Multi-Level Feedback Queue
이번 포스트에서는 Multi-Level Feedback Queue( MLFQ )에 대해 알아보겠습니다.
MLFQ에서 해결하려는 문제는 두가지 입니다.
- 짧은 작업을 먼저 실행시켜 반환 시간을 최적화하려고합니다. ( s
- 대화형 사용자에게 응답이 빠른 시스템이라는 느낌을 주고 싶기에, 응답시간을 최적화하려고합니다.
MLFQ : 기본 규칙
MLFQ는 기본적으로 여러개의 큐로 구성되며, 각각 다른 우선 순위가 배정된다.
Ready 상태인 프로세스들은 모두 어떤 큐에 존재하며, MLFQ는 이 큐에 있는 프로세스를 어떠한 규칙에 맞춰서 실행시킨다.
이 규칙은 기본적으로 두 가지가 있는데, 알아보겠습니다.
규칙 1 : 우선 순위가 높은 큐에 존재하는 프로세스들이 먼저 실행됩니다.
규칙 2: 작업들이 같은 우선 순위를 가진다면 RR을 사용하여 실행합니다.
그런데, 이 규칙만을 사용하면 문제가 생기는데 한 번 예시를 보겠습니다.
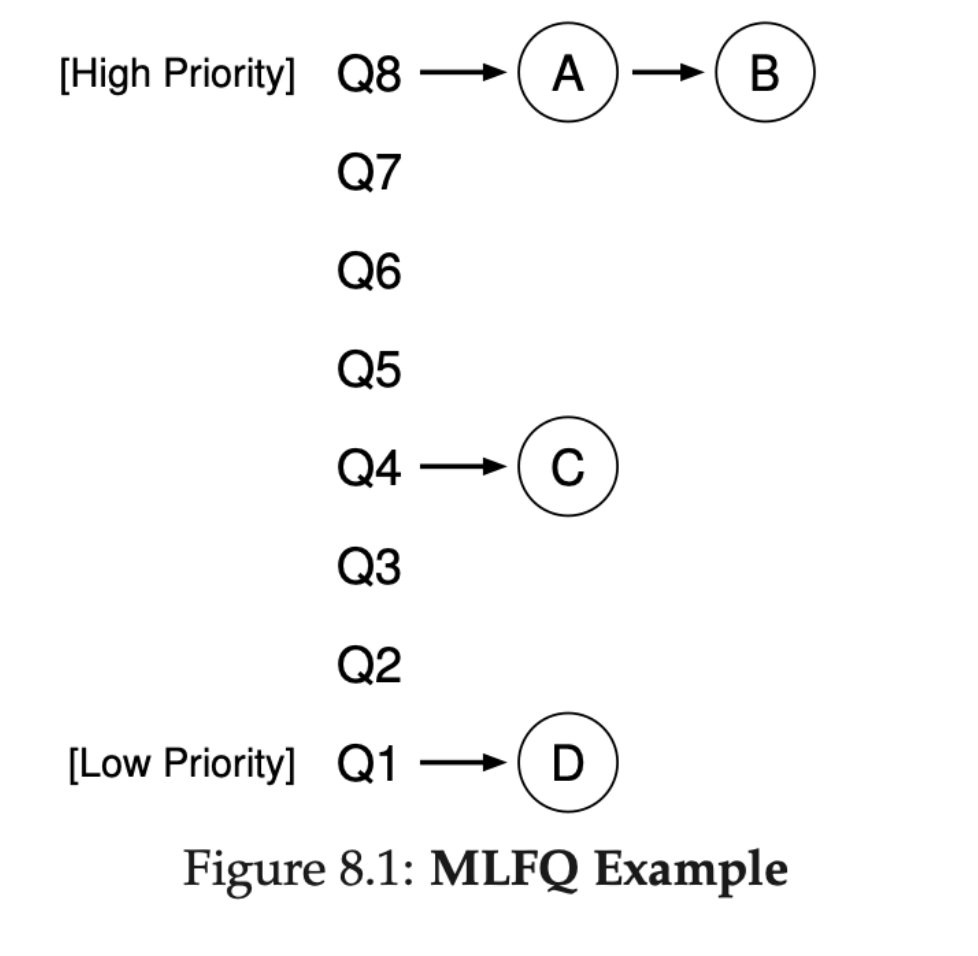
이러한 MLFQ에 프로세스들이 존재한다고 할 때, 규칙 1과 2에 따르면 C는 A와 B가 끝날 때까지 실행되지 않으며 D는 A,B,C가 끝날 때까지 실행되지 않습니다.
