물리 메모리 크기의 극복 : 정책
이번 포스트에서는 저번 포스트에서 알아본 디스크 스왑이 되었을 때, 페이지 교체 정책을 어떻게 효율적으로 정할 수 있는지에 대해 알아보겠습니다.
캐시 관리
시스템의 전체 페이들 중 일부분만이 메인 메모리에 유지된다는 것을 가정하면, 메인 메모리는 시스템의 가상 메모리 페이지를 가져다 놓기위한 캐시로 생각될 수 있습니다.
이 캐시를 위한 교체 정책의 목표는 캐시 미스를 최소화하는 것입니다.
즉, 디스크로부터 페이지를 가져오는 횟수를 최소로 만드는 것입니다.
이것은 다르게 말하면 캐시 히트의 횟수를 최대화하는 것입니다.
평균 메모리 접근 시간(Average Memory Access Time)은 캐시 히트와 미스의 횟수를 통해 계산할 수 있습니다.
여기서 T_M은 메모리 접근 비용을 나타내고, T_D는 디스크 접근 비용, P_miss는 캐시에서 데이터를 못찾을 확률을 뜻합니다.
예를 들어, 어떤 컴퓨터가 4KB(2^12)의 작은 메모리를 가지고 있고, 페이지의 크기는 256byte(2^8)라고 가정하겠습니다. 가상 주소는 4bit의 VPN을 가지고, 8bit의 Offset을 가지며, 한 프로세스는 16개의 가상 페이지에 접근하게 된다는 것을 알 수 있습니다.
프로세스는 가상주소 0x000, 0x100, ... , 0x900의 메모리를 가리키고 있습니다.
이 가상 주소들은 주소 공간의 첫 열 개 페이지들의 첫번째 byte를 나타냅니다.
또한, 가상 페이지 3을 제외한 모든 페이지가 이미 메모리에 있다고 가정하겠습니다.
주어진 순서의 메모리 참조는 다음과 같은 동작을 보일 것입니다.
히트, 히트, 히트, 미스, 히트, 히트, 히트, 히트, 히트, 히트
⇒ P_miss는 0.1이 될 것입니다. 반대로 히트율을 0.9일 것입니다.
AMAT를 계산하기 위해서는, 메모리를 접근하는 비용과 디스크를 접근하는 비용을 알아야합니다.
T_M을 약 10 nsec이라고 가정하고, T_D를 10ms 으로 가정하겠습니다.
이를 사용하여 AMAT를 계산하면 100ns + 1ms 약, 1ms가 된다는 것을 알 수 있습니다.
만약 히트율이 99.9%였다면, 결과는 10.1 microsec 거의 100배쯤 빨라지게됩니다.
히트율이 100%에 가까워질 수록 100nsec에 가까워짐을 알 수 있습니다.
이 예제를 통해 알 수 있듯이 디스크 접근비용음 엄청나게 크고, 이때문에 미스를 최대한 줄여야합니다.
최적 교체 정책
최적 교체 정책(The Optimal Repacement Policy)은 미스를 최소화하는 방법입니다.
가장 나중에 접근될 페이지를 교체하는 것이 최적이며, 가장 적은 횟수의 미스를 발생시킨다는 것이 증명되어있습니다.
가장 먼 시점에 접근하게 될 페이지보다 다른 페이지들이 먼저 참조될 것이니 나중에 접근하는 페이지는 중요하지 않다는 것입니다.
예제를 통해 알아보겠습니다.
프로그램이 0,1,2,0,1,3,0,3,1,2,1 의 순서대로 접근한다고 가정하겠습니다.
캐시에 3개의 페이지를 저장할 수 있다고 가정할 때 아래 그림은 최적 교체 정책의 동작을 보여줍니다.
