Pandas
- 새로운 열 집어넣기
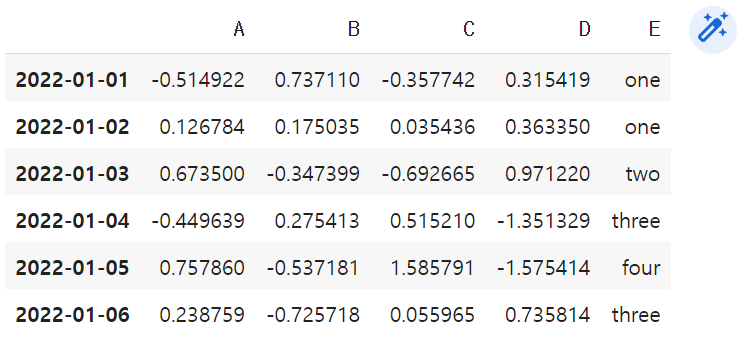
df2 = df.copy()
df2['E'] = ['one', 'one', 'two' ,'three', 'four', 'three']
df2- 출력 결과물
데이터 크롤링
for test in enumerate(webtoons):
print(test)
webtoonRankList1 = [(str(idx), webtoon.get("title")) for (idx, webtoon) in enumerate(webtoons, start=1)]
print(webtoonRankList1)webtoonRankList = []
for (idx, webtoon) in enumerate(webtoons, start=1):
title = webtoon.get("title")
print(f"#{str(idx)}: {title}")
data = [str(idx), title]
webtoonRankList.append(data)
print(webtoonRankList)- 이 경우엔 위 코드가 더 좋은 코드이다. 복잡성이 덜하고 작성자가 혼동할 우려가 적다.
Naver Developers
- 사용 가능한 무료 검색 API를 제공.
- https://developers.naver.com/main/
- 검색 가이드 : https://developers.naver.com/docs/serviceapi/search/blog/blog.md#%EB%B8%94%EB%A1%9C%EA%B7%B8
import os
import sys
import urllib.request
import json
client_id =
client_secret =
searchText = input("검색키워드 : ")
query = urllib.parse.quote(searchText)
display = input("검색 개수(최대 100건) : ")
url = "https://openapi.naver.com/v1/search/blog"
query = f"?query={query}&display={display}&start=1&sort=sim"
request = urllib.request.Request(url+query)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("getcode : ", response.getcode())
print("geturl : ", response.geturl())
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
body = response_body.decode("utf-8")
print("body", body)
else:
print("Error Code : " + rescode)- 위 리스트를 출력하면 아래와 같은 비정형 데이터가 나온다.

- 그러므로 이를 정제하는 과정이 필요하다.
data = json.loads(body)
data
print("lastBuildDate : ", data["lastBuildDate"])
print("total : ",data["total"])
print("start : ",data["start"])
print("display : ",data["display"])
print("items : ",data["items"])
data["items"]
titleList = [i["title"] for i in data["items"]]
print("1: ",titleList)
linkList = [i["link"] for i in data["items"]]
print(linkList)
import pandas as pd
df = pd.DataFrame({'제목' :titleList, '링크':linkList})
df- 출력 결과물