이러한 부분은 A와 B가 오랫동안 실행되면, C와 D의 응답시간이 좋지 않게 될 것이며 이것을 해결하기 위해 다음과 같은 시도를 해볼 것입니다.
시도 1 : 우선순위의 변경
우리는 위 문제를 해결하기위해 우선 순위를 변경하는 방법을 정해야합니다.
다음과 같은 규칙을 정하여 우선순위를 변경하는 방법을 정하겠습니다.
규칙 3 : 작업이 시스템에 진입하면, 가장 높은 우선순위 즉 맨 위의 큐에 놓여진다.
규칙 4a : 각각의 큐는 타임슬라이스가 존재하며 주어진 타임 슬라이스를 모두 사용하면, 우선순위가 낮아진다. 즉 한 단계 아래 큐로 이동한다.
규칙 4b : 타임 슬라이스를 소진하기 전에 CPU를 양도하면 ( I/O 작업을 한다거나.. ) 같은 우선순위를 유지한다.
이번에 규칙을 정했으니 또 다른 예시를 통해 규칙이 잘 정해진 것인지 보겠습니다.
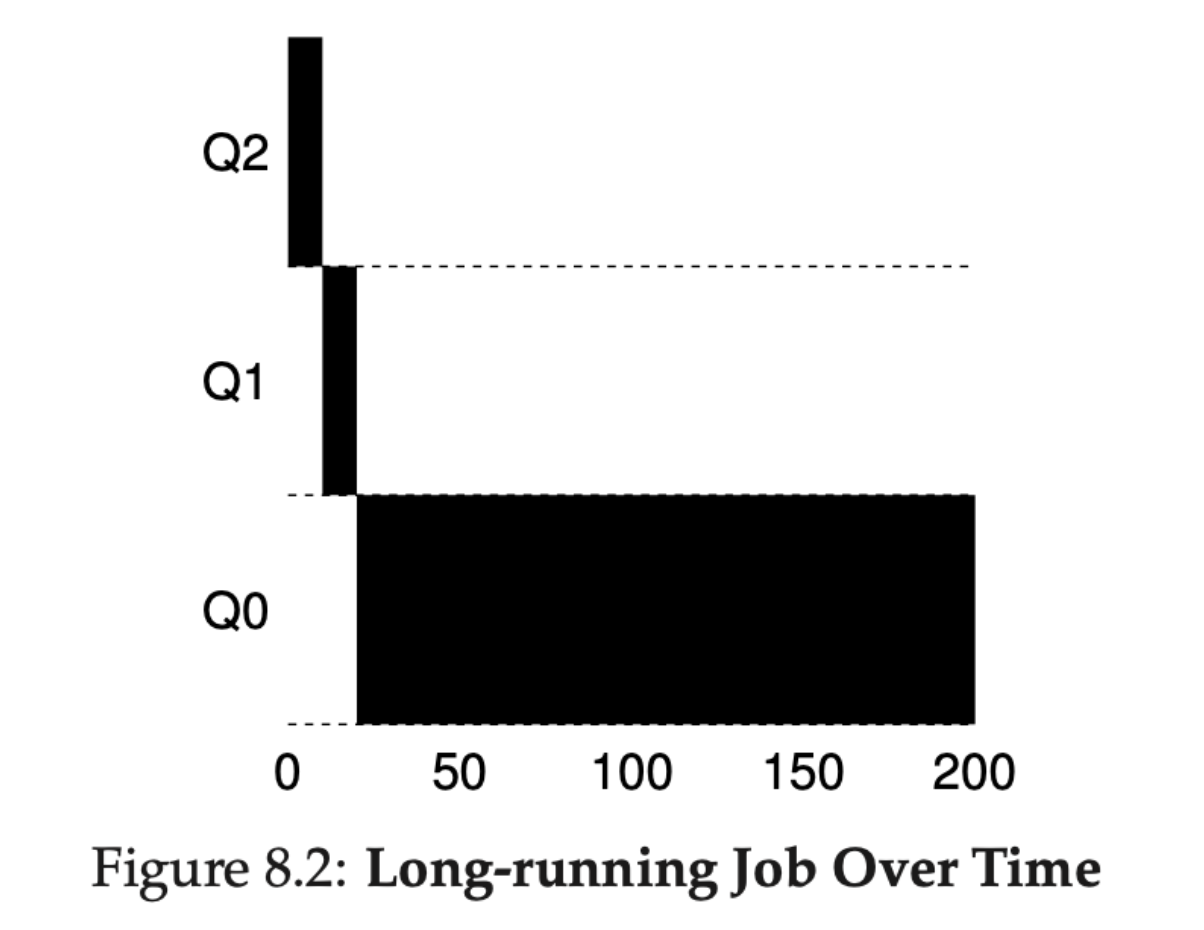
긴 실행시간을 가진 프로세스가 큐에 도착하면 어떻게 작업이 실행되는지 보는 예시입니다.
