[논문리뷰]Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes(ACL 2023)
논문 리뷰
Abstract
1. Introduction
2. Related work
3. Distilling step-by-step
3.1. Extracting rationales from LLMs
3.2. Training smaller models with rationales
4. Experiments
4.1. Reducing training data
4.2. Reducing model size
4.3. Outperforming LLMs using minimum model size and least training data
4.4. Further ablation studies
5. Discussion
Self Q&A
Opinion
Abstract
LLM은 memory inefficient(메모리가 많이 필요), compute-intensive(연산량이 많이 필요) 문제로 인해 배포하기가 어렵다.
이에 따라 연구자들은 human labels로 fine-tuning하거나 (human labels이 없는 경우) LLM-generated labels을 사용하여 distilling하는 방식(LLM을 Teacher로, smaller model을 student로 하여 학습)으로 smaller task-specific 모델을 훈련하여 사용하고 있다.
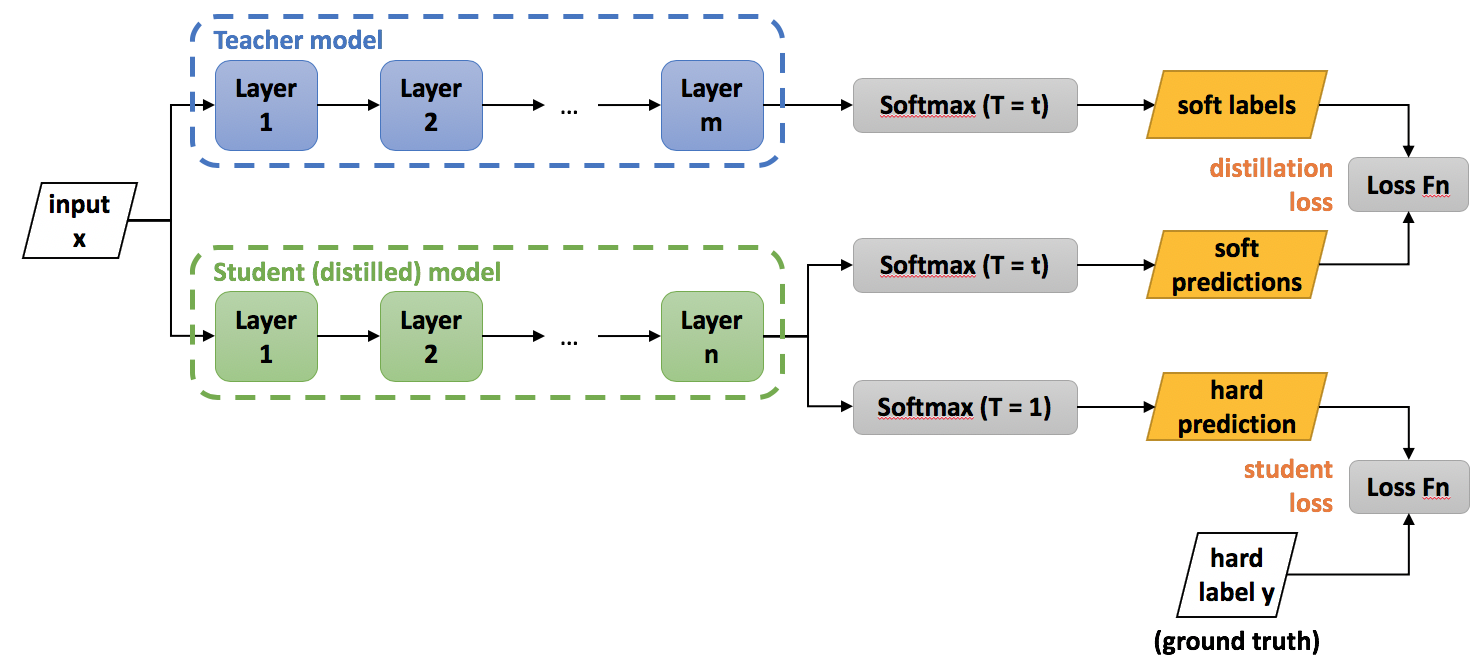
- (Knowledge Distillation 설명 그림)
- https://intellabs.github.io/distiller/knowledge_distillation.html
그러나 fine-tuning과 distillation은 LLM과 비슷한 성능을 달성하기 위해 많은 양의 훈련 데이터가 필요하다.
논문에서는 Distilling step-by-step이라는 새로운 메커니즘을 도입하여,
- (a) 결과적으로 LLM의 성능을 뛰어넘을 수 있는 smaller 모델을 훈련하였고,
- (b) fine-tuning이나 distillation에 필요한 훈련 데이터의 양을 줄일 수 있었다.
