
kops는 단순히 k8s 설치 뿐 만 아니라, 몇가지 기능을 사용할 수 있는데, Official page에서 나온 특징은 아래와 같다.
Features
- Automates the provisioning of Highly Available Kubernetes clusters
- Built on a state-sync model for dry-runs and automatic idempotency
- Ability to generate Terraform
- Supports zero-config managed kubernetes add-ons
- Command line autocompletion
- YAML Manifest Based API Configuration
- Templating and dry-run modes for creating Manifests
- Choose from most popular CNI Networking providers out-of-the-box
- Multi-architecture ready with ARM64 support
- Capability to add containers, as hooks, and files to nodes via a cluster manifest
1.kops 기능 활용해보기
1-1. 노드 스케일아웃
현재구성은 master node 1개, worker node 2개이다. 각 node는 AWS autoscaling group으로 묶여있는데, woker node 중 ap-northeast-2a az에 있는 worker node를 증가 시켜보자.
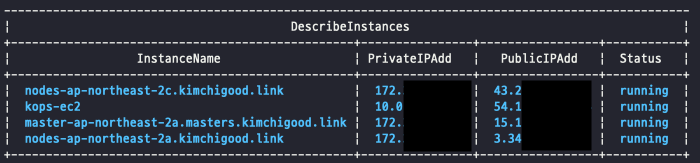
(⎈|kimchigood:default) [root@kops-ec2 ~]# kops get ig
NAME ROLE MACHINETYPE MIN MAX ZONES
master-ap-northeast-2a Master t3.medium 1 1 ap-northeast-2a
nodes-ap-northeast-2a Node t3.medium 1 1 ap-northeast-2a
nodes-ap-northeast-2c Node t3.medium 1 1 ap-northeast-2c
# 노드 추가
kops edit ig nodes-ap-northeast-2a --set spec.minSize=2 --set spec.maxSize=2
# 적용
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster
# 결과
Changes may require instances to restart: kops rolling-update cluster
NAME STATUS NEEDUPDATE READY MIN TARGET MAX NODES
master-ap-northeast-2a Ready 0 1 1 1 1 1
nodes-ap-northeast-2a Ready 0 1 2 2 2 1
nodes-ap-northeast-2c Ready 0 1 1 1 1 1
(⎈|kimchigood:default) [root@kops-ec2 ~]# k get nodes
NAME STATUS ROLES AGE VERSION
i-00872f0bcc3d9ab02 Ready control-plane 4h51m v1.24.10
i-02b277f734d940855 Ready node 4m28s v1.24.10
i-02fe62e0086cce41f Ready node 4h49m v1.24.10
i-0fe15a0adc0d50b75 Ready node 4h50m v1.24.10노드가 잘 증가되었다. EKS, AKS와 같은 managed k8s와 차이가 없는 기능이다.
1-2. ETCD backup & restore
1-2-1. Backup
ETCD란? 간단히 말하면, k8s cluster의 상태와 내용을 저장하는 DB라고 할 수 있다.
그럼 kops로 설치한 etcd data는 어디에 저장되고 있을까?
마스터 노드로 접근해보자.
(⎈|kimchigood:default) [root@kops-ec2 ~]# ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME
# lsblk
ubuntu@i-00872f0bcc3d9ab02:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 24.4M 1 loop /snap/amazon-ssm-agent/6312
loop1 7:1 0 55.6M 1 loop /snap/core18/2697
loop2 7:2 0 63.3M 1 loop /snap/core20/1822
loop3 7:3 0 91.9M 1 loop /snap/lxd/24061
loop4 7:4 0 49.9M 1 loop /snap/snapd/18357
nvme0n1 259:0 0 64G 0 disk
├─nvme0n1p1 259:1 0 63.9G 0 part /
├─nvme0n1p14 259:2 0 4M 0 part
└─nvme0n1p15 259:3 0 106M 0 part /boot/efi
nvme1n1 259:4 0 20G 0 disk /mnt/master-vol-042320fd008bd8366
nvme2n1 259:5 0 20G 0 disk /mnt/master-vol-058a9a120f68812cb맨 아래 /mnt 폴더 밑의 두 개의 경로에 저장되는 것드리 etcd 데이터이다! 두 개인 이유는master와 event로 나눌 수 있는데, HA구성을 위한 것 같다.
