테이션을 정의할 때, 적용 대상을 지정하는데 사용함 |
| @Documented | 애너테이션 정보를 javadoc으로 작성된 문서에 포함시킨다. |
| @inherited | 애너테이션이 하위 클래스에 상속되도록 한다. |
| @Retention | 애너테이션이 유지되는 기간을 정하는데 사용한다. |
| @Repeatable | 애너테이션을 반복해서 적용할 수 있게 한다. |
@Target 애너테이션은 ()에 옵션으로 열거형을 먹는다.
@Target({ElementType.FIELD, ElementType.METHOD, ElementType.PARAMETER, ElementType.TYPE, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
@Qualifier("MainDiscountPolicy")
public @interface MainDiscountPolicy {
}MainDiscountPolicy라는 어노테이션에 @Target을 보면 필드, 메서드, 파라미터, 타입(클래스, 인터페이스, 열거형)을 대상으로 함을 알 수 있다.
기타 다양한 메타 어노테이션이 있으니까 공부해서 직접 만들어야함... 여기 이거로는 쫌 부족?
3. Lambda
JavaScript를 다뤘다면 꽤 익숙한 방식의 함수다.
화살표함수라고 표현했던거 같은데, 아마 원래 이름이 람다였나보다.
Hello hello = new Hello() {
public void hi() { }
}
Hello hello = () => {...}상기 2개의 코드는 같은 뜻이다.
자바스크립트 하고 왔으면 꽤 익숙한 방식일건데, 자바스크립트에선 저 화살표 함수로 별 의 별 짓을 다 하고 있었다.
예시로 간단하게 보자
예시
@FunctionalInterface
public interface SumLambda {
public int sum(int[] a);
}@FunctionalInterface는 옵션이다.
그리고 이건 int값을 return하고 매개변수로 int배열을 받는다.
SumLambda hello;
hello = (arr) -> {
int sum = 0;
for(int i : arr){
sum+= i;
}
return sum;
};SumLambda를 선언하고 hello라고 명명해줬음
이제 네녀석은 sum을 뱉는 녀석이 된다.
매개변수에 배열 arr을 받으면
이녀석을 다 합치고 sum을 return을 하도록 지정
int[] b = {1,2,3,4,5,6,7,8,9,10};
System.out.println("hello = " + hello.sum(b)); // hello = 55 출력우린 sum값을 만드는 람다형 함수를 만든거다.
메서드 레퍼런스
(x, y) -> Math.max(x, y);상기 코드는 x와 y중 큰 수를 리턴하는 람다식 메서드 호출이다.
매번 Math.max를 부르기엔 매우 귀찮을 수 있다. 이때 쓰는데 메서드 레퍼런스다.
Math::max를 이용하면 좀 더 이용이 쉬워진다.
@FunctionalInterface
public interface SumLambda {
public int big(int a, int b);
}인터페이스를 조금 고치자. 이름은 신경쓰지 말자, 전에 있던거 고쳐쓴거니까 ㅋㅋㅋㅋ
SumLambda hello;
hello = Math::max;hello를 Math클래스의 max 메서드를 부르는 것으로 정의하자.
int x = 10;
int y = 7;
int big = hello.big(10, 7);
System.out.println("big = " + big); // 10이 출력이런 식으로 가능하다.
이걸 어디다가 쓰냐고? 스트림에서는 이 람다식이 필수다.
4. 스트림
스트림은 자바스크립트처럼 함수형 메서드를 쭉쭉 써나가기 위해 만들어진 것으로 보인다.
filter나 map, forEach같은 메서드들은 Js로 알고리즘 풀 때 꽤 자주 이용해먹었다.
개요와 예시
stream은 다양한 메서드를 체인으로 연속적으로 계산할 수 있다.
이 때 생성되는 클래스가 다 다른데 이 중간 클래스를 문제 없이 알아서 불러오는 파이프라인이 형성되어 있다.
int answer = 0;
int[] a = {1,2,3,4,5,6,7,8,9,10};
for (int i : a) {
answer+= i;
}
System.out.println("Basic sum = " + answer);
int sum = Arrays.stream(a).sum();
System.out.println("stream sum = " + sum);똑같이 sum을 해주지만 방식이 좀 다르다. 여기에 짝수라는 조건도 추가해서 합을 해보자
for (int i : a) {
if(i % 2 == 0){
answer+= i;
}
}
System.out.println("Basic sum = " + answer);
int sum = Arrays.stream(a)
.filter(e -> e % 2 ==0)
.sum();
System.out.println("stream sum = " + sum);이렇게 변한다. 좀 더 복잡해 질 수록 람다식으로 이루어진 스트림이 편리하게 느껴질 거다.