- 작업은 일단 Q2에 도착하고 10초간의 실행을 합니다.
- 그 후 타임슬라이스를 소진했으니, Q1으로 이동하고 타임슬라이스를 소진하는 동안 실행합니다.
- 마지막으로 가장 우선순위가 낮은 Q0로 이동하고 이후 계속 Q0에 계속 머무르게 된다.
이번에는 두 번째 예시를 보겠습니다.
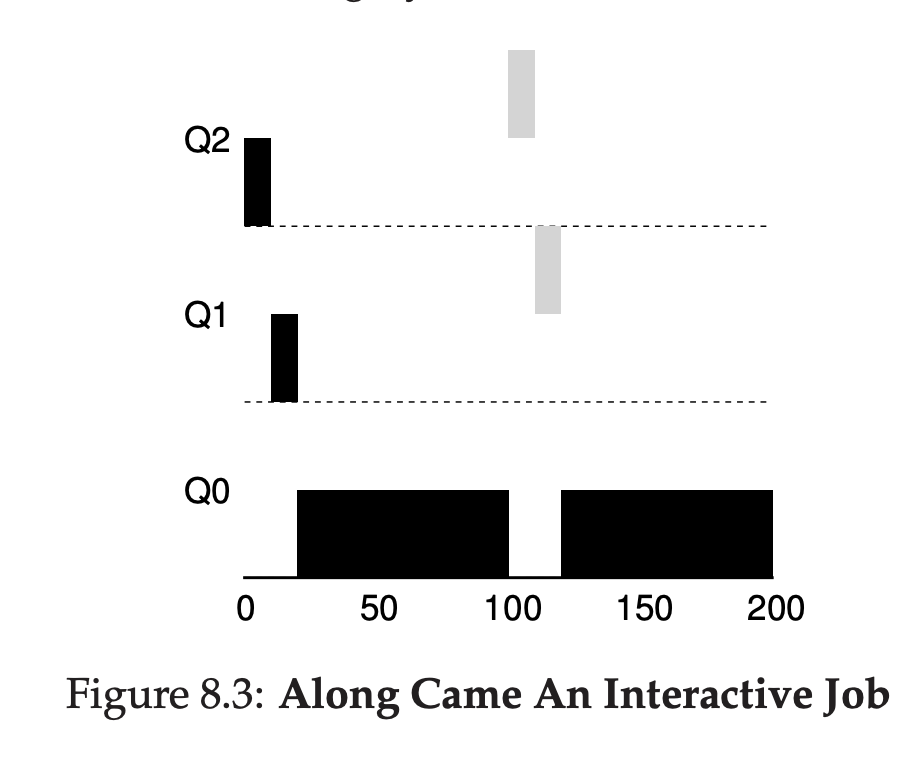
검은색 작업( A )와 회색 작업( B )가 스케줄러에 있다고 생각해보겠습니다.