바로 이 데이터들이 우리가 1번실습에서 생성한 S3 Bucket에 저장되는 것이다.
공식문서에는 디폴트로 15분 마다 생성된다고 하는데, 실제로 S3에서 보면 처음에는 1시간 단위이다가 15분으로 변하는 듯하다.
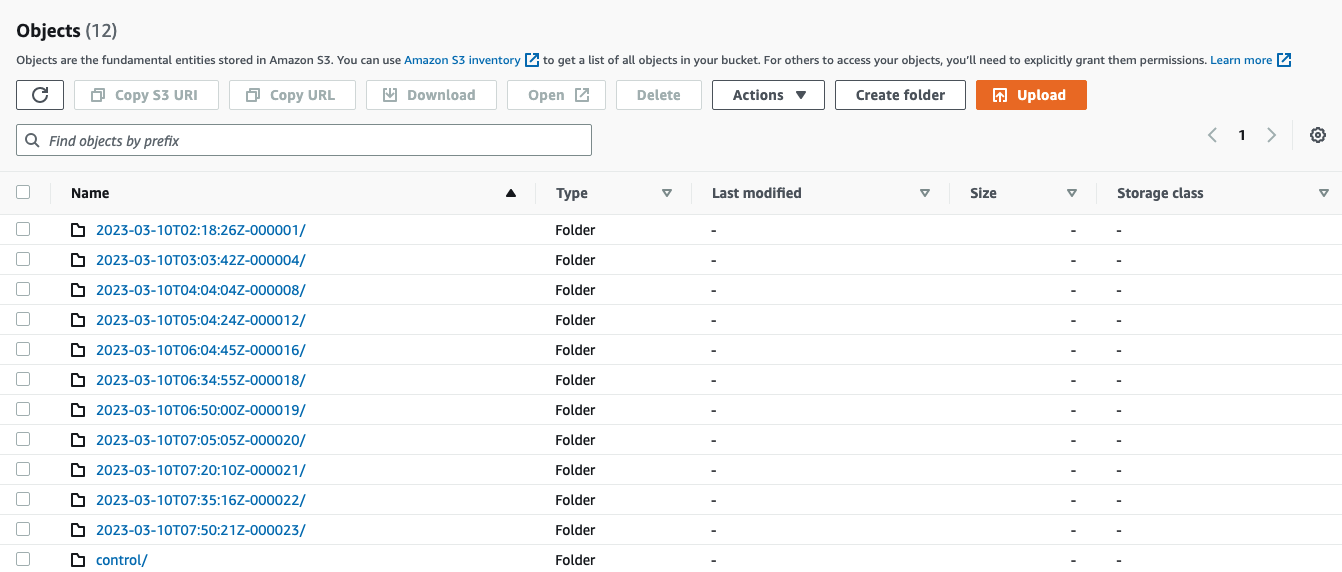
추측하건데, 처음 프로비저닝 시에는 백업 간격을 좀 늘렸다가 안정화 된 이후에 원래 값인 15분으로 하는 것 같다.
리텐션 기간도 설정값이 있으니 공식문서를 참조하자. ETCD Backup
#### 1-2-3. restore
etcd-manager-ctl 설치
https://github.com/kopeio/etcd-manager/releases/tag/3.0.20210228
바이너리 파일을 받아 설치한다.