이번엔 배열이 다 String이라고 생각해보자
int answer = 0;
String[] str = {"1","2","3","4","5","6","7","8","9","10"};이걸 짝수만 합해야 한다면, str의 요소들을 각각 Integer로 바꾸고 합해줘야 한다.
대충 코드를 짜보면
int[] a = new int[str.length];
for (int i = 0; i < str.length; i++) {
a[i] = Integer.valueOf(str[i]);
}
for (int i : a) {
if(i % 2 == 0){
answer+= i;
}
}대신 stream으로 짜보면
int sum = Arrays.stream(str)
.mapToInt(i -> Integer.valueOf(i))
.filter(e -> e % 2 ==0)
.sum();이거면 된다. 걸리는 시간은 로직에 따라 다르겠지만 상기 로직으로 숫자를 늘려본다면
long answer = 0;
String[] str = new String[100000000];
for (int i = 0; i < 100000000; i++) {
str[i] = i+"";
}
// 요기부터 일반적인 코드
long beforeTime = System.currentTimeMillis();
long[] a = new long[str.length];
for (int i = 0; i < str.length; i++) {
a[i] = Long.valueOf(str[i]);
}
for (long i : a) {
if(i % 2 == 0){
answer+= i;
}
}
long afterTime = System.currentTimeMillis();
double secDiffTime = (afterTime - beforeTime);
System.out.println("Basic time = " + secDiffTime + "ms");
System.out.println("Basic sum = " + answer);
//요기부터 스트림
beforeTime = System.currentTimeMillis();
long sum = Arrays.stream(str)
.mapToLong(i -> Long.valueOf(i))
.filter(e -> e % 2 ==0)
.sum();
afterTime = System.currentTimeMillis();
secDiffTime = (afterTime - beforeTime);
System.out.println("stream time = " + secDiffTime + "ms");
System.out.println("stream sum = " + sum);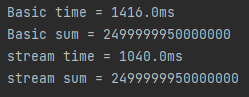
글 다 써놓고 복기 해보니까 단위가 ms도 아니고 10ms단위임.. 뭐냐이거
수정 전 코드는 /1000도 아니고 /100 해놔서 단위 자체가 이상했음
수정해서 ms 단위로 다시 바꿧음다
0.4초 나이네 후..... 그러게 코드를 왜 잘못 써가지고
stream의 경우 limit()를 추가해서 끊을 수 있다. 이게 꽤 강점임
int real = list.stream()
.mapToInt(i -> Integer.valueOf(i))
.limit(10)
.sum();
System.out.println("real = " + real);딱 10개만 뜯어서 sum을 해줬다. 만약 list가 더럽게 많거나, DB에서 뽑아 올리는데 미친듯이 많으면, filter를 써서 앞에 limit를 붙이던가 해서 제한을 넣어줄 수 도 있다.
생성
Collection에선 이미 stream()이 정의되어 있어서 뭐든 stream으로 바꿀 수 있다.
상기 배열을 list로 바꿔서 만들면 대충 이렇다.
List<String> list = new ArrayList<>();
for (int i = 0; i < 100000000; i++) {
list.add(i+"");
}
long sum = list.stream()
.mapToLong(i -> Long.valueOf(i))
.filter(e -> e % 2 ==0)
.sum();이전 코드는 배열에서 stream을 만들기 위해 Arrays 클래스를 사용했는데, 얘는 걍 .stream() 메서드만 붙여주면 stream을 반환한다. 그리고 체인으로 mapToLong().filter().sum()을 박아둔거
그냥 생성할 수 도 있는데
Stream<String> example = Stream.of("a", "b", "c"); (example에 "a", "b", "c")
IntStream stream = IntStream.range(0, 100000000); (상기 for문이랑 똑같은 숫자)일케 된다.
long sum = list.stream() // 데이터 소스 부분
.mapToLong(i -> Long.valueOf(i)) // 중간 연산
.filter(e -> e % 2 ==0) // 중간 연산
.sum(); // 최종 연산이런 식으로 쪼개진다.
중간 연산
distinct()
중복을 없애준다.
이거 은근 개꿀이겠다.