이 방법은 multi-task framework 내에서 small 모델을 훈련하기 위한 additional supervision으로 LLM rationales을 추출(extract)했다. 4개의 NLP 벤치마크에서 3가지 findings을 제시한다:
- 1) fine-tuning과 distillation에 비해 훨씬 적은 수의 labeled/unlabeled 훈련 예제로 더 높은 성능을 달성
- 2) few-shot prompted LLM에 비해 훨씬 작은 크기의 모델로 더 높은 성능을 달성 (강조하지 않은 이유는, 이전 stard fine-tuning으로도 달성했던 성과이기 때문)
- 3) 모델 크기와 데이터 양을 모두 줄였음에도 LLM의 성능을 능가
벤치마크 데이터를 80%만 사용한 fine-tuned 770M T5 모델로 few-shot prompted 540B PaLM 모델보다 높은 성능을 달성했는데, 이는 동일한 T5 모델에 대해 데이터 세트를 100%사용한 standard fine-tuning으로도 달성하지 못했던 성능이다(Figure 4).
1. Introduction
(메모리 문제)LLM의 인상적인 few-shot ability에도 불구하고, 모델 크기 문제로 인해 실제 애플리케이션에서 배포하기가 어렵다.
175B LLM을 서비스하기 위해 최소 350GB의 GPU 메모리가 필요하고, PaLM과 같은 최신 LLM은 500B 이상의 파라미터로 구성되어 있어 훨씬 더 많은 메모리와 연산량을 필요로 한다.
(연산량 문제)컴퓨팅 요구 사항은 대부분의 팀, 특히 짧은 latency 시간이 요구되는 애플리케이션이 감당할 수 있는 수준을 훨씬 넘어선다.
LLM의 배포상의 문제를 해결하기 위해, 실무자들은 smaller task-specialized 모델을 배포하는 방법을 선택해왔다.
smaller 모델은 일반적으로 'fine-tuning' 또는 'distillation' 두 가지 패러다임 중 하나를 사용하여 학습되어 왔다.
이 2가지 패러다임은 모델 크기를 줄일 수는 있었지만, LLM과 비슷한 성능을 달성하기 위해서는 많은 비용이 필요하다.
fine-tuning의 경우 human labels이 필요하고, distillation의 경우 대량의 unlabeled 데이터를 확보하는데 어려움이 있을 수 있다.
본 연구에서는 더 적은 훈련 데이터로 더 작은 모델을 훈련하기 위한 간단한 메커니즘인 Distilling step-by-step을 제시한다.
이는 LLM을 더 작은 모델 크기로 fine-tuning하고 distillation 하는데 필요한 학습 데이터의 양을 줄여준다.
이 메커니즘의 핵심은 LLM을 보는 관점을 'source of noisy labels'에서 'reasoning이 가능한 agents'로 전환하는 것이다.
예를 들어 "Jesse’s room is 11 feet long and 15 feet wide. If she already has 16 square feet of carpet. How much more carpet does she need to cover the whole floor?"라는 질문에 대해 LLM은 chain-of-thought(CoT) 기법을 통해 "Area = length × width.", "Jesse’s room has 11 × 15 square feet"라는 intermediate rationales을 제시할 수 있는데, 이는 final answer에 대한 입력인 "(11 × 15) − 16"에 더 잘 접근할 수 있도록 유도 한다.
이러한 intermediate rationales에는 "Area = length × width"와 같은 relevant task knowledge도 포함될 수 있는데, 이를 small task-specific 모델을 학습시키는 방법을 통해 얻기 위해서는 많은 데이터가 필요했을 것이다.
논문에서는 extracted rationales(CoT를 통해 유도된 intermediate rationales)을 small 모델을 훈련하기 위한 additional(추가적인), richer(풍부한) 정보로 활용했다.
즉, LLM의 CoT를 통해 출력된 label prediction과 rationale prediction(extracted intermediate rationales)을 모두 포함하는 multi-task training setup을 통해, small 모델에 Knowledge Distillation을 진행했다(extracted rationales을 훈련데이터로 활용했다는 의미. 기존의 Knowledge Distillation은 정답만 가져왔다면, CoT의 intermediate rationales을 함께 학습시키는 multi-task training을 적용하여 relevant task knowledge과 같은 능력도 키울 수 있도록 유도).

- 논문의 성과를 강조하기 위한 그림인 것 같으나, 오해를 불러올 수 있을 여지가 있어보인다(어떤 dataset인지 명시하지않았으며, 정확한 수치가 없다. 뿐만 아니라 기존의 task-specific model과 비교했을 때 대부분의 벤치마크에서 간격이 그림만큼 극적이지는 않음.).