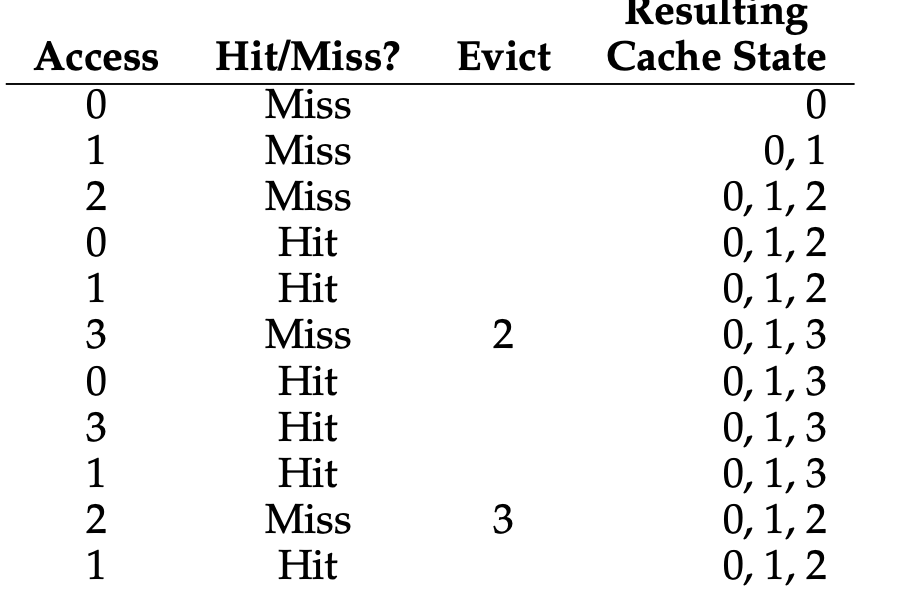
처음 0에 접근하게 될 때는 당연하게도 캐시에는 아무것도 없었기에 미스가 발생합니다.
최초 시작시 발생하는 미스는 최초 시작 미스 또는 강제 미스라고합니다.
이후 0과 1을 참조하게 되면 히트를 하게 됩니다.
3을 처음으로 만나게 되었을 때, 미스를 만나게 되었고 캐시가 가득 차 있어 교체 정책이 실행되어야합니다.
교체는 현재 탑재되어있는 페이지의 미래를 살펴봅니다.
그러면 0, 1, 2 중 가장 나중에 접근하게 되는 2가 최적 교체 정책에 의해 제거 될 것이고 3이 그 자리를 교체하게 됩니다.
이 예제에서 캐시의 히트율을 계산할 수 있습니다.
캐시 히트가 6번, 미스가 5번 있었으니 54.5% 이고 만약 강제 미스를 제외해서 계산하게 된다면 85.7%를 보여줍니다.
이 방법은 좋아 보일 수 있지만, 일반적으로 미래를 미리 알 수 없다는 것 떄문에 최적 기법의 구현은 사실상 불가능합니다.
최적 기법은 비교의 기준이 될 것이며, 다른 방법들은 얼마나 최적 기법의 결과와 가까운 결과를 보이는지 알아보겠습니다.
간단한 정책 : FIFO
FIFO는 당연하게도 선입 선출 교체 방식입니다.
먼저 들어온 페이지를 교체 시키는 방법입니다.
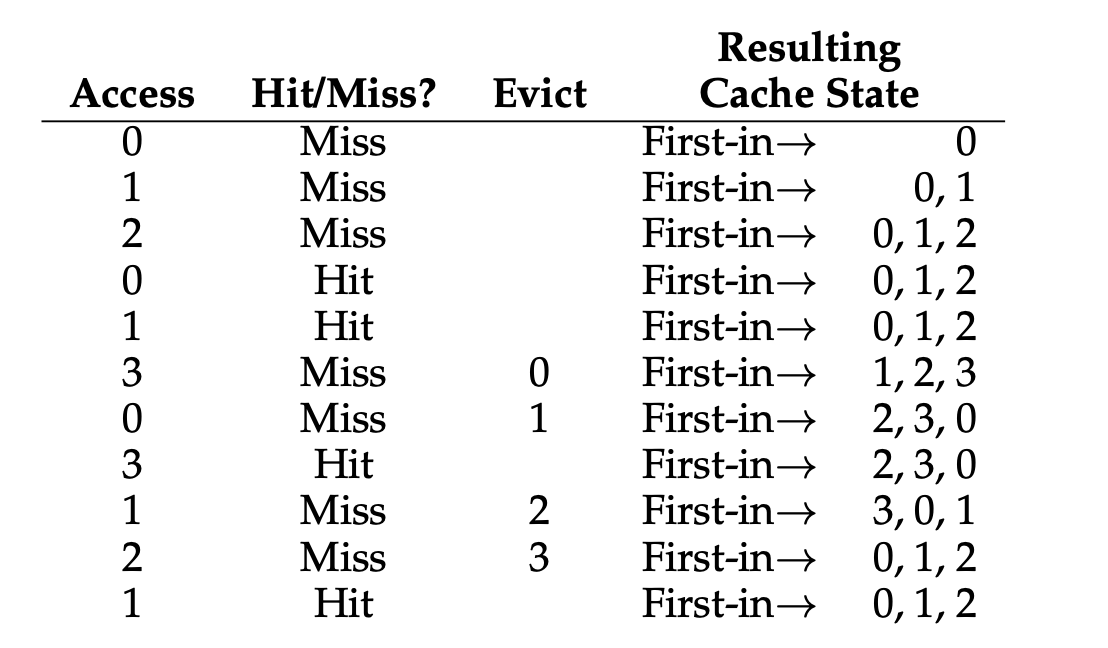
예제를 보면, 정말 선입으로 들어온 것들을 선출하는 것을 볼 수 있으며 이것을 통해 캐시 히트율을 계산해보겠습니다.