공공데이터 분석
temp = pd.read_csv("/content/drive/MyDrive/data/소상공인시장진흥공단_상가(상권)정보_20220930/소상공인시장진흥공단_상가(상권)정보_인천_202209.csv", encoding="utf-8")
temp
data = temp[['상호명', '지점명', '상권업종대분류명', '상권업종중분류명', '시도명', '시군구명', '행정동명']]
data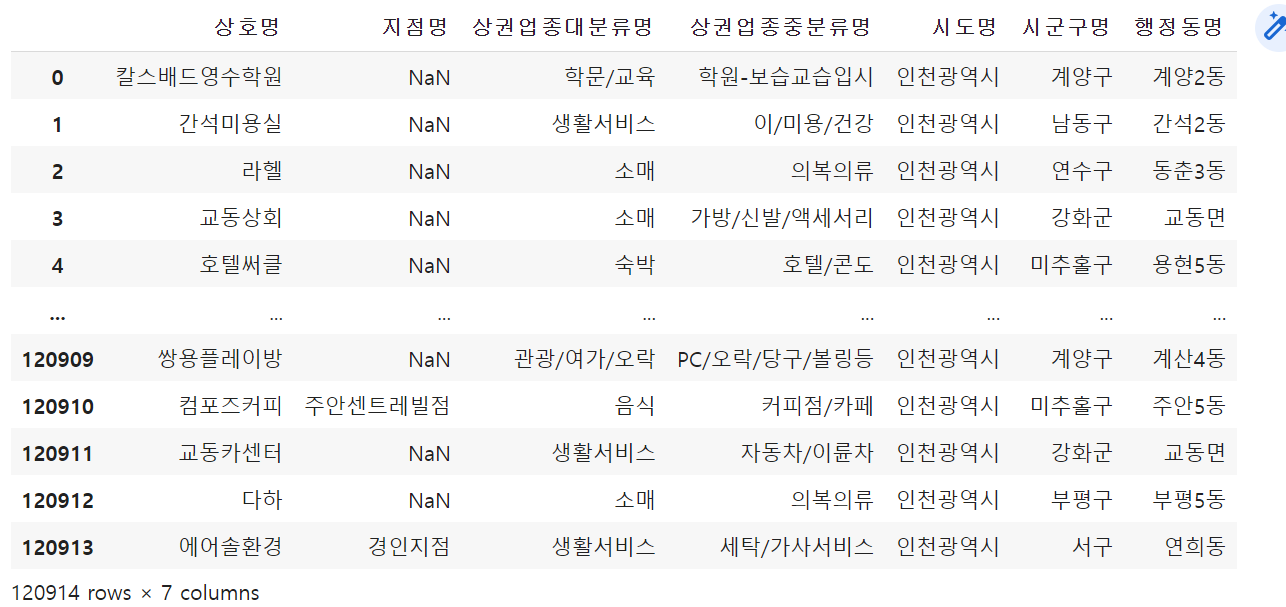
df_coffee = data[data["상권업종중분류명"] == "커피점/카페"]
df_coffee. index = range(len(df_coffee))
print("인천 커피 전문점 점포 수 : ", len(df_coffee))
df_coffee
df_coffee = data[data["상호명"].str.contains("스타벅스")]
df_coffee. index = range(len(df_coffee))
print("스타벅스 점포 수 : ", len(df_coffee))
df_coffee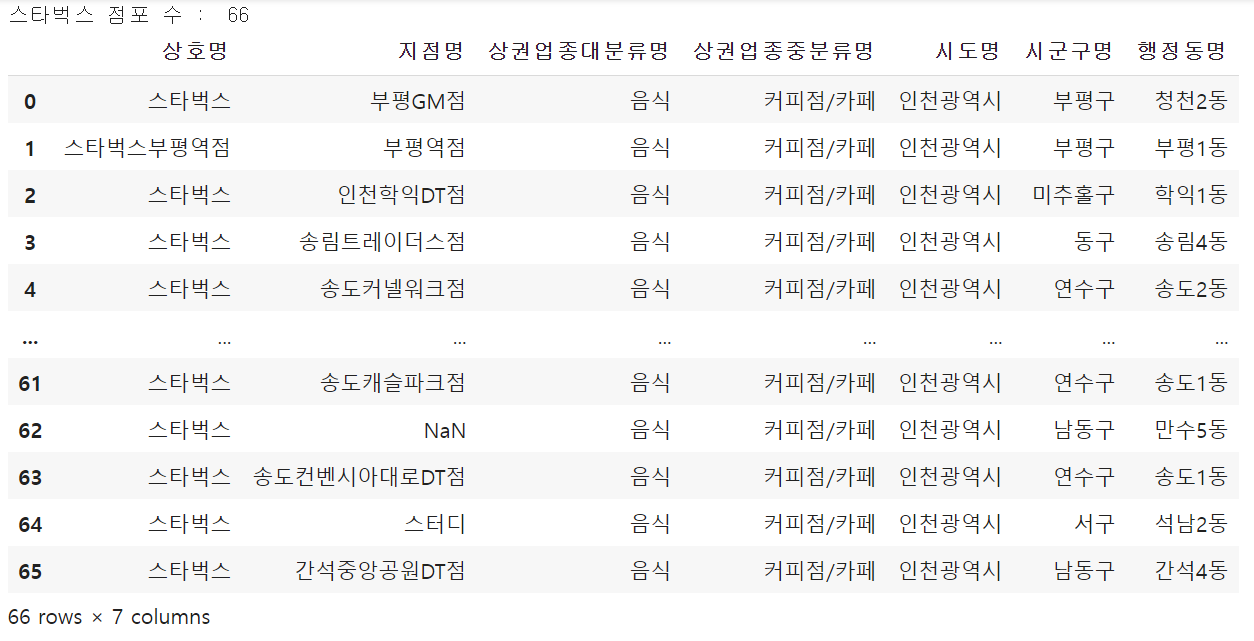

초보 개발자의 학습 저장용 블로그