- 미리 얘기하자면, Distilling step-by-step과 standard task-specific model의 성능은 대부분 비슷하며 LLM의 성능을 대부분 크게 앞서나, 그림의 경우 전체적으로 standard task-specific model과 LLM의 성능이 비슷하고 Distilling step-by-step만 앞서는 것처럼 보임(오해의 여지)
- required training data는 실제로 standard task-specific model에 비해 차이가 명확하나, model size, performance는 큰 차이 없음(오히려 standard task-specific model도 LLM과는 큰 차이가 존재)
Distilling step-by-step를 통해 LLM에 비해 500배 적은 모델 파라미터와 훨씬 적은 수의 훈련 예제로도 LLM보다 성능이 뛰어난 task-specific smaller 모델을 학습할 수 있다(Figure 1 -Task-specific models과 비교했을 때, 파라미터 크기의 차이는 크지않음-).
연구 결과, 4개의 NLP 벤치마크에서 세 가지 유망한 경험적(empirical) 결론이 도출되었다.
- 1) fine-tuning과 distillation에 비해 평균 50% 이상 적은 훈련 예제(최대 85% 이상 감소)로 더 높은 성능을 달성했다.
- 2) 훨씬 작은 모델 크기(최대 2000배 더 작음)로 LLM보다 높은 성능을 달성했으며, 이를 통해 모델 배포에 필요한 컴퓨팅 비용을 대폭 절감할 수 있다.
- 3) model size와 amount of data를 동시에 줄여도 LLM을 능가한다.
(Fine-tuning) 770M T5 모델을 사용해 540B 파라미터 LLM의 성능을 능가했으며, 이 smaller 모델은 기존의 fine-tuning 방법을 사용할 경우 필요했던 labeled dataset의 80%만 사용했다).
(Distillation) unlabeled data만 사용한 경우에도 small 모델은 여전히 LLM과 동등하거나 더 나은 성능을 발휘한다(11B T5 모델만으로 540B PaLM의 성능을 능가).
smaller 모델이 LLM보다 성능이 떨어질 때, Distilling step-by-step 방법을 사용하는 것이 standard distillation 방식에 비해 additional unlabeled data를 더 효율적으로(더 적은 데이터셋) 활용하여 LLM의 성능에 가까워질 수 있음을 보여준다.
2. Related work
본 연구는, LLM의 reasoning capabilities(CoT)를 활용하여 LLM의 task-specific knowledge을 smaller-specialist 모델로 distills하는 것이다.
연구자들은 기존의 knowledge distillation, human-generated rationales과 LLM-generated rationales을 학습하는 방법을 참고했다(결과적으로 human-label과 Chain-of-thought를 모두 사용).
Knowledge distillation from large models
일반적으로 Knowledge distillation을 적용하기 위해 필요한 unlabelled data를 만들기 위해 augmentation 방법을 사용하지만, 연구자들은 label(정답)과 teacher’s rationales(large LLM의 CoT)를 distilling하는 방법을 통해, unlabeled data의 필요성을 줄이는 대안적인 접근 방식을 사용했다(더 적은 unlabeled data을 사용하지만, intermediate rationales를 함께 학습시켜 더 높은 성능을 달성).
Learning with human rationales
Human-generated rationales은 전반적인 모델 성능을 개선하는 데 사용될 수 있고, 유사한 추론을 생성하여 모델을 interpretable(해석가능성)하게 만드는 standard label로 사용할 수 있지만, 안타깝게도 human rationales은 비용이 많이 든다.
Learning with LLM generated rationales
오늘날의 LLM은 high-quality reasoning steps을 생성하여 예측 결과를 설명할 수 있다(CoT). 그러나 안타깝게도 LLM이 어떻게 개선되든 간에, 그 크기가 커서 대부분의 test-time 애플리케이션에서 그 유용성이 제한된다.
따라서, 본 연구에서는 생성된 rationales을 supervision으로 활용하여 smaller task-specific 모델, 즉 대규모 computation이나 memory 비용 없이 배포할 수 있는 모델을 훈련시켰다.
3. Distilling step-by-step
본 연구에서는 LLM의 예측결과에 대한 reason 능력(final answer를 출력하는 과정에 대한 추론. 즉, CoT)을 활용하여 data-efficient하게 smaller 모델을 훈련하는 새로운 패러다임으로 Distilling step-by-step을 제안한다.
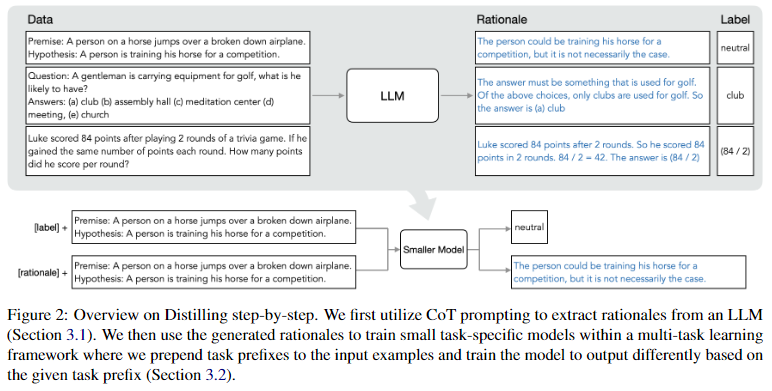
이 패러다임은 2개의 simple steps로 이루어져 있다:
- 1) LLM과 unlabeled dataset가 주어지면, output(predicted) labels과 함께 labels을 정당화(justify)하기 위한 rationales을 같이 생성하도록 LLM에 요청한다(CoT).