미스는 7번, 히트는 4번이므로 36.4%의 히트율을 보여줍니다.
강제 미스를 제외한다면 57.1%의 히트율을 보여줍니다.
최적의 경우와 비교하면 눈에 띄게 성능이 안좋습니다.
FIFO는 중요도를 판단할 수 없으며, 0이 여러번 접근한다해도 FIFO는 먼저 들어왔으니 교체의 대상으로 보게 될 뿐입니다.
또 다른 간단한 정책 : 무작위 선택
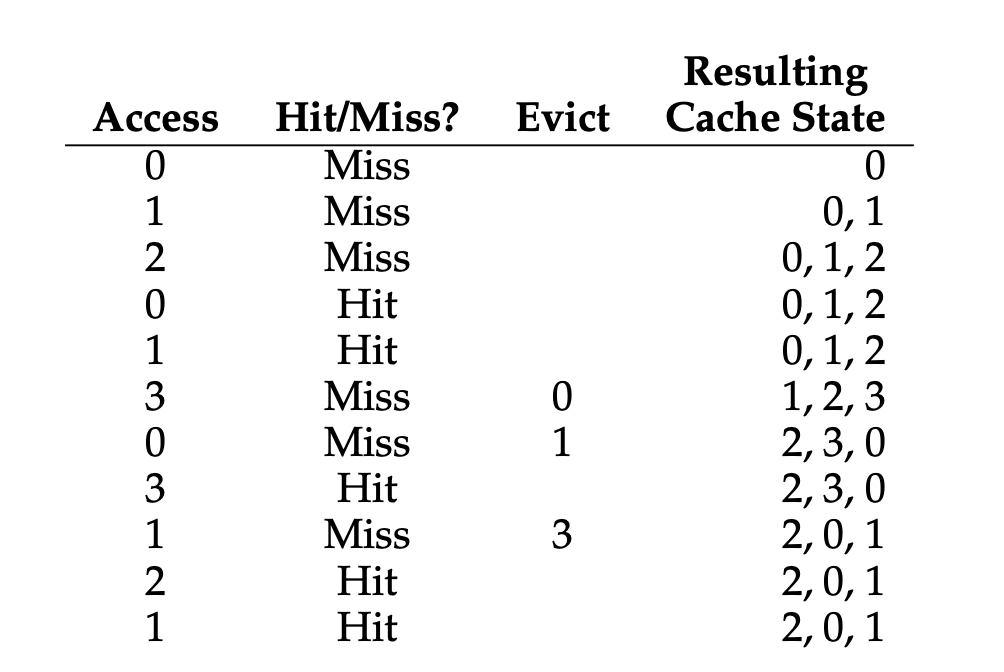
이번 방법은 무작위로 교체의 대상을 선택하는 방식입니다.
이 방식은 FIFO와 유사하게 중요도를 판단하지 않으며, 무작위 선택은 전적으로 운에 의존하게 됩니다.