- A는 스케줄러에 도착한 후 Q2 → Q1 → Q0로 순차적으로 우선순위가 낮아지면서 작업을 수행합니다.
- 그러던 도중에 B가 스케줄러에 도착하고, 규칙에 따라 Q2에 놓여지고 A를 멈추고 B를 수행합니다.
- Q2에서 타임슬라이스를 마친 B는, Q1으로 이동하고 아직도 A보다 우선순위가 높기 때문에 계속 실행됩니다.
- Q1에서 작업을 마친 B는 종료되며, A는 Q0에서 재개됩니다.
이 예시를 통해 MLFQ의 주요 목표를 알 수 있습니다.
- 작업이 짧은 작업인지, 긴 작업인지 알수 없기 때문에 일단 짧은 작업이라 가정하여 높은 우선순위를 부여합니다.
- 진짜 짧은 작업이라면 빨리 실행되고 바로 종료될 것입니다.
- 짧은 작업이 아니라면 천천히 아래 큐로 이동하게 되고 스스로 긴 배치형 작업이라는 것을 증명하게 됩니다
→ 이 방식으로 MLFQ가 SJF를 근사할 수 있습니다.
이번에는 I/O 처리를 어떻게 하는지 예시를 보겠습니다.
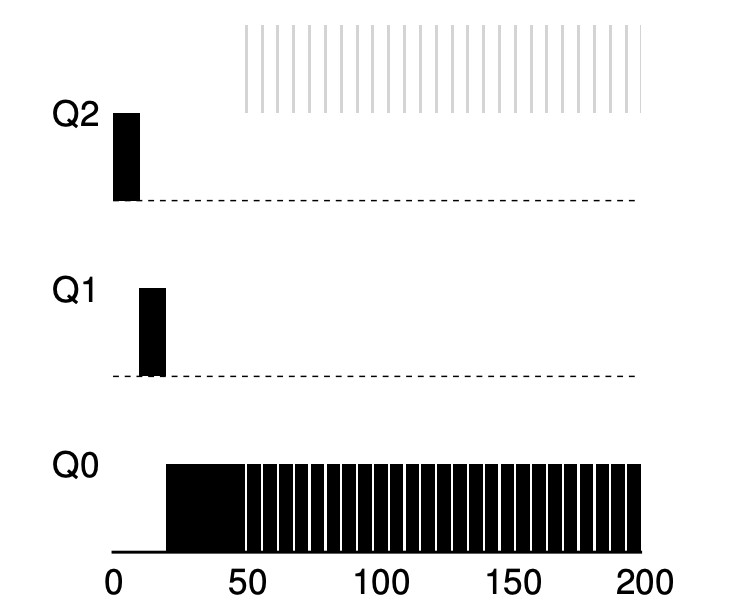
검은색 작업( A )와 회색 작업( B )가 스케줄러에 있다고 생각해보겠습니다.
- A는 스케줄러에 도착한 후 Q2 → Q1 → Q0로 순차적으로 우선순위가 낮아지면서 작업을 수행합니다.
- 그러던 도중에 B가 스케줄러에 도착하고, 규칙에 따라 Q2에 놓여지고 A를 멈추고 B를 수행합니다
- B는 타임슬라이스가 소진되기전에, I/O 작업을 실행하며 그렇기에 우선순위를 유지합니다.
- A는 B가 I/O 작업을 진행하는 동안 작업을 수행합니다.
이를 통해, 규칙이 잘 정의된 것처럼 보입니다.
B는 응답시간이 빠르게 진행되고, A는 반환시간이 적당히 빠르게 유지됩니다.
하지만, 이 규칙을 교묘하게 피해가는 방법이 있는데, 이 방법이 큰 문제를 발생시키기에 아래 예시를 통해 알아보겠습니다.
현재 MLFQ의 문제점
- 기아 상태(starvation)가 발생할 수 있습니다.
시스템에 너무 많은 대화형 작업이 존재하면 그들이 모든 CPU 시간을 소모하게 될 것이고 따라서 긴 실행 시간 작업은 그 작업들이 끝날때까지 CPU 시간을 할당 받지 못할 것입니다. ( 굶어 죽습니다 )
- 스케줄러를 속이기위해, 계속 우선순위를 높이는 프로그램이 존재할 수 있습니다.