Rationales는 모델의 predicted label 을 뒷받침하는 natural language explanations이다(Figure 2). - 2) task labels과 rationales을 활용하여 더 작은 다운스트림 모델을 학습시킨다.
rationales은 input이 specific output label에 매핑되는 이유에 대한 richer, detailed information를 제공하며, 종종 original inputs만으로는 유추하기 어려운 relevant task knowledge을 포함하기도 한다.
3.1. Extracting rationales from LLMs
최근 연구에 따른 LLM의 흥미로운 특성 중 하나는 predictions을 뒷받침하는 rationales을 생성하는 능력이다(Chain-of-thought). 해당 연구(CoT)에서는 주로 LLM의 reasoning 능력을 이용해 성능을 높이는데 초점을 맞추었지만, 본 논문에서는 smaller 다운스트림 모델(task-specific)을 학습하는데 이를 활용하고자 한다(LLM의 메모리, 연산량 문제 때문에 LLM을 그대로 사용할 수 없음).
즉, Chain-of-Thought prompting를 활용하여 LLM에서 rationales을 출력하고 extract하여 이를 훈련에 사용했다.

Figure 3에서와 같이, unlabeled dataset 가 주어지면 task를 해결하기 위한 과정을 명확하게 설명하는 프롬프트 template 를 작성한다(는 전체 프롬프트를 의미).
각 프롬프트는 triplet 으로 구성되며, 여기서 는 example input이고, 는 corresponding label(정답)이며, 는 가 왜 로 분류될 수 있는지를 설명하는 user-provided rationale이다.
()
먼저 각 input 를 에 추가한 뒤, 이를 (CoT exampler와 함께)input으로 사용하여 LLM이 각 에 대한 rationales와 labels을 생성하도록 유도한다.
에서 볼 수 있는 데모(CoT exampler)를 통해 LLM은 triplet를 mimic(모방)하여, 에 대한 rationale 과 output 를 생성한다.
3.2. Training smaller models with rationales
먼저 task-specific 모델을 학습하기 위한 프레임워크에 대해 설명하자면, 학습 과정에 rationales을 포함한다.
연구에서는 dataset을 로 나타내며, 여기에서 는 input을 의미하고 는 output label을 의미한다.
프레임워크는 모든 modality의 inputs과 outputs을 지원하지만, 실험에서는 와 를 자연어로 제한했다.
이 text-to-text 프레임워크는 classification, natural language inference, question answering 등 다양한 NLP 작업을 포괄한다.
Standard finetuning and task distillation
task-specific 모델을 훈련하는 가장 일반적인 방법은 supervised 데이터로 pretrained 모델을 fine-tuning하는 것이다.
human-annotated labels이 없는 경우, LLM teachers를 사용하여 생성한 pseudo noisy training labels인 를 ()대신 사용해 task-specific distillation을 수행할 수 있다.
두 시나리오 모두에서 smaller 모델 가 label prediction loss을 최소화하도록 학습된다:
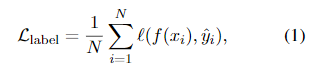
- 여기서 는 predicted tokens과 target(정답) tokens 사이의 cross-entropy loss이다.
- Eq. 1의 은, standard fine-tuning의 경우 human-annotated labels 이고, distillation의 경우 LLM-predicted labels 이다.
- (아직 이 단계에서는 extracted rationales 은 포함되지 않음)
Multi-task learning with rationales
와 를 보다 명시적으로 연결하기 위해, extracted rationales 를 additional supervision으로 사용했다(main idea).
다운스트림 모델의 훈련 과정에 rationales를 통합하는 직관적인 접근 방식은 additional input으로 를 공급하는 것이다.
즉, 는 text와 rationale 를 모두 inputs으로 사용하여 훈련하는 방법이다:
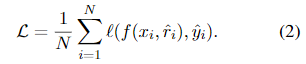
안타깝게도 이 설계에서는 (smaller task-specific model)가 예측을 진행하기 전에 LLM이 먼저 rationale를 생성해야 한다.
즉, 가 input에 포함될 경우, 의 모든 predict 상황에서 LLM이 필요하기 때문에, 배포과정에 LLM을 사용할 수 없는 환경에서는 여전히 적용할 수 없다.
본 논문에서는 rationales을 additional inputs로 사용하는 대신, rationales을 사용한 학습을 multi-task problem으로 구성했다.
