형태소 분석기 연습
Regular Expression
- 파이썬에 기본적으로 제공되는 정규표현식 모듈
import re #re: 정규 표현식# 기호 .
r = re.compile("a.c")print(r.search("qwerty"))Noner.search("abc")<re.Match object; span=(0, 3), match='abc'>- 여러가지 사용 방법이 있는데 아래 링크에서 더 자세히 알아볼 수 있다.
- 점프 투 파이썬 08 정규 표현식 : https://wikidocs.net/1669
JPype
-
JPype는 java 라이브러리지만 python으로 가져와서 이용할 수 있다.
-
JPype 파일을 conda경로에 넣어준다.
파일 이름으로 파이썬 버전과 64비트 버전등을 확인하고 알맞은 설치파일을 가져와야 한다.
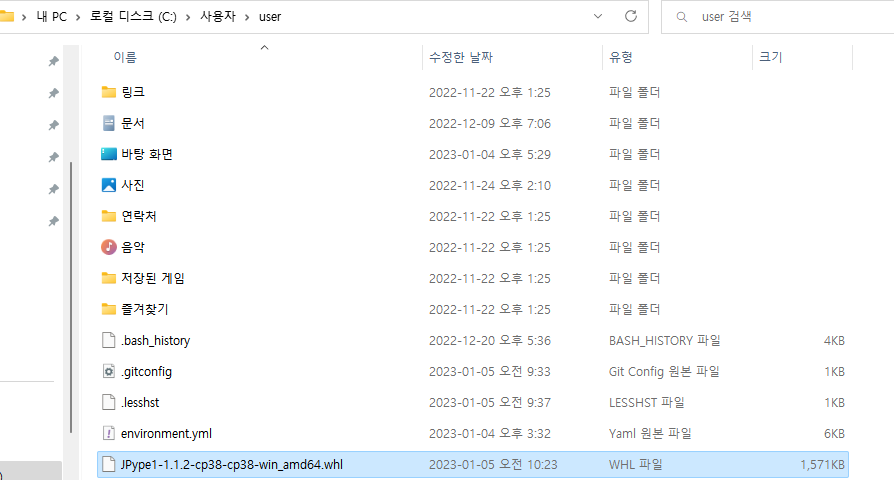
- conda prompt에서 pip install 파일이름으로 설치해준다.
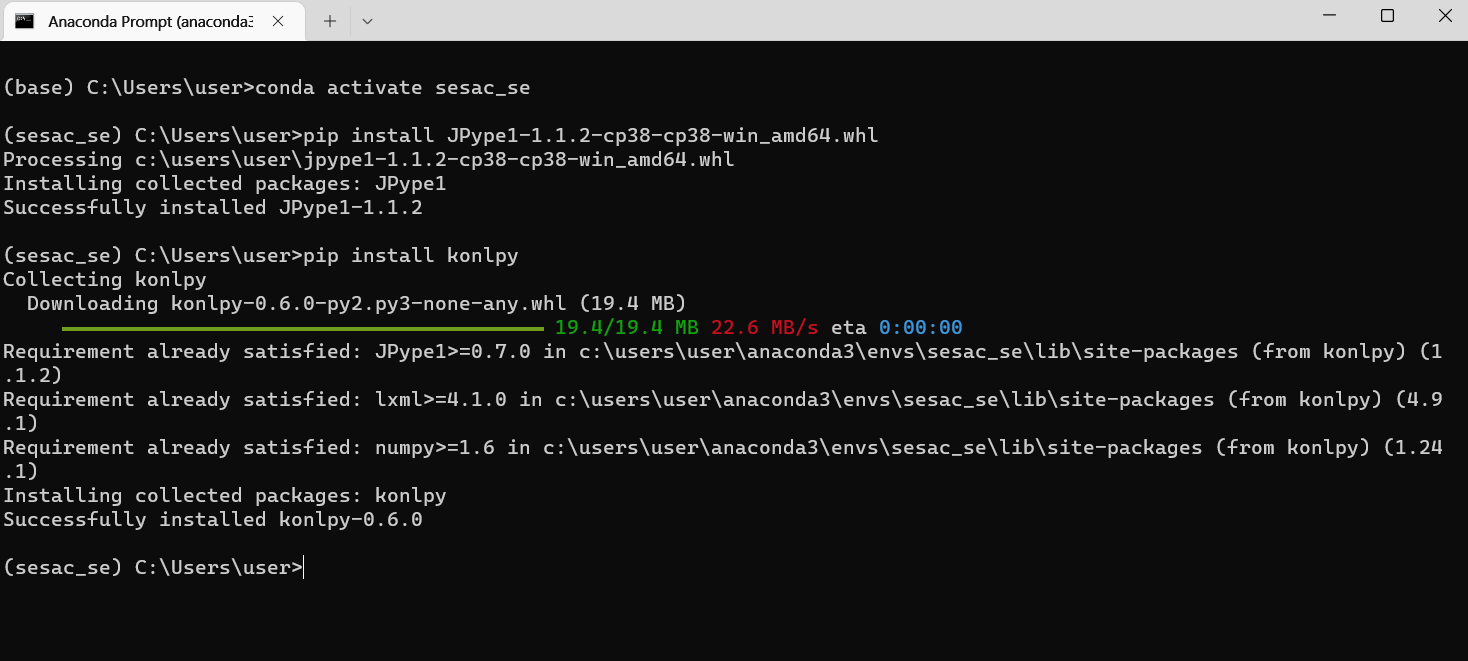
Konlpy
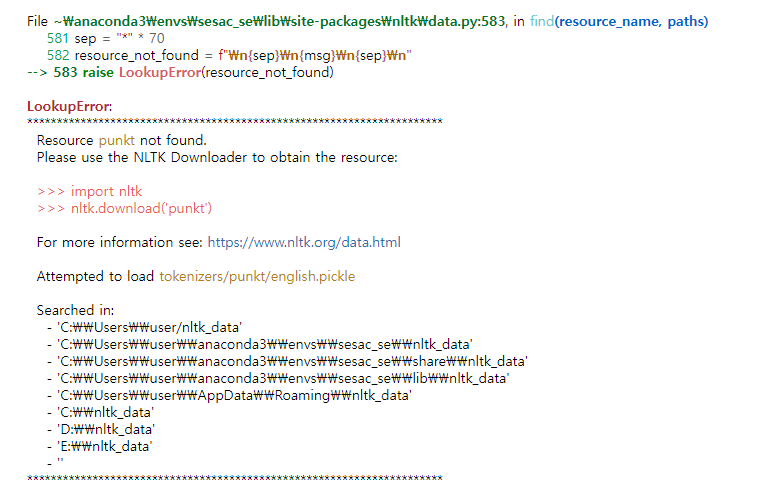
- 이런식으로 nltk설치만으로는 부족할 때 에러메시지가 나올 수 있다. 이 경우에는 에러메시지에 나온 모듈을 다운로드해 주면 된다.
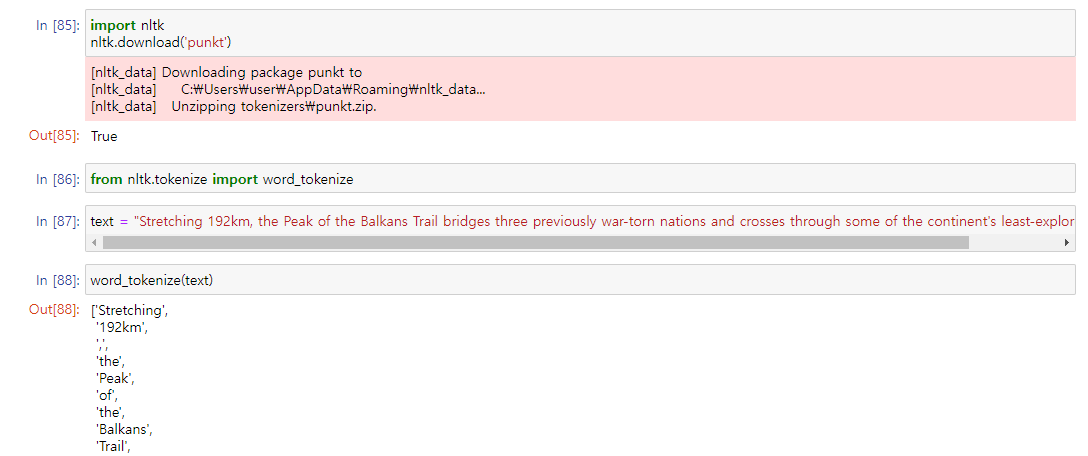
- 다운로드 후에는 문장을 잘 해석한 것을 볼 수 있다.