계속 우려먹고 있는 sum을 보자
long answer = 0;
List<String> list = new ArrayList<>();
for (int i = 0; i < 100; i++) {
list.add(i+"");
list.add(i+"");
}
long[] a = new long[list.size()];
for (int i = 0; i < list.size(); i++) {
a[i] = Long.valueOf(list.get(i));
}
for (long i : a) {
if(i % 2 == 0){
answer+= i;
}
}
System.out.println("Basic sum = " + answer);
long sum = list.stream()
.mapToLong(i -> Long.valueOf(i))
.distinct()
.filter(e -> e % 2 ==0)
.sum();
System.out.println("stream sum = " + sum);for문에 list.add(i+"")를 한번 더 넣어줬다. 이러면 숫자가 0,0,1,1,2,2,3,3,4,4 이런식으로 들어간다.
즉 중복이 생김
basic은 이 중복을 없애려면 Set으로 없애던가 for문 안에서 중복을 없애줘야 하는데, stream은 이 distinct()면 된다.
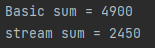
for문은 그대로 sum했고 stream은 distinct()를 써줬더니, 정확히 절반이 됐다.
filter()
말 그대로 필터를 해준다. 상기 sum에 보면 들어오는 요소를 e로 본다면 (e % 2 ==0)을 true로 반환하는 놈들만 들어오게 해놨다.
long sum = list.stream()
.mapToLong(i -> Long.valueOf(i))
.distinct()
.filter(e -> e % 2 ==0)
.sum();짝수만 해둘거임 이라고 한거다. 만약 최종 연산에서 sum()이 아니라 toArray()로 반환하면 Long[] 을 얻는데 짝수값만 필터링 돼서 먹을 수 도 있는거다.
String[] hi = {"안녕하세요", "안감사해요", "잘있어요", "안다시 만나요"};
String[] an = Arrays.stream(hi)
.filter(e -> e.startsWith("안"))
.toArray(String[]::new);
System.out.println(Arrays.toString(an));이런 식으로 첫 글자 필터도 된다.
String[] hi = {"안녕하세요", "안감사해요우", "잘있어요", "안다시 만나요우"};
String[] an = Arrays.stream(hi).filter(e -> e.endsWith("우"))
.toArray(String[]::new);
System.out.println(Arrays.toString(an)); //안감사해요우, 안다시만나요우끝 글자도 되고
String[] hi = {"안녕곽하세요", "안감사해요우", "잘있곽어요", "안다시 만나요우"};
String[] an = Arrays.stream(hi).filter(e -> e.contains("곽"))
.toArray(String[]::new);
System.out.println(Arrays.toString(an)); //[안녕곽하세요, 잘있곽어요]그냥 contains를 써도 되고
String[] hi = {"안녕곽하세요", "안감사해요우", "잘있곽어요", "안다시 만나요우"};
String[] an = Arrays.stream(hi).filter(e -> !e.contains("곽"))
.toArray(String[]::new);
System.out.println(Arrays.toString(an)); //[안감사해요우, 안다시 만나요우]눈치 챘는가? e 를 보고 boolean값을 내뱉으면 채기해주고 아니면 버린다.
map()
HashMap의 걔랑은 다르다.
얘는 각 요소별로 뭔갈 해준다.
String[] hi = {"안녕곽하세요", "안감사해요우", "잘있곽어요", "안다시 만나요우"};
String[] an = Arrays.stream(hi)
.map(s -> s + "끝!")
.toArray(String[]::new);
System.out.println(Arrays.toString(an)); //[안녕곽하세요끝!, 안감사해요우끝!, 잘있곽어요끝!, 안다시 만나요우끝!]각 요소에 끝! 이라는 String이 붙었다. 이런 식으로 개별 요소에 공통적으로 뭔갈 처리해주면 map()임
요소의 타입을 변환한다고나 하는 작업이 필요할 때도 있다.
그럴 땐 mapToInt(), mapToLong(), mapToDouble()등이 필요할 수도 있다. 이 경우엔 stream도 각각
IntStream, LongStream, DoubleStream으로 바꿔준다.
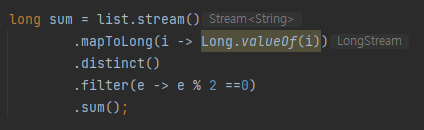
Stream제네릭 String에서 LongStream으로 바뀌어서 체인이 되는걸 확인 할 수 있다.
map()과 비슷하지만 좀 다른놈으로 flatMap()이 있다. 이놈은 배열의 형태인 녀석을 가져왔을 때, 단일 원소로 바꿔준다.
뭔 개소리냐면
String[][] hi = {{"후","너희들은"},{"이런거","하지마라"},{"후..","후아아아"}};
String[] an = Arrays.stream(hi)
.flatMap(s -> Arrays.stream(s))
.map(s -> s+"끝")
.toArray(String[]::new);
System.out.println(Arrays.toString(an));flatMap가 2차원 배열인 hi를 뜯어서 안애 있는 배열을 또 Arrays.stream()으로 만들었다.
map으로 이짓꺼리 하기 쉽지 않다.