즉, text inputs이 주어졌을 때 task labels(예측 결과) 뿐만 아니라 corresponding rationales를 둘다 생성할 수 있도록 모델을 훈련하는 방법이다:
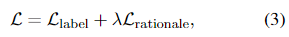
- 여기서 은 Eq. 1의 label prediction loss이고, 은 rationale generation loss이다:
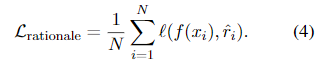
rationale generation loss을 통해 모델은 예측(Label 예측)을 위한 intermediate reasoning steps를 생성하는 방법을 학습할 수 있으며, 결과적으로 resultant label(final answer)을 더 잘 예측하도록 유도할 수 있다.
이 것(Ep. 3)이 논문이 제안하는 Distilling step-by-step이다. Eq. 2와 비교했을 때, test time에서 rationale 가 필요하지 않으므로, 배포과정에 LLM이 필요하지 않다.
input examples에 "task prefixes(label인지 rationale인지 알려주는 것)" ([label], [rationale])를 추가하여, [label]이 제공되면 를 출력하고 [rationale]가 있으면 를 생성하도록 smaller 모델을 훈련했다.
4. Experiments
Sec. 4.1 에서는 standard finetuning, task distillation 접근 방식(기존의 접근 방식들)과 비교했을 때, Distilling step-by-step은 훨씬 적은 수의 training examples로 더 높은 성능을 달성하여, small task-specific 모델을 학습시키기 위한 data efficiency을 크게 개선했음을 보여준다.
Sec. 4.2 에서는 Distilling step-by-step를 적용한 smaller 모델로, LLM의 성능을 능가하여 LLM에 비해 배포 비용을 대폭 낮췄음을 보여준다.
Sec. 4.3 에서는 Distilling step-by-step이 LLM을 성능을 넘어서기 위해 필요한 minimum resources(number of training examples, model size) 조사했다. Distilling step-by-step은 더 적은 데이터와 작은 모델을 사용해 LLM보다 높은 성능이 달성해, data-efficiency와 deployability-efficiency을 동시에 향상시켰음을 보여준다.
Sec. 4.4 에서는 Distilling step-by-step framework의 다양한 구성 요소(components)와 design choices의 영향력을 이해하기 위해 ablation studies를 진행했다.
Setup
- 실험에서는 LLM으로 540B PaLM 모델을 사용했다.
- task-specific 다운스트림 모델의 경우, 공개적으로 사용 가능한 소스(HuggingFace)에서 얻은 pretrained weights로 모델을 initialize할 수 있는 T5 모델을 사용했다.
- CoT 프롬프트의 경우, 가능한 경우 Wei et al.(2022)을 따르고, 새로운 데이터 세트에 대해서는 자체적으로 examples를 작성했다.
Datasets
3가지 NLP task에서 4개의 인기 벤치마크 데이터 세트를 대상으로 실험을 진행했다.
- natural language inference: e-SNLI, ANLI
- commonsense question answering: CQA
- arithmetic math word problems: SVAMP
4.1. Reducing training data
Distilling step-by-step과, task-specific 모델을 학습시키는 가장 일반적인 두 가지 방법을 비교했다:
- 1) STANDARD FINETUNING: human-labeled examples를 사용할 수 있는 경우
- 2) STANDARD TASK DISTILLATION: unlabeled examples만 사용할 수 있는 경우(LLM을 teacher로 사용).
task-specific 모델을 220M T5-Base 모델로 고정하고, 사용 가능한 training examples의 수를 다양하게 설정한 다양한 방법으로 달성한 task별 성능을 비교했다.
Distilling step-by-step outperforms standard finetuning with much less labeled examples(Distilling step-by-step VS STANDARD FINETUNING)
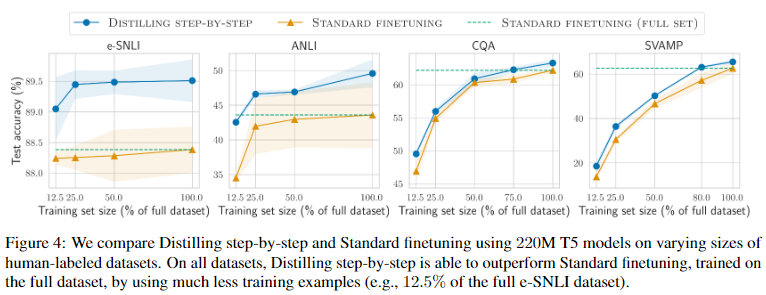
- Distilling step-by-step에 사용된 labeled examples 수에 따라 standard finetuning보다 일관되게 더 나은 성능을 달성했다.
- Distilling step-by-step는 훨씬 적은 수의 labeled examples로도 standard finetuning과 동일한 성능을 달성할 수 있음을 알 수 있다.
- 특히, e-SNLI dataset의 12.5%만 사용한 Distilling step-by-step은 dataset을 100% 사용하여 훈련된 standard finetuning에 근접한 성능을 달성했다.