Nltk
- 영어전용 형태소 분석기
import nltk
nltk.download('punkt')[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\user\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
Truefrom nltk.tokenize import word_tokenize
from nltk.tokenize import WordPunctTokenizer
from nltk.tokenize import sent_tokenize
from tensorflow.keras.preprocessing.text import text_to_word_sequencetext = """According to local legend, the devil escaped from hell and created the jagged glacial karsts in a single day of mischief."""print(word_tokenize(text))['According', 'to', 'local', 'legend', ',', 'the', 'devil', 'escaped', 'from', 'hell', 'and', 'created', 'the', 'jagged', 'glacial', 'karsts', 'in', 'a', 'single', 'day', 'of', 'mischief', '.']kss
- 한국어 문장 분리 형태소 분석기
import ksstext = "딥러닝 자연어 처리는 흥미롭습니다. 그런데 재미는 없을 수도 있습니다. 특히 일상 언어는 너무 복잡합니다."
kss.split_sentences(text)[Kss]: Because there's no supported C++ morpheme analyzer, Kss will take pecab as a backend. :D
For your information, Kss also supports mecab backend.
We recommend you to install mecab or konlpy.tag.Mecab for faster execution of Kss.
Please refer to following web sites for details:
- mecab: https://cleancode-ws.tistory.com/97
- konlpy.tag.Mecab: https://uwgdqo.tistory.com/363
['딥러닝 자연어 처리는 흥미롭습니다.', '그런데 재미는 없을 수도 있습니다.', '특히 일상 언어는 너무 복잡합니다.']from konlpy.tag import Okt, Kkmaokt = Okt()
kkma = Kkma()text = "열심히 코딩한 당신, 잠도 잘 자고 일하세요."
print('---- OKT ----')
print("형태소 분석", okt.morphs(text))
print("품사 태깅", okt.pos(text))
print("명사 분석", okt.nouns(text)) #단어를 쪼갤 때는 명사를 주로 분석한다.print('---- OKT ----')
print('---- KKMA ----')
print("형태소 분석", kkma.morphs(text))
print("품사 태깅", kkma.pos(text))
print("명사 분석", kkma.nouns(text)) #단어를 쪼갤 때는 명사를 주로 분석한다.
# 구두를 추천받아야 하는 상황에 드레스를 추천하면 하면 안되기 때문에 구분 잘 하는게 중요---- OKT ----
형태소 분석 ['열심히', '코딩', '한', '당신', ',', '잠도', '잘', '자고', '일', '하세요', '.']
품사 태깅 [('열심히', 'Adverb'), ('코딩', 'Noun'), ('한', 'Josa'), ('당신', 'Noun'), (',', 'Punctuation'), ('잠도', 'Noun'), ('잘', 'Verb'), ('자고', 'Noun'), ('일', 'Noun'), ('하세요', 'Verb'), ('.', 'Punctuation')]
명사 분석 ['코딩', '당신', '잠도', '자고', '일']
---- KKMA ----
형태소 분석 ['열심히', '코딩', '하', 'ㄴ', '당신', ',', '잠', '도', '잘', '자', '고', '일하', '세요', '.']
품사 태깅 [('열심히', 'MAG'), ('코딩', 'NNG'), ('하', 'XSV'), ('ㄴ', 'ETD'), ('당신', 'NP'), (',', 'SP'), ('잠', 'NNG'), ('도', 'JX'), ('잘', 'MAG'), ('자', 'VV'), ('고', 'ECE'), ('일하', 'VV'), ('세요', 'EFN'), ('.', 'SF')]
명사 분석 ['코딩', '당신', '잠']Pykospacing
- 띄어쓰기를 자동으로 해주는 라이브러리
# !pip install git+https://github.com/haven-jeon/PyKoSpacing.git --usertext = """'그 효과는 득점 장면을 제외한 경기 내용에서도 잘 드러났다. 손흥민이 중앙으로 이동할 때마다 경기가 손쉽게 풀렸다. 후반 22분 단짝인 케인이 찔러준 공을 받은 뒤 질주해 페널티지역에서 슈팅을 시도한 것이 대표적이다. 1분 뒤에는 케인에서 건네받은 공을 맷 도허티에게 연결해 추가골로 이어졌다. EPL 규정상 공식 어시스트로 기록되지 않은 게 아쉬울 따름이다."""# 띄어쓰기 전부 삭제 해주기
new_text = text.replace(" ", "")
new_text"'그효과는득점장면을제외한경기내용에서도잘드러났다.손흥민이중앙으로이동할때마다경기가손쉽게풀렸다.후반22분단짝인케인이찔러준공을받은뒤질주해페널티지역에서슈팅을시도한것이대표적이다.1분뒤에는케인에서건네받은공을맷도허티에게연결해추가골로이어졌다.EPL규정상공식어시스트로기록되지않은게아쉬울따름이다."from pykospacing import Spacing# 원본 문장이랑 자동 띄어쓰기 처리 해준 내용 비교해보기
s = Spacing()
recon_text = s(new_text)
print(text)
print(recon_text)1/1 [==============================] - 0s 412ms/step
'그 효과는 득점 장면을 제외한 경기 내용에서도 잘 드러났다. 손흥민이 중앙으로 이동할 때마다 경기가 손쉽게 풀렸다. 후반 22분 단짝인 케인이 찔러준 공을 받은 뒤 질주해 페널티지역에서 슈팅을 시도한 것이 대표적이다. 1분 뒤에는 케인에서 건네받은 공을 맷 도허티에게 연결해 추가골로 이어졌다. EPL 규정상 공식 어시스트로 기록되지 않은 게 아쉬울 따름이다.