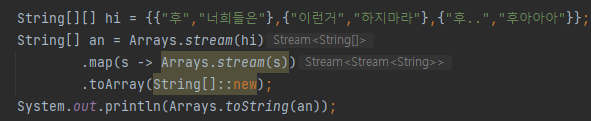
map으로도 내부 2차배열을 stream화 할 수 있지만 그 뒤 처리가 곤란해진다.
Stream Stream String의 환상의 콜라보가 보이나?
flatMap은 저 안에 있는 배열을 뜯어서 합쳐준다. (즉 가장 작은 단위로 합쳐준다)

제네릭으로 String[] 를 받던 녀석이 String으로 바뀜. 저걸 또 마지막에 toArray를 해서 배열로 받아진거다.
sorted()
배열이나 컬렉션을 기본적으로 오름차순으로 정렬시켜준다.
내림차순으로 하고 싶다면 괄호 안에 옵션을 박으면 된다.
list.stream() //오름차순
.sorted();
list2.stream() // 내림차순
.sorted(Comparator.reverseOrder());일반적인 배열은 걍 Arrays.sort()면 다 되니까 굳이 막 스트림 바꾸고 이러지 말자
주로 컬렉션을 배열할때 쓰자고
sum을 만들었던 예시를 보면
List<String> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i+"");
list.add(i+"");
}0 ~ 10까지 중복으로 들어간다 0,0,1,1 이런식
list = list.stream()
.distinct()
.sorted() //Comparator.reverseOrder() 넣으면 9 8 7 6 5 4 3 2 1 0
.toList();
for (String l : list) {
System.out.print(l + " "); // 0 1 2 3 4 5 6 7 8 9
}요래 해주면 중복제거 해주고 오름차순으로 정리된다.
peek()
연산 결과 확인이다. 중간연산자라 여러번 가능한데 쓸 일이 있으라나 모르겠다.
아마 중간중간 디버깅을 위한 작업인듯.
list = list.stream()
.peek(n -> System.out.print(n + " ")) // 0 0 1 1 2 2 3 3
.distinct()
.sorted(Comparator.reverseOrder())
.peek(n -> System.out.println())
.peek(n -> System.out.print(n + " ")) //3 2 1 0
.toList();최종 연산
forEach
최종연산이라 파이프라인 마지막에서 요소를 하나씩 어떻게 할건지 정하는거임
void라 리턴값이 없다.
list.stream()
.distinct()
.sorted(Comparator.reverseOrder())
.forEach(s -> System.out.print(s)); // 3 2 1 0쓸 일이 있을지 모르겠다.
match()
boolean을 뱉는 최종 연산임
- allMatch() : 모든 요소들이 매개값으로 주어진 predicate의 조건을 만족하는지 조사
- anyMatch() : 최소한 한개의 요소가 매개값으로 주어진 Predicate의 조건을 만족하는지 조사
- noneMatch() : 모든 요소들의 매개값으로 주어진 Predicate의 조건을 만족하지 않는지 조사
List<String> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i+"");
}
boolean real = list.stream()
.mapToInt(e -> Integer.valueOf(e))
.noneMatch(e -> e == 100); //true
// .anyMatch(e -> e % 2 ==0); //true
// .allMatch(e -> e %2 ==0); //false
System.out.println("real = " + real);주석처리한 부분에 주의해서 보자.
noneMatch는 요소가 100인게 없지? 라고 물어본거고
anyMatch는 짝수가 있긴 하냐? 라고 물어본거고
allMatch는 전부 다 짝수지? 라고 물어본거다.
sum(), count(), average(), max(), min()
말 그대로임
- sum() : 합계
- count() : 갯수
- average() : 평균
- max() : 최대값
- min() : 최소값
reduce()
자바스크립트에서도 꽤 잘 썼다. 자바에서는 자유도가 좀 떨어지는 듯.
총 3개의 매개변수를 가질 수 있다.
- Accumulator : 각 요소를 계산산 중간 결과를 생성하기 위해 사용
- Identity : 계산을 수행하기 위한 초기값
- Combiner : 병렬 스트림에서 나누어 계산된 결과를 하나로 합치기 위한 로직
저 sum, count 는 다 내부적으론 이 reduce()를 쓴다.
count를 reduce로 구현해보면 이렇다
long real = list.stream()
.mapToInt(e -> Integer.valueOf(e))
.reduce(0,(x, y) -> x+=1); x의 초기값은 0이고 y는 list에 들어 있는 요소라고 생각하면 된다.
sum은
long real = list.stream()
.mapToInt(e -> Integer.valueOf(e))
.reduce(0,(x, y) -> x+y);x값에 y를 계속 넣어주면 된다.