타임 슬라이스가 10초로 정해져있는 스케줄러에서, 9.9초 동안 수행하고 I/O 작업을 발생시킨다고 생각해보겠습니다. 그럼 스케줄러의 규칙에 따라 계속 높은 우선순위를 유지하게 됩니다. 이렇게 되면 CPU를 거의 독점할 수 있다는 문제가 생깁니다.
- 마지막으로 프로그램이 수행되는 동안 특성이 변할 수도 있다는 것입니다.
CPU만 사용하는 작업인 줄 알고, 우선순위를 낮췄는데 I/O를 실행하려한다거나 대화형 작업으로 변화한다면 어떻게 될까요? 이 작업은 운도없게 다른 대화형 작업같은 대우를 못받게 됩니다.
이걸 어떻게 해결할까요.
시도 2 : 우선순위의 상향 조정 ( Priority Boost )
위의 문제를 해결하기위해 우리는 규칙을 하나 새로 만들 것입니다.
규칙 5 : 일정 기간 S가 지나면, 시스템의 모든 작업을 다시 최상위 큐로 이동시킵니다.
새 규칙은 두 가지 문제를 한 번에 해결합니다.
-
프로세스가 굶어죽지 않는다는 것을 보장합니다.
최상위 큐로 돌아오는 순간 RR을 통해 타임 슬라이스동안 CPU를 사용할 수 있게됩니다.
-
CPU의 위주 작업이 대화형 작업으로 변했을 때, 우선순위 상향을 통해 스케줄러가 변경된 특성에 적합한 스케줄링 방법을 진행합니다.
예시를 통해 이해해보겠습니다.
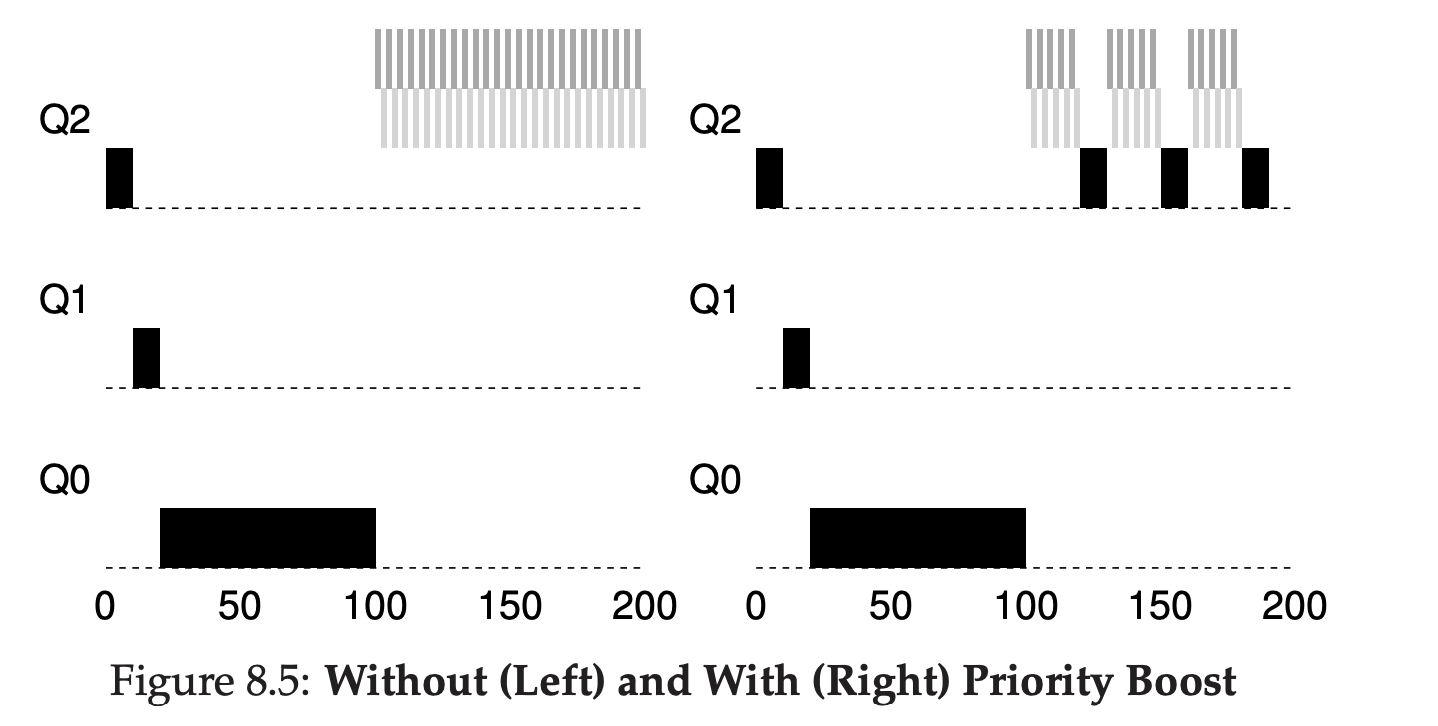
왼쪽은 Priority Boost를 적용하지 않은 스케줄러, 오른쪽은 적용한 스케줄러입니다.