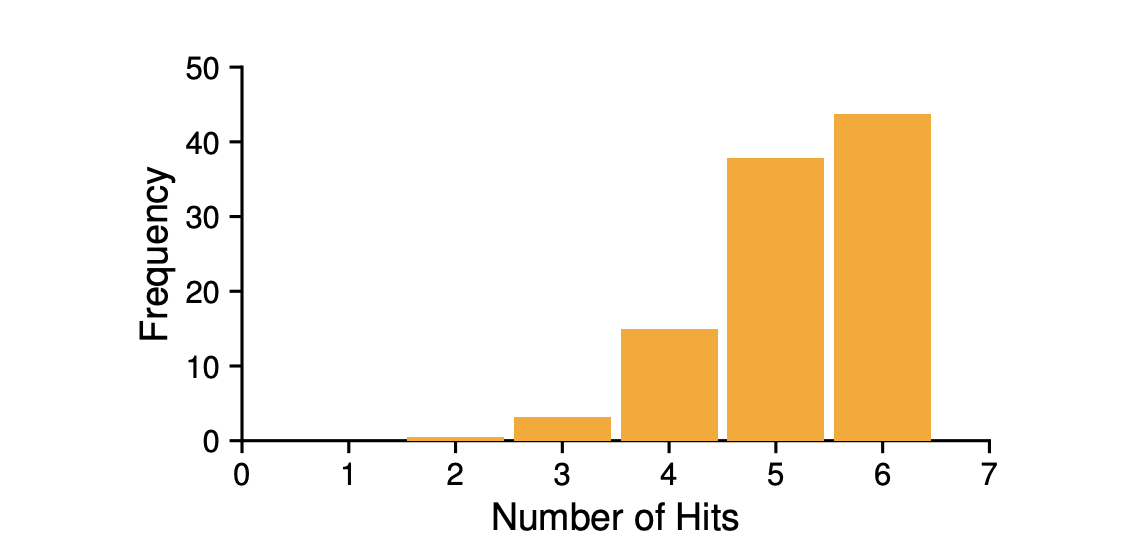
위 표는 1만번 실행했을 때 히트 수의 빈도를 나타냅니다.
어쩔 때는 좋은 성능을 나타내지만, 또 어쩔 때는 좋지않은 결과를 보여줍니다.
과거 정보의 사용 : LRU
위에서 알아본 두 개의 방식은 중요도를 판단하지 않기에 좋은 성능을 얻을 수 없습니다.
그렇기에 더 정교한 방식이 필요합니다.
스케쥴링 정책에서 미래에 대한 예측을 위해 과거의 이력을 활용했던 것 처럼 이번에도 과거의 정보를 사용하겠습니다.
페이지 교체 정책에서 활용할수 있는 정보 중 하나는 빈도수(frequency)입니다.
만약 한 페이지가 여러 차례 접근되었다면, 어떠한 중요도가 있기 때문에 교체되면 안될 것입니다.
좀 더 자주 사용되는 페이지의 특징은 접근의 최근성(recency) 입니다.
최근에 접근된 페이지일수록, 가까운 시일내에 다시 접근될 확률이 높기때문입니다.
이러한 류의 정책은 지역성의 원칙(principle of locality)라고 부르는 특성에 기반을 둡니다.
예를 들어 코드에서는 반복문이나 반복문에 의해 접근 되는 배열과 같은 알고리즘과 자료구조들이 빈번하게 사용되는 것 같은 이러한 원칙을 지역성의 원칙이라합니다.
이러한 원칙에 따라 LRU(Least Recently Used) 와 LRF(Least Frequently Used) 알고리즘이 개발되었습니다.
LRU를 이해하기 위해 예제를 보겠습니다.
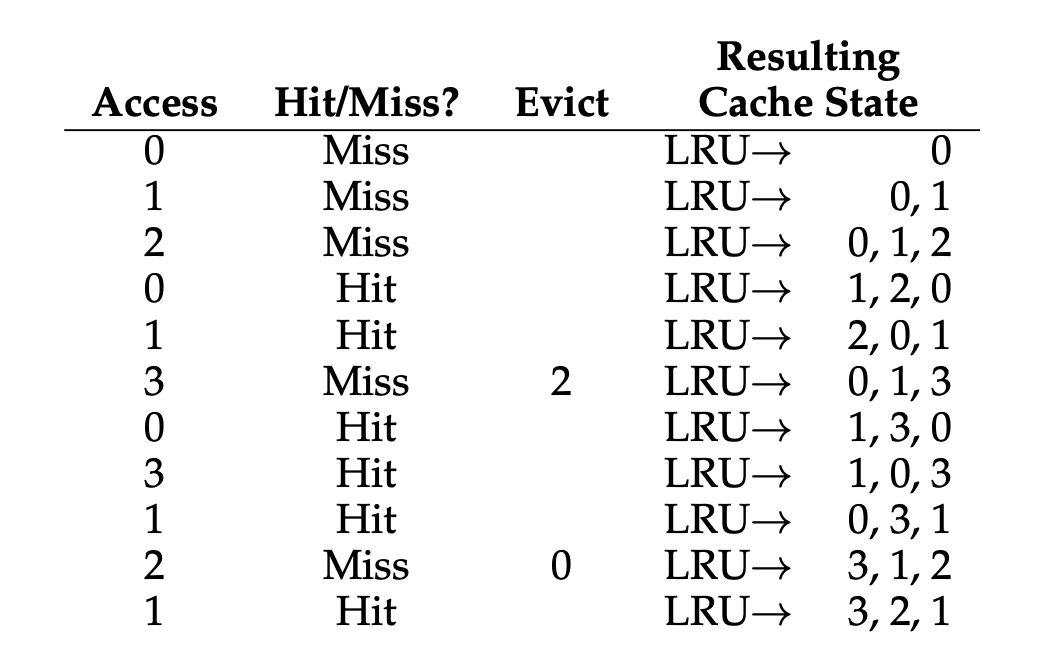
위 예시에서 LRU 정책은 처음 교체가 일어날 때 2를 내보내게 됩니다.