Distilling step-by-step outperforms standard distillation with much less unlabeled examples(Distilling step-by-step VS STANDARD TASK DISTILLATION)
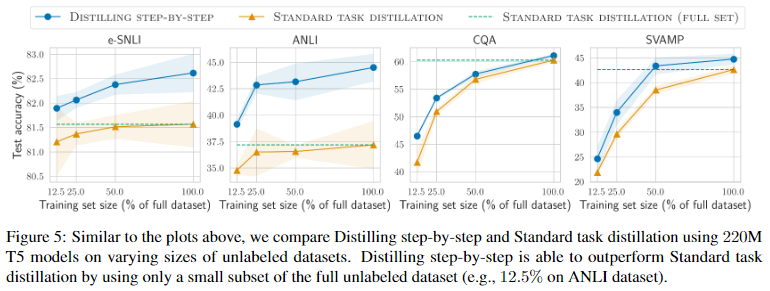
- 전반적으로 fine-tuning setup과 유사한 추세를 가진다.
4.2. Reducing model size
training set 크기를 고정(100% 사용)하고, Distilling step-by-step과 standard knowledge distillation으로 훈련된 다양한 크기의 T5 모델을 비교했다.
220M T5-Base, 770M T5-Large, 11B T5-XXL 3가지 크기의 T5 모델을 이용해 비교했으며, LLM의 경우 (1)FEW-SHOT CoT와 (2)PINTO TUN-ING의 두 가지를 추가로 비교했다.
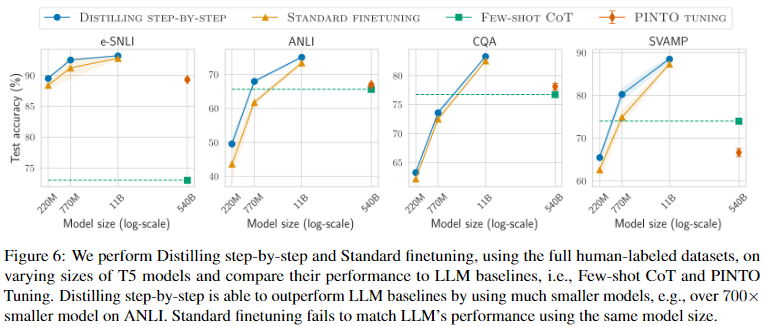
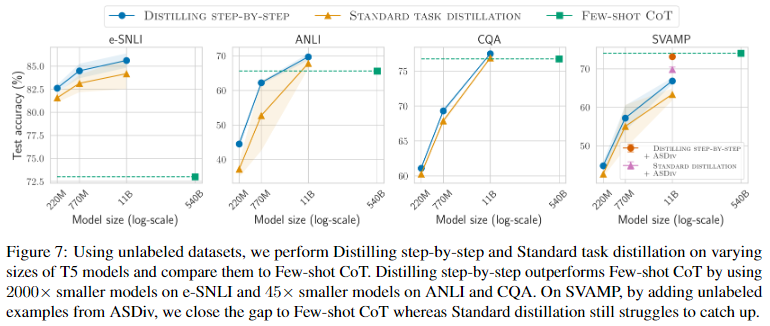
Distilling step-by-step improves over standard baselines across varying model sizes used
Figure 6와 Figure 7를 통해, Distilling step-by-step이 모든 크기의 T5 모델에서 standard finetuning, standard distillation보다 일관되게 개선된 결과를 나타내는 것을 확인할 수 있다.
Distilling step-by-step outperforms LLMs by using much smaller task-specific models
Figure 6는 human-labeled datasets를 사용할 수 있는 경우에 대한 결과이다.
Distilling step-by-step은 훨씬 더 작은 T5 모델을 사용한 4개의 datasets에서 Few-shot CoT, PINTO 튜닝보다 더 높은 성능을 달성했다(그러나 이는 standard finetuning도 달성했던 내용).
Figure 7는 unlabeled examples만 활용한 경우에 대한 결과이다.
Distilling step-by-step이 4개 중 3대의 datasets에서 teacher LLM보다 높은 성능을 달성했다(그러나 이는 standard distilling도 달성했던 내용).
(standard fine-tuning, standard distillation과 비교했을 때, training dataset의 크기에 따른 차이에 비해, 모델 크기에 따른 성능차이는 크지않음)
distilling 모델의 성능이 저조한 SVAMP에서는, datasets의 data points 수가 상대적으로 적기 때문에(800개) 성능 격차가 발생한다는 가설을 세웠다. 이에 대한 해결 방안으로, additional unlabeled examples로 데이터 세트를 augment할 것을 제안한다(다음 내용).
Unlabeled data augmentation further improves Distilling step-by-step
AS-Div dataset의 unlabeled examples로 SVAMP training set를 augment 했다.