왼쪽은 그림에서 볼 수 있듯이 검은색 작업이 다른 작업들에 의해, 100초 이후에 실행되지 않는 것을 볼 수 있습니다.
하지만 오른쪽 그림은 Priority Boost를 하였기에, 중간 중간 다시 최상위 큐로 올라와서 작업을 수행할 수 있습니다.
이제 여기서 몇 초마다 boost를 해줘야할지는 적절하게 선택해야합니다.
너무 길게 설정하면, 기아 상태의 지속시간이 비교적 짧아지는 것이고
짧게 설정하면 다른 대화형 작업이 적절한 양의 CPU를 사용할 수 없게 됩니다.
시도 3 : 더 나은 시간 측정
현재 규칙 4a와 4b에 의해 시간을 교묘하게 속이는 프로세스를 막을 방법이 없습니다.
이 방법을 해결하기 위한 해결책은 MLFQ의 각 단계에서 CPU 총 사용 시간을 측정하는 것입니다.
그 방법을 적용하여 새로운 규칙 4를 정하겠습니다.
규칙 4 : 주어진 단계에서 시간 할당량을 소진하면 ( CPU를 몇 번 양도하던 상관없이 ), 우선 순위는 낮아진다.
이것에 대한 예시를 보겠습니다.
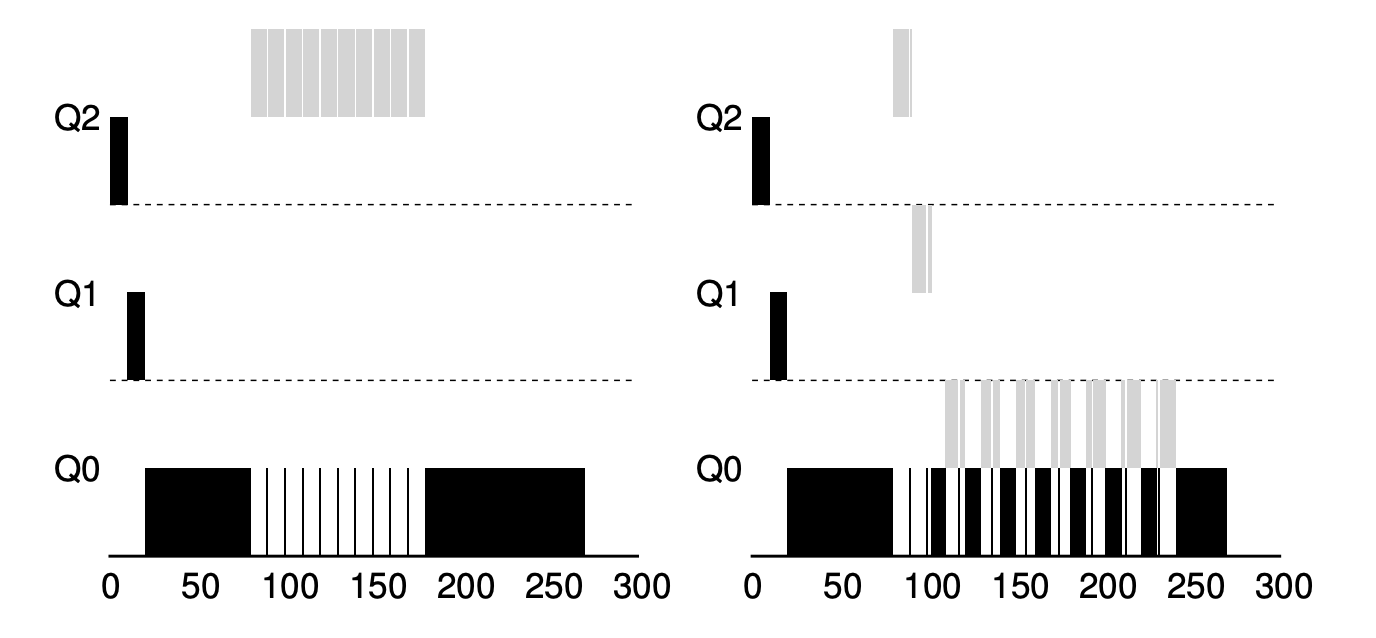
왼쪽은 규칙 4를 적용하지 않은 스케줄러, 오른쪽은 적용한 스케줄러입니다.