왜냐하면, 0과 1은 최근에 사용되었지만 2가 가장 예전에 사용되었기 때문입니다.
이러한 방식으로 작동한 결과를 통해 캐시 히트율을 계산하면 엄청나게 좋은 결과를 보여준다는 것을 알 수 있습니다. ( 54.5%, 강제 미스를 제외하면 85.7% )
이와 반대되는 Most Frequently Used, Most Recently Used와 같은 알고리즘도 존재하지만 대부분의 경우 이 두 알고리즘은 잘 작동하지 않습니다.
워크 로드에 따른 성능 비교
지금까지 알아본 정책을 잘 이해하기 위해 몇 가지 예제를 보겠습니다.
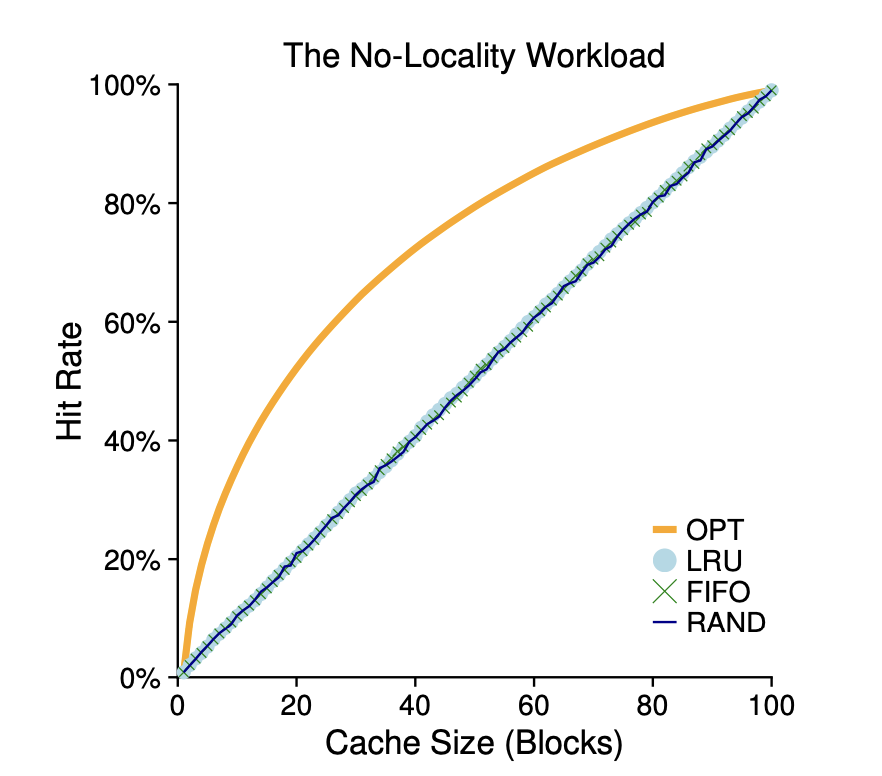
위 예제에는 지역성이 없습니다.
그 말은 접근되는 페이지들의 집합에서 페이지가 무작위적으로 참조된다는 것을 의미합니다.
위 예제를 통해 알 수 있는 것은, 워크로드에 지역성이 존재하지 않는 다면 어느 정책을 사용하던 상관이 없다는 것을 알 수 있습니다.
또한, 캐시가 충분히 커서 워크로드를 모두 포함할 수 있다면 어느 정책을 사용하던지 상관이 없어집니다.