# backup list 확인 (자신의 S3경로에 맞게 command 를 수정한다.)
etcd-manager-ctl --backup-store=s3://my.clusters/test.my.clusters/backups/etcd/main list-backups
etcd-manager-ctl --backup-store=s3://my.clusters/test.my.clusters/backups/etcd/events list-backups
# 결과
Backup Store: s3://kimchigood/kimchigood.link/backups/etcd/main
I0310 17:28:46.480586 20438 vfs.go:118] listed backups in s3://kimchigood/kimchigood.link/backups/etcd/main: [2023-03-10T02:18:26Z-000001 2023-03-10T03:03:44Z-000004 2023-03-10T04:04:04Z-000008 2023-03-10T05:04:25Z-000012 2023-03-10T06:04:45Z-000016 2023-03-10T07:05:06Z-000020 2023-03-10T07:35:16Z-000022 2023-03-10T07:50:21Z-000023 2023-03-10T08:05:26Z-000024 2023-03-10T08:20:31Z-000025]
2023-03-10T02:18:26Z-000001
2023-03-10T03:03:44Z-000004
2023-03-10T04:04:04Z-000008
2023-03-10T05:04:25Z-000012
2023-03-10T06:04:45Z-000016
2023-03-10T07:05:06Z-000020
2023-03-10T07:35:16Z-000022
2023-03-10T07:50:21Z-000023
2023-03-10T08:05:26Z-000024
2023-03-10T08:20:31Z-000025파드 실행 후 다음 백업까지 기다리기
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
(⎈|kimchigood:default) [root@kops-ec2 ~]# k get po
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 6m25s
백업 확인하기
(⎈|kimchigood:default) [root@kops-ec2 ~]# ./etcd-manager-ctl-linux-amd64 --backup-store=s3://kimchigood/kimchigood.link/backups/etcd/events list-backups
Backup Store: s3://kimchigood/kimchigood.link/backups/etcd/events
I0310 17:37:37.564330 21788 vfs.go:118] listed backups in s3://kimchigood/kimchigood.link/backups/etcd/events: [2023-03-10T02:18:26Z-000001 2023-03-10T03:03:42Z-000004 2023-03-10T04:04:04Z-000008 2023-03-10T05:04:24Z-000012 2023-03-10T06:04:45Z-000016 2023-03-10T07:05:05Z-000020 2023-03-10T07:35:16Z-000022 2023-03-10T07:50:21Z-000023 2023-03-10T08:05:26Z-000024 2023-03-10T08:20:31Z-000025 2023-03-10T08:35:37Z-000026]
2023-03-10T02:18:26Z-000001
2023-03-10T03:03:42Z-000004
2023-03-10T04:04:04Z-000008
2023-03-10T05:04:24Z-000012
2023-03-10T06:04:45Z-000016
2023-03-10T07:05:05Z-000020
2023-03-10T07:35:16Z-000022
2023-03-10T07:50:21Z-000023
2023-03-10T08:05:26Z-000024
2023-03-10T08:20:31Z-000025
2023-03-10T08:35:37Z-0000262023-03-10T08:35:37Z-000026 에 파드가 구동중인 기록이 저장되어 있을 것 이다.
다시 파드 삭제하기
(⎈|kimchigood:default) [root@kops-ec2 ~]# k delete po nginx
pod "nginx" deletedetcd restore!
이제 backup 되어 있는 ETCD를 복구해보자. master, events 모두 2023-03-10T08:35:37Z-000026 로 복구를 해야 지워졌다 파드가 살아날 것 이다!
restore 하기
(⎈|kimchigood:default) [root@kops-ec2 ~]# ./etcd-manager-ctl --backup-store=s3://kimchigood/kimchigood.link/backups/etcd/main restore-backup 2023-03-10T08:35:37Z-000026
Backup Store: s3://kimchigood/kimchigood.link/backups/etcd/main
I0310 17:46:43.399877 22437 vfs.go:76] Adding command at s3://kimchigood/kimchigood.link/backups/etcd/main/control/2023-03-10T08:46:43Z-000000/_command.json: timestamp:1678438003399765198 restore_backup:<cluster_spec:<member_count:1 etcd_version:"3.5.7" > backup:"2023-03-10T08:35:37Z-000026" >
added restore-backup command: timestamp:1678438003399765198 restore_backup:<cluster_spec:<member_count:1 etcd_version:"3.5.7" > backup:"2023-03-10T08:35:37Z-000026" >
(⎈|kimchigood:default) [root@kops-ec2 ~]# ./etcd-manager-ctl --backup-store=s3://kimchigood/kimchigood.link/backups/etcd/events restore-backup 2023-03-10T08:35:37Z-000026
Backup Store: s3://kimchigood/kimchigood.link/backups/etcd/events
I0310 17:47:30.492711 22483 vfs.go:76] Adding command at s3://kimchigood/kimchigood.link/backups/etcd/events/control/2023-03-10T08:47:30Z-000000/_command.json: timestamp:1678438050492604500 restore_backup:<cluster_spec:<member_count:1 etcd_version:"3.5.7" > backup:"2023-03-10T08:35:37Z-000026" >
added restore-backup command: timestamp:1678438050492604500 restore_backup:<cluster_spec:<member_count:1 etcd_version:"3.5.7" > backup:"2023-03-10T08:35:37Z-000026" >
# 결과
(⎈|kimchigood:default) [root@kops-ec2 ~]# k get po
No resources found in default namespace.