왼쪽 스케줄러는 계속 회색 작업이 높은 우선순위를 유지하며, 검은색 작업이 중간중간 짧게 실행될 수 밖에 없는 구조를 가져 결과적으로 반환시간이 늦어지게 됩니다.
하지만 오른쪽 스케줄러는 CPU의 반환과 상관없이, 타임 슬라이스를 소진하면 우선순위를 내리기 때문에 검은색 작업과 우선순위가 결국 같아지게 되며, RR과 같은 방식으로 작업을 진행하게 됩니다.
이렇게 아까 발생했던 문제를 모두 해결했습니다.
MLFQ 조정과 또 다른 쟁점들
이제 필요한 변수들을 스케줄러가 어떻게 정해야하는지도 중요한 문제입니다.
예를 들어, 몇 개의 큐가 존재해야하가?
타임 슬라이스의 크기는 얼마로 해야하는가?
boost는 얼마나 자주 일어나야하는가?
사실 이러한 질문에는 쉽게 대답할 수 없습니다.
워크로드에대해 충분히 경험하고, 계속 조정하며 균형점을 찾아야합니다.
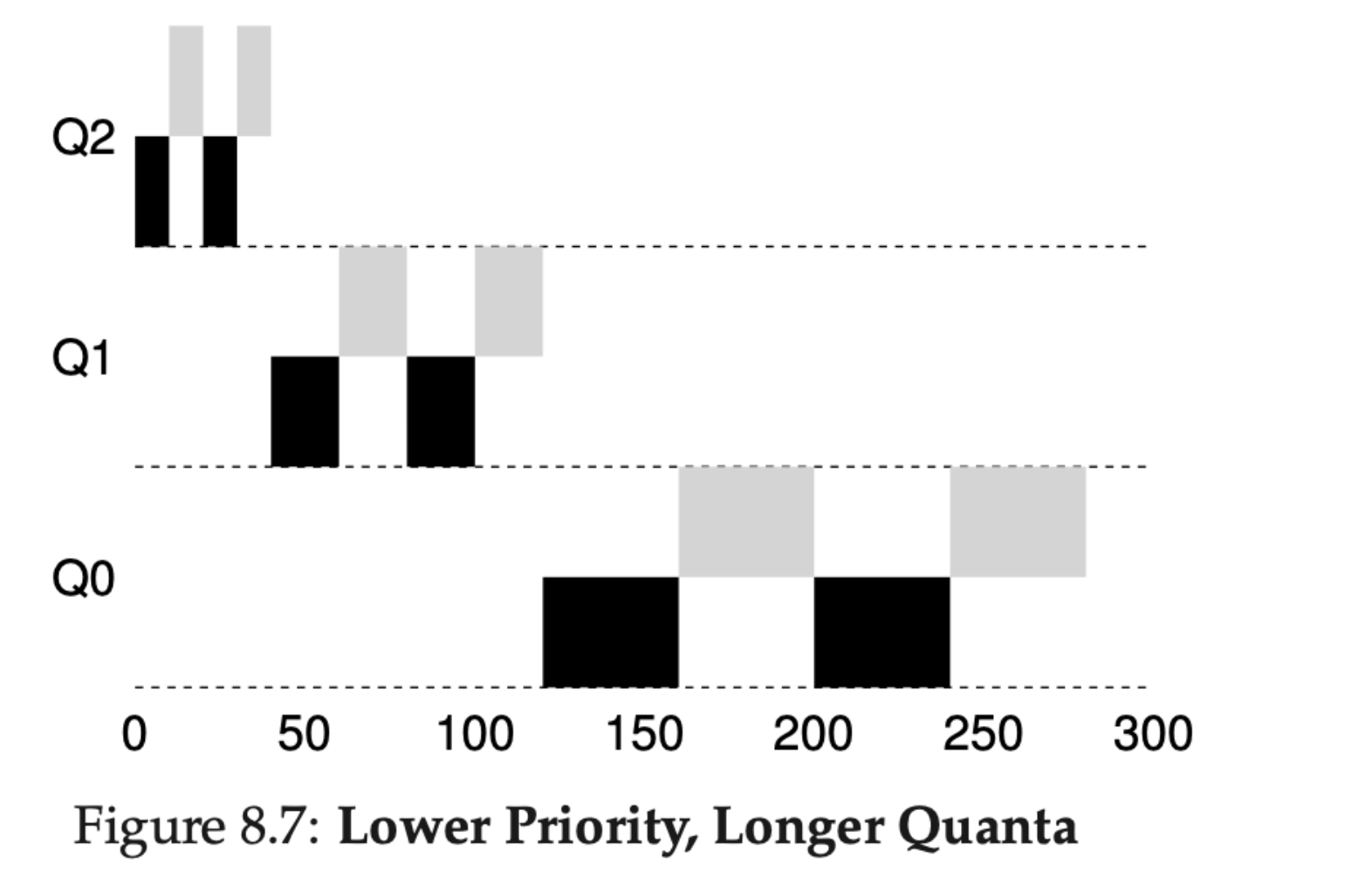
예를 들어, 실제 MLFQ는 큐 별로 타임슬라이스가 다릅니다.
우선 순위가 높은 큐는 상대적으로 짧은 슬라이스를 가지고 낮은 큐는 반대로 긴 타임 슬라이스를 가집니다.