'그 효과는 득점 장면을 제외한 경기내용에서도 잘 드러났다. 손흥민이 중앙으로 이동할 때마다 경기가 손쉽게 풀렸다. 후반 22분 단짝 인케인이 찔러준공을 받은 뒤 질주해 페널티 지역에서 슈팅을 시도한 것이 대표적이다.1분 뒤에는 케인에서 건네받은 공을 맷도 허티에게 연결해 추가골로 이어졌다. EPL 규정상 공식 어시스트로 기록되지 않은 게 아쉬울 따름이다.- 명사(ex:맷 도허티) 처럼 어려운 부분이 아니면 띄어쓰기를 해준다.
Hanspell
- 한국어 맞춤법 교정 라이브러리
# !pip install git+https://github.com/ssut/py-hanspell.gitfrom hanspell import spell_checker# 일부러 맞춤법 틀린 문장 적기
text_x = "마춤법 틀리묜 외않된데? 내맴대로 쓰묜되징!"
text_ok = spell_checker.check(text_x)
text_ok.checked
'맞춤법 틀리면 외않된데? 내맴대로 쓰묜되징!'- 심각한 오타는 고치지 못한다.
# 일부러 맞춤법 틀린 문장 적기
text_x = "마춤법 틀리면 외 않되? 내맘대로 쓰면돼지!"
text_ok = spell_checker.check(text_x)
text_ok.checked
'맞춤법 틀리면 왜 안돼? 내 맘대로 쓰면 되지!'- 어느정도 맞춤법을 교정해준다.
Soynlp
- 문자나열 간소화 라이브러리
# !pip install soynlpfrom soynlp.normalizer import *# 이모티콘 간소화?. 너무 긴 이모티콘성 문장을 적당하게 줄여줌
text = '앜ㅋㅋㅋㅋㅋㅋㅋㅋㅋ이김밥존맛탱쿠쿠쿠ㅜㅜㅜㅋㅋㅋㅋㅋㅋㅋㅋ'
emoticon_normalize(text)'아ㅋㅋ김밥존맛탱쿠쿠쿠ㅜㅜㅜㅋㅋ'emoticon_normalize(text, num_repeats=3) # num_repeats : 길이 조절도 직접 가능함.'아ㅋㅋㅋ김밥존맛탱쿠쿠쿠ㅜㅜㅜㅋㅋㅋ'Stopwords
- 불용어를 필터링해주는 라이브러리
import nltk
# 필요한 패키지 미리 다운로드
# nltk.download("stopwords")
# nltk.download("punkt")from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from konlpy.tag import Okt# 몇개 정도의 불용어가 정의돼있는지 확인
stop_words_list = stopwords.words("english")
len(stop_words_list)
# 179개의 불용어 정의됨179# 어떤 내용을 불용어로 정의했는지 10개만 확인
stop_words_list[:10]['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]test = "Mr Jassy did not specify where affected employees were located, but he said the firm would communicate with organisations that represent employees"
test = test.lower() # 소문자로 변환
token_1 = word_tokenize(test) # 워드 토크나이저로 분석해보기. (불용어 제거 전)
print(token_1) # 문장 내 단어 모두 분리.['mr', 'jassy', 'did', 'not', 'specify', 'where', 'affected', 'employees', 'were', 'located', ',', 'but', 'he', 'said', 'the', 'firm', 'would', 'communicate', 'with', 'organisations', 'that', 'represent', 'employees']token_2 = [] # 불용어가 아닌것만 담을 빈 리스트 정의. 필터링 된 것만 담아줌.
for word in token_1:
if word not in stop_words_list:
token_2.append(word)
print(token_2)['mr', 'jassy', 'specify', 'affected', 'employees', 'located', ',', 'said', 'firm', 'would', 'communicate', 'organisations', 'represent', 'employees']'i' in stop_words_list # 특정 용어가 불용어 목록에 있는지 조회True'he' in stop_words_list True- 욕설 단어 리스트를 만들어서 필터링할 수 있다.

초보 개발자의 학습 저장용 블로그