분명 restore를 했는데 복구가 되지 않는다!
공홈의 내용을 보면,
Note that this does not start the restore immediately; you need to restart etcd on all masters. You can do this with a docker stop or kill on the etcd-manager containers on the masters (the container names start with k8s_etcd-manager_etcd-manager). The etcd-manager containers should restart automatically, and pick up the restore command. You also have the option to roll your masters quickly, but restarting the containers is preferred.
master 노드에 진입해서 etcd 관련 container를 종료해야한다고 한다.
이부분이 사실 조금 까다로웠다. k8s의 컨테이너 런타임이 docker에서 containerd로 바뀐 후 익숙하지 않은 ctr 명령어를 사용해야한다.
그럼 마스터 노드로 접근해보자.
$ ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME
# etcd 컨테이너를 찾는다.
$ sudo ctr -n k8s.io container list |grep etcd
7ac2591df69cfc810a1441e3178f0de3b64f4fae62a656473038c225df6c3fab registry.k8s.io/etcdadm/etcd-manager@sha256:5ffb3f7cade4ae1d8c952251abb0c8bdfa8d4d9acb2c364e763328bd6f3d06aa io.containerd.runc.v2
ce174cd3e17cefd4f60dbdae4eb400005f27ebca0cdbca1d8a6c7a0c652ad3fc registry.k8s.io/etcdadm/etcd-manager@sha256:5ffb3f7cade4ae1d8c952251abb0c8bdfa8d4d9acb2c364e763328bd6f3d06aa io.containerd.runc.v2
# 컨테이너 죽이기
$ ctr -n k8s.io task pause 7ac2591df69cfc810a1441e3178f0de3b64f4fae62a656473038c225df6c3fab
$ ctr -n k8s.io task pause ce174cd3e17cefd4f60dbdae4eb400005f27ebca0cdbca1d8a6c7a0c652ad3fc
$ ctr -n k8s.io task kill 7ac2591df69cfc810a1441e3178f0de3b64f4fae62a656473038c225df6c3fab
$ ctr -n k8s.io task kill ce174cd3e17cefd4f60dbdae4eb400005f27ebca0cdbca1d8a6c7a0c652ad3fc
# 컨테이너 확인
root@i-00872f0bcc3d9ab02:~# ctr -n k8s.io container ls | grep etcd
7ac2591df69cfc810a1441e3178f0de3b64f4fae62a656473038c225df6c3fab registry.k8s.io/etcdadm/etcd-manager@sha256:5ffb3f7cade4ae1d8c952251abb0c8bdfa8d4d9acb2c364e763328bd6f3d06aa io.containerd.runc.v2
8224d5ee482b3477107812366e14d51658afa69fa96085202f4d412925b39fa9 registry.k8s.io/etcdadm/etcd-manager@sha256:5ffb3f7cade4ae1d8c952251abb0c8bdfa8d4d9acb2c364e763328bd6f3d06aa io.containerd.runc.v2
ce174cd3e17cefd4f60dbdae4eb400005f27ebca0cdbca1d8a6c7a0c652ad3fc registry.k8s.io/etcdadm/etcd-manager@sha256:5ffb3f7cade4ae1d8c952251abb0c8bdfa8d4d9acb2c364e763328bd6f3d06aa io.containerd.runc.v2
f3da2fb2a083c9a90e0ca3ade8a7d5680396f8a5158cd1f9cf5a8708cb563604 registry.k8s.io/etcdadm/etcd-manager@sha256:5ffb3f7cade4ae1d8c952251abb0c8bdfa8d4d9acb2c364e763328bd6f3d06aa io.containerd.runc.v2
아까와 다르게 새로운 두개의 컨테이너가 생성되었다.
그럼 결과는?
(⎈|kimchigood:default) [root@kops-ec2 ~]# k get po
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 27m복구가 되는 클라스를 보여준다.
후.. 보통 CSP Managed k8s를 사용하면 Control Plane을 알아서 관리해주기 때문에 ETCD까지는 신경 안썻는데, 이런건 항상 어려운 부분인 것 같다.

오! etcd 백업 복구까지 실습 및 정리를 잘 해주셨네요.
좋은 글 잘 보고 갑니다!
이번 스터디도 잘 부탁드립니다