마지막으로 최적기법은 그래도 좋은 결과를 보입니다. 미래를 알 수 있기 때문에 역시나 최적으로 동작합니다.
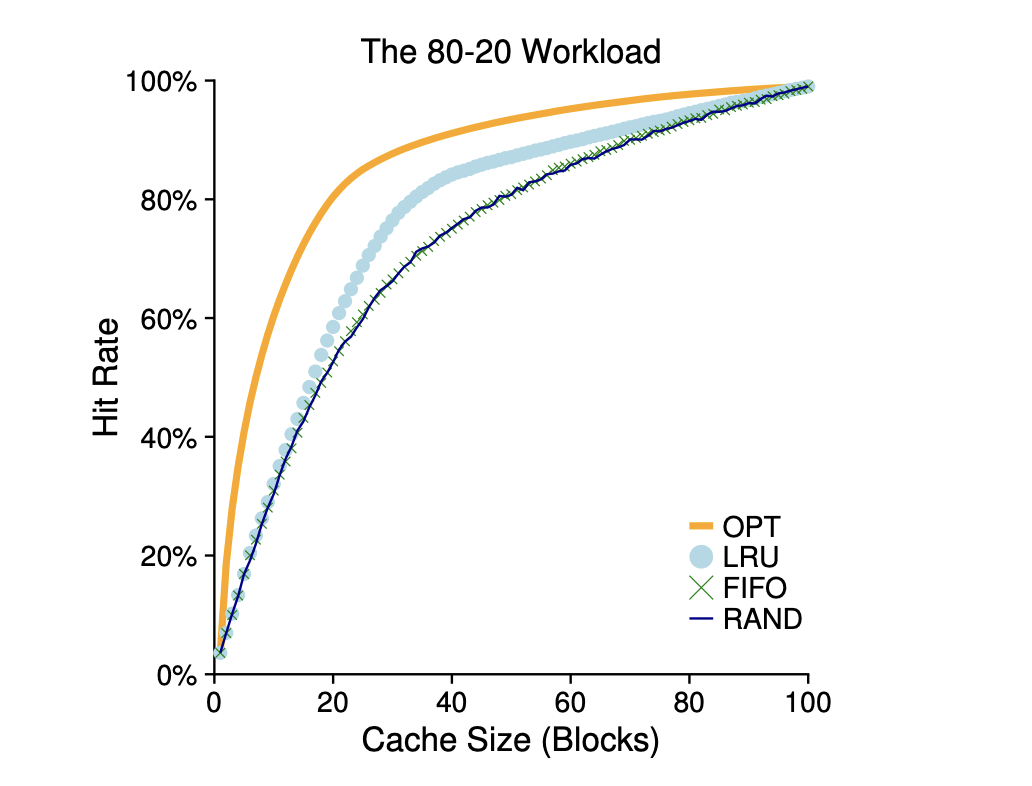
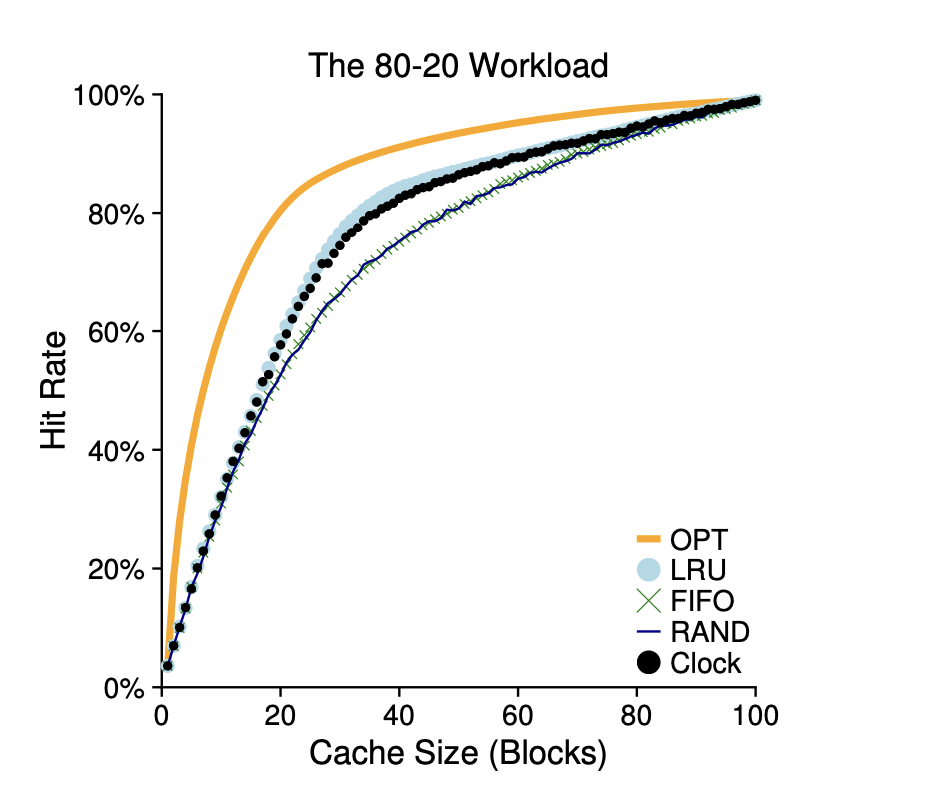
이 예제는 80대 20 워크로드라고 불리는 워크로드입니다.