Max나 Min은
int real = list.stream()
.mapToInt(e -> Integer.valueOf(e))
.reduce((x, y) -> x > y ? y : x )
.getAsInt();이렇게 처리하면 된다. 상기 코드 사용시 reduce는 OptionalInt를 뱉는다. 그렇기 때문에 마지막 최종 연산에 getAsInt()를 추가
저러면 최소값이 튀어나오고
int real = list.stream()
.mapToInt(e -> Integer.valueOf(e))
.reduce((x, y) -> x < y ? y : x )
.getAsInt();reduce에서 꺽쇄를 반대로 돌려버리면 최대값이 튀어나온다.
뭔 코든지 모르겠으면 삼항연산자 공부 ㄱ
collect()
최종계산에서 다른 형태의 컬렉터로 바꾸고 싶으면 쓰면 된다.
collect()는 3개의 인자를 받는다.
- Supplier supplier : 뭘로 만들건데 (아랫 놈으로 누적했을 때 뭐가 만들어지니?)
- BiConsumer accmulator : 어떻게 만들건데? (이 방법을 누적해야해)
- BiConsumer combiner : 병렬 처리시에만 사용
Set<Integer> real = list.stream()
.mapToInt(e -> Integer.valueOf(e))
.collect(HashSet::new, HashSet::add, HashSet::addAll);ArrayList였던 list를 Set으로 바꿔줬다.
collect 순서대로 HashSet 클래스의 new를 불러왔고, add를 불러왔으며 병렬 처리시엔 걍 다 싹다 넣겠다 addAll을 넣음
String real = list.stream()
.collect(Collectors.joining());
System.out.println("real = " + real);이런 식의 문자열 변환도 가능하다. 구분 자를 넣고 싶으면 joining에 옵션을 추가하면 된다. " "를 추가하면 사이사이 띄어쓰기가 들어감.
실은 Set도 저렇게 복잡할 필요는 없고
Set<String> real = list.stream()
.collect(Collectors.toSet());이러면 알아서 Set으로 바뀐다. Collectors에 static으로 몇몇 가지 메서드가 선언되어 있다.
유용하게 쓰자.
5. Optional
Optional은 null 값으로 발생하는 에러를 방지하려고 나온 놈이다.
얜 Null이 들어와도 상관이 없다.
Optional은 모든 객체를 담을 수 있는 래퍼 클래스임.
- Optional.of() : Optional에 뭔가 넣을 때 쓰는 메서드. 리스트든 스트링이든 먹는다. 이땐 제네릭에 주의해야하는데
Optional <String>은 문자열이 누가봐도 들어갈 것 같지만 list의 경우
Optional <List<String>> 이런식으로 선언해 줘야 한다. - ofNullable() : of를 쓰는데, null 가능성이 있으면 이걸 박는다.
- Optional.empty() : 초기화
- Optional.get() : 값 빼내기 (제네릭 확인하셈)
- Optional.orElse() : 값을 빼내긴 하는데, null 가능성이 있으면 얘를 쓰면 된다.
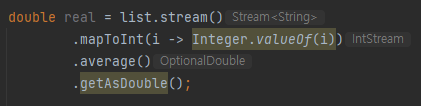
스트림으로 average를 만들 때도 Optional이 사용된다. OptionalDouble로 만들어졌다가 getAsDouble로 double타입으로 변경해줬음. 만약 null일 경우를 생각 한다면
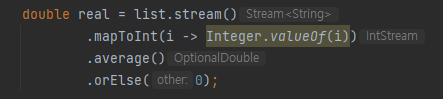
이렇게 하면 된다. 똑같이 double로 빠져나옴.
Optional같은 경우엔 null값이 나올 수 도 있는 상황에서 잘 쓰면 된다.
public List<Member> findAll() {
return new ArrayList<>(store.values());
}
public Optional<Member> findByLoginId(String loginId) {
return findAll().stream().filter(m -> m.getLoginId().equals(loginId))
.findFirst();
}MemberRepository라는 클래스 안에 LoginId를 검색하는 메서드를 만들었다.
리턴값이 Optional임
상기 코드는 메모리상에 Member를 저장해놨기 때문에 메서드가 저 모양이긴 하지만
어쨋든 뒤져봤을 때 없으면 null 튀어나오면서 서버에 에러메시지 날라가고 터질거를 저 Optional로 방지했다고 볼 수 있다.