Figure 7에서는 SVAMP에 대해 ASDiv로 훈련 세트를 증강한 후, Distilling step-by-step와 standard task distillation을 통해 11B T5 모델을 훈련시킨 결과, 성능이 크게 향상되는 것을 확인할 수 있다(Distilling step-by-step은 Few-shot CoT와 비슷한 성능).
4.3. Outperforming LLMs using minimum model size and least training data
여기서는 LLM의 성능을 anchor point로 삼아, Distilling step-by-step과 standardfinetuning/distillation이 LLM의 성능을 능가하기 위해 필요한 training examples 수와 model size를 조사했다.
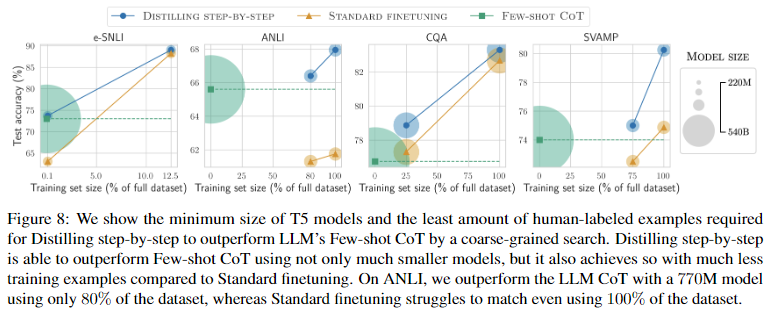

Distilling step-by-step outperforms LLMs with much smaller models by using less data
- cross table처럼 3가지 t-5모델의 크기에 대해, training set의 비율별 성능을 기록한 결과를 보여줬으면 더 직관적이였을 것 같다.
- 즉, Figure 6,7의 training set size별 결과가 나왔으면 더 좋았을 것 같다.
- anchor point를 넘은 지점에 대한 명시적인 언급도 부족했으며(리뷰에서는 생략했지만 논문에는 조금 적혀있긴하다), 그림을 봤을 때도 직관적으로 이해가 잘 가지않았다.
Figure 8(human-labeled setting). 모든 datasets에서 Distilling step-by-step은 일부 training examples만을 사용하여 훈련시킨 T5 모델(PaLM에 비해 훨씬 더 작은 모델)을 사용하여 PaLM의 Few-shot CoT 성능을 뛰어넘었다.
Figure 9(unlabeled setting). Distilling step-by-step 대부분(SVAMP 제외) 더 작은 모델과 더 적은 데이터로 Few-shot CoT를 능가했다.
Standard finetuning and distillation require more data and larger model
Figure 8과 Figure 9를 보면, standard finetuning과 standard distillation가 LLM의 성능에 달성하기 위해 더 많은 데이터 또는 더 큰 모델이 필요하다는 것을 알 수 있다.
4.4. Further ablation studies
지금까지는 Distilling step-by-step이 smaller task-specific 모델을 훈련시키는데 필요한 training data를 줄이는데 얼마나 효과적인지에 중점을 두었다(Section 4.2,4.3).
Section 4.4에서는 Distilling step-by-step 프레임워크에서 다양한 구성 요소(components)의 영향을 이해하기 위한 ablation studies를 진행했다.
구체적으로, (1)rationales를 extract하는 LLM을 바꿨을 때의 영향, (2)LLM rationales를 사용하여 small task-specific을 훈련할 때 multi-task training 접근법이 다른 potential design choices과 어떤 차이점이 있는지에 대해 연구했다.
이 실험에서는 small task-specific을 220M T5 모델로 고정하고, 모든 datasets의 데이터를 100% 활용했다.
Distilling step-by-step works with different sizes of decently trained LLMs
540B PaLM보다 상대적으로 더 작은 20B GPT-NeoX 모델 사용하여 rationales를 추출해 Distilling step-by-step을 훈련시켰다.
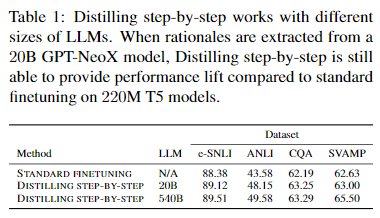
540B PaLM에 비해 20B GPT-NeoX을 사용했을 때 성능이 소폭 감소했지만, 다양한 크기의 LLM에 대해서도 Distilling step-by-step이 standard finetuning에 비해 높은 성능 향상을 이끌어 낼 수 있음을 확인했다.
- 비교군이 적어서 아쉽다.
- CoT 논문에서는 100B이 넘는 모델에 대해서만 final answer을 맞추기 위한 intermediate step을 잘 생성한다고 했는데, 20B에 대해서도 성능차이가 크지 않다는 점은 의문이다.
- fine-tuning(human-labeled)말고 distillation(unlabeled)의 결과에 대해 언급하지 않은 이유일 수도 있을 것 같으나, 별도의 언급이 없었던 점은 아쉬웠다.
Multi-task training is much more effective than single-task rationale and label joint prediction
LLM-rationales를 output supervisions으로 사용하여 task-specific 모델을 훈련하는 방법에는 여러 가지가 있다.