20%의 인기있는 페이지에서 80%의 참조가 발생하고, 나머지 80%의 페이지들에 의해 20%의 참조가 일어납니다.
이 예제에서는 인기 있는 페이지들을 캐시에 더 오래두는 경향이 있는 LRU가 FIFO와 무작위 정책보다 좋은 성능을 보입니다.
최적 기법은 여전히 더 좋은 성능을 보여주며, LRU의 과거 정보는 완벽하지 않다는 것을 의미합니다.
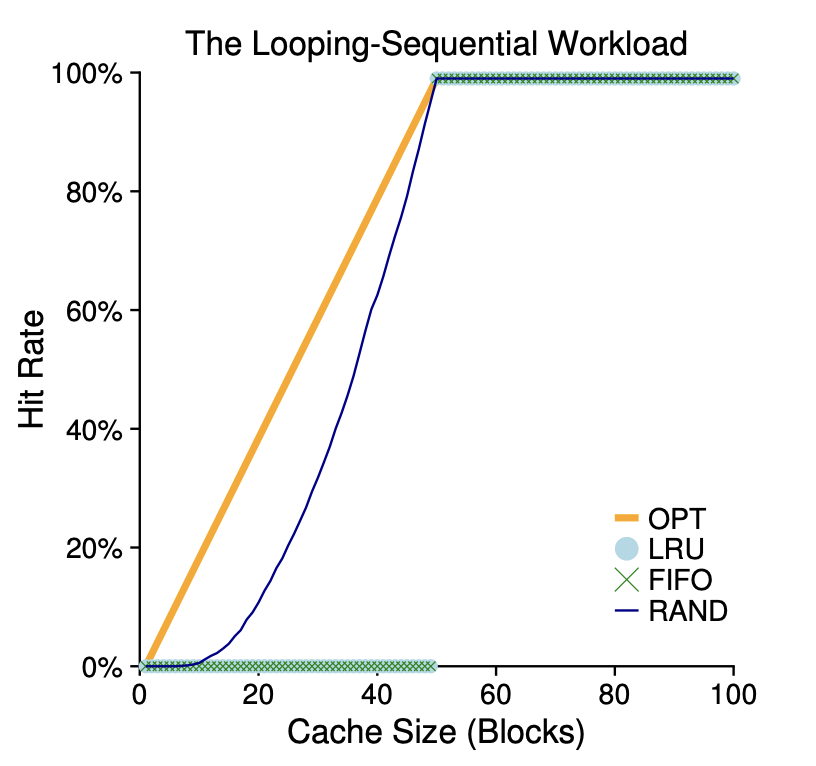
마지막으로 하나의 워크로드를 더 살펴보겠습니다.
이 워크로드는 50개의 페이지들을 순차적으로 참조합니다.
0~49번째의 페이지를 순차적으로 참조하고 0번째 페이지로 다시 돌아가서 반복합니다.
위 정책은 LRU와 FIFO에서 가장 안좋은 성능을 보여줍니다.
LRU와 FIFO는 오래된 페이지를 내보내기 때문입니다.
과거 이력 기반 알고리즘의 구현
여태까지 살펴본 것처럼 LRU는 좋은 결과를 보여줍니다.
하지만 과거 정보에 기반을 둔 정책은 문제가 있습니다.
이런 정책을 어떻게 구현하는지입니다.
LRU를 구현할 때 가장 중요한 것은 어떤 페이지를 교체할지 알아내는 것을 최소한의 비용으로 진행해야합니다.
