ComputerScience
1.Algorithm & Data Structure (0) - 알고리즘과 자료구조의 중요성

코딩을 처음 배울 때는 우선 올바르게 돌아가게 하는 것이 목표이며 또한 목표여야 한다. 코드가 실제로 동작하는가? 라는 단순한 기준으로 코드를 평가한다.하지만 경험이 쌓이면서 소프트웨어 공학자는 코드 품질 측면에서 또 다른 계층들과 미묘한 차이를 익혀나가기 시작한다.
2.Algorithm & Data Structure (1) - 시간복잡도와 빅오 표기법
우리는 알고리즘의 속도를 어떻게 판단할까? 시간으로 판단할까?그렇다면 상대적으로 처리속도가 느린 프로세서에서 처리가 느리다면?이러한 기준에 대한 통일을 위해 알고리즘의 속도를 '단계'의 갯수로 판단한다. 이러한 단계에 대한 평가 척도를 시간 복잡도 라고 한다.즉, '입
3.Algorithm & Data Structure (2) - Bubble Sort로 알아보는 이차 시간 문제
버블 정렬은 가장 기본적인 정렬 알고리즘 이다. 다음은 C코드로 작성된 버블 정렬의 예제이다. 버블 정렬은 기본적으로 두 단계로 이루어 져있는데, 비교 와 교환 이다.버블 정렬의 순서는 다음과 같다.최악의 상황을 고려해보자, 가장 최악의 상황은 1번의 비교마다 1번의
4.Algorithm & Data Structure(3) - 빅 오 카테고리
저번 글에서 버블 정렬에 대한 내용을 정리했었는데, 이번엔 먼저 선택 정렬을 알아보겠다. 선택 정렬의 C 코드는 다음과 같다.버블정렬과의 차이점은, 선택 정렬은 비교후에 교환을 한다는 점으로, 비교 즉시 교환하는 버블정렬과 다르게, 한 번의 패스스루에서 불필요한 교환을
5.Algorithm & Data Structure(4) - 시나리오 최적화
지금까지 버블 정렬, 선택 정렬을 알아보았고, 선택 정렬이 버블 정렬 보다 약 두배 빠름 또한 알고 있다. 이번에는 삽입 정렬을 통해, 최악의 경우가 아닌 다른 시나리오를 분석하는 것에 어떤 장점이 있는지 알아 보자.위는 삽입 정렬의 C코드이다. 삽입 정렬은 시프트라는
6.Algorithm & Data Structure (5) - Hashing Table
해시 테이블 대부분의 프로그래밍 언어는 해시 테이블(Hash Table)이라는 자료구조를 포함한다. 해시 테이블에는 빠른 읽기라는 놀랍고 엄청난 능력이 있다. 해시 테이블은 다양한 프로그래밍 언어에서 서로 다른 이름으로 불린다. 해시, 맵, 해시 맵, 딕셔너리, 연관
7.Algorithm & Data Structure(6) - Stack과 Queue - (2) Queue
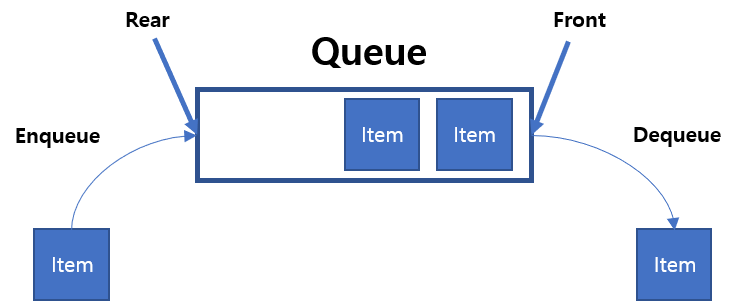
큐 역시 임시 데이터를 처리하기 위해 디자인된 데이터 구조다. 데이터를 처리하는 순서만 제외하면, 많은 면에서 스택과 비슷하다. 스택처럼 큐도 추상 데이터 타입이다.극장에 줄 서 있는 사람들을 큐처럼 생각할 수 있다. 줄 맨 앞에 있는 사람이 그 줄을 떠나 가장 먼저
8.Algorithm & Data Structure(7) - 재귀(Recursion) (1)
재귀(Recursion) 재귀란 사전적 의미로 '원래의 자리로 되돌아 가거나 되돌아 옴.' 을 의미한다. 프로그래밍에서 재귀는 원래의 자리로 되돌아 온다라는 의미보다는 '돌고 돌다' 라는 의미가 더 어울릴 것이다. 재귀를 간단하게 설명하기 위해 0부터 10까지 출력하는