한 가지 간단한 접근 방식은, rationale 와 label 를 single sequence , 로 concatenate하고 이를 small모델 학습 과정의 target output으로 취급하는 것이다(한번에 rationales과 final answer를 예측하는 방식).
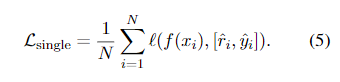
- single-task는 와 ]$ 한번에 생성하므로 loss가 한번에 계산
- multi-task는 로 구성
table 2은 single-task training 접근 방식과, 논문에서 LLM-rationales을 활용하기 위해 제안한 multi-task training 접근 방식을 비교한 결과이다.
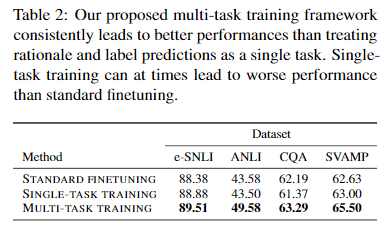
multi-task training이 일관되게 더 나은 성능을 가져올 뿐만 아니라, LLM-rationales를 사용한 single-task training은 일부 standard fine-tuning보다 더 낮은 성능을 가져올 수 있음을 알 수 있다.
- Eq. 2의 결과도 비교해서 보여줬으면 하는 아쉬움이 있다.
5. Discussion
Distilling step-by-step는 small task-specific 모델을 훈련시키는데 필요한 training dataset을 줄여줄 뿐만 아니라, original LLM의 성능을 달성하는데 필요한 모델 크기를 줄여주며, 심지어 작은 크기로도 LLM의 성능을 능가할 수 있음을 보여주었다(마지막은 standard fine-tiuning에서도 이미 달성했던 내용).
Distilling step-by-step은 기존 방식에 비해 resource-efficient하기 때문에, deployment를 위한 새로운 training paradigm이 될 수 있다.
추가적으로 ablation studies를 통해 Distilling step-by-step의 generalizability와 design choices에 관한 내용을 입증했으며, 마지막으로 연구의 limitation과 future directions, ethics statement에 대해 논의하겠다.
Limitations
- 1) few-shot CoT prompting 메커니즘을 사용하기 위해서 사용자가 직접 few example demonstrations(모든 task에 대해 10개 미만)를 만들어야 한다. 이러한 한계는 user-annotated없이도 rationales를 도출할 수 있다는 최근의 연구로 개선될 가능성이 있다(Kojima et al., 2022).
- 2) rationales를 사용하여 task-specific 모델을 훈련하면 약간의 training-time computation over-head가 발생한다. 그러나 test time에는 multi-task design를 통해 rationales를 생성하지 않고 label만 예측할 수 있기 때문에, 자연스럽게 computation over-head를 피할 수 있다(loss로는 과 이 사용되지만, label만 predict하는 자체는 가능하기 때문).
- 3) LLM rationales을 사용한 성공 사례를 관찰한 결과, complex reasoning, planning tasks에서는 LLM이 limited reasoning capability을 보인다는 증거가 있다(Valmeekam 외., 2022).
향후 연구를 통해 rationale quality가 Distilling step-by-step에 미치는 영향을 특성화해야 한다.
Ethics statement
다운스트림의 smaller 모델의 behavior는 larger teacher LLM에서 물려받은 biases의 영향을 받는다는 점에 주목할 필요가 있다. 논문에서는 LLM의 anti-social behavior을 줄이기 위한 연구가 smaller 언어 모델에도 동일하게 적용될 수 있을 것으로 기대하고 있다.
Self Q&A
Opinion
- standard finetuning과 비교해, 파라미터의 크기에 따른 성능차이는 크지않지만, 적은 training examplers로 비슷한 성능 달성한 것을 보면, 특정 문제 해결을 위한 파라미터 크기의 하한선이 있을 수 있겠다는 생각이 들었다. -일정 규모 이상일 때만 풀 수 있는 문제 등-
- Figure 1에서 설명한 것과 같이, 일부 시각화에 오해의 소지가 있으며, 더 다양한 실험을 하지않은 점은 아쉽다.
- SOTA와 비교하지 않은 점이 아쉽다.(결국 LLM을 사용하는 이유는 경량화를 포기하더라도 generalization 성능을 위한 것인데, 경량화하여 task-specific하게 만들거면 SOTA를 쓰면 되는거 아닌가?)
- 심지어 SVAMP는 LLM의 성능에도 미치지 못했으며, ANLI, SVAMP를 제외하면 Distilling step-by-step과 Standard fine-tuning의 차이가 크지않다(Standard fine-tuning과의 성능차이가 크지않으면서도 SOTA의 점수에도 못 미치는데, 단순히 LLM의 점수를 넘었다는게 어떤 이유가 있는지에 대해 더 공부해봐야 할 것 같다.).