높은 큐는 보편적으로 대화형 작업으로 이루어지기 때문에, 빠르게 교체하는 것은 의미가 있습니다.
반대로, 낮은 큐에 존재하는 작업들은 CPU 중심의 작업들이기 때문에 오래 실행되는 것은 의미가 있습니다.
마지막으로, 스케줄러는 다른 여러기능들을 제공합니다.
일부 스케줄러의 경우 가장 높은 우선순위를 OS 작업을 위해 예약해두는 경우가 있습니다.
일반적인 사용자들은 가장 높은 우선순위를 얻을 수 없게 되는 거죠.
요약
MLFQ가 왜 MLFQ인지 알아봤습니다.
-
멀티 레벨 큐를 가지고 있습니다.
-
작업의 우선순위를 정하기 위해 피드백을 사용합니다.
과거에 보여준 행동이 우선순위를 정하는 지침이 됩니다.
MLFQ의 규칙 요약
규칙 1 : 우선 순위가 높은 큐에 존재하는 프로세스들이 먼저 실행됩니다.
규칙 2: 작업들이 같은 우선 순위를 가진다면 RR을 사용하여 실행합니다.
규칙 3 : 작업이 시스템에 진입하면, 가장 높은 우선순위 즉 맨 위의 큐에 놓여진다.
규칙 4 : 주어진 단계에서 시간 할당량을 소진하면 ( CPU를 몇 번 양도하던 상관없이 ), 우선 순위는 낮아진다.
규칙 5 : 일정 기간 S가 지나면, 시스템의 모든 작업을 다시 최상위 큐로 이동시킵니다.