이를 위해서 페이지에 접근할 때 해당 페이지를 목록의 맨 앞으로 이동시키는 것이 좋습니다.
즉, 가장 최근에 또는 가장 오래전에 사용되었는지를 관리하기 위해서입니다.
이를 위해서는 하드웨어의 지원이 필요한데, 페이지 수가 증가하게 되면 가장 오래전에 사용된 페이지를 찾는 것은 매우 큰 비용의 연산이 됩니다.
LRU 정책 근사하기
이러한 단점을 극복하기 위해 현재는 LRU를 근사하는 방식을 사용합니다.
이 개념에서는 use bit라고 하는 하드웨어의 지원이 필요합니다.
이 use bit는 시계 알고리즘(clock algorithms)을 이용하여 LRU를 구현합니다.
시스템의 모든 페이지들이 circular 리스트를 구성하고 시계 바늘이 특정 페이지를 가리킨다고 가정하겠습니다.
페이지를 교체해야할 때 운영체제는 현재 바늘이 가리키고 있는 페이지의 use bit가 1이라면 최근에 사용되었으니 교체 대상이 아니라고 판별합니다.
그 후 use bit는 0으로 설정되고 다음 페이지로 넘어가서 use bit가 0으로 설정되어 있는 페이지를 찾게됩니다.
최악의 경우 모든 페이지들을 탐색해야 할 수도 있습니다.
이 외에도 주기적으로 use bit를 지우고 교체 대상 페이지 선택을 위해 use bit가 1과 0인 페이지를 구분하는 방법이 있습니다.
위 예제는 변형된 시계 알고리즘을 사용합니다.
이 방식은 랜덤하게 페이지를 검사하고, use bit가 1인 페이지를 만나면 0으로 설정하고 use bit가 0인 대상을 만나면 교체 대상으로 선정합니다.
LRU보다 좋지느 않지만, 다른 기법들에 비해 좋은 성능을 보여줍니다.
갱신된 페이지(Dirty Page)를 고려하기
만약 어떤 페이지가 물리메모리에 탑재된 후 변경(modified) 되어 더티(dirty)상태가 되었다면, 그 페이지를 내보내기 위해서는 디스크에 변경 내용을 기록해야하기 때문에 비싼 비용을 지불해야합니다.
만약 변경되지 않은 페이지를 선택한다면, 더티 페이지에 비해 추가 비용없이 진행 할 수 있습니다.
이와 같은 동작을 지원하기 위해 modified bit 혹은 dirty bit를 하드웨어의 지원을 받아 추가적으로 사용할 수 있습니다.
다른 VM 정책들
페이지 교체 정책만이 VM 시스템에서 채택하는 유일한 정책은 아닙니다.
운영체제는 페이지를 언제 메모리로 불러들일지 결정해야합니다.
이 정책을 페이지 선택 정책(Page Selection Policy)라고합니다.
대부분의 페이지는 요구 페이징 정책(demand paging policy)에 의해 읽어들여집니다.
이 정책은 요청된 후 즉시 즉, 페이지가 실제로 접근될 때 해당 페이지를 메모리로 읽어들입니다.
운영체제는 어떤 페이지가 사용될 지 예측할 수 있기 때문에 선반입(prefetching)과 같은 동작도 합니다.
또 다른 정책은 변경된 페이지를 디스크에 반영하는 방식입니다.
클러스터링 혹은 그룹핑과 같은 방법을 통해 한번에 모은 후 디스크에 쓰는 방식을 주로 사용합니다.
쓰레싱(Thrashing)
만약 메모리 사용 요구량이 감당할 수 없을 만큼 크고 많은 실행중인 프로세스가 요구하는 메모리가 가용 물리 메모리를 초과하는 경우는 어떻게 할까요?
이런경우 시스템은 끊임없이 페이징을하게되고, 이와 같은 상호아을 쓰래싱이라고 부릅니다.
최신 시스템들은 메모리 요구과 초과되면 메모리 부족 킬러(out of memory killer)를 실행시켜, 많은 메모리를 요구하는 프로세스를 골라 죽여버리는 방식을 사용하기도 합니다.
하지만 이 방식은 메모리 부족은 해결하지만, 원하는 동작이 아닐 수 있기때문에 문제가 될 수 있습니다.
요약
이번 포스트는 여러 페이지 교체 정책과 다른 정책 그리고 쓰래싱을 알아봤습니다.
이번 포스트를 끝으로 가상화는 끝이 났습니다!
다음 포스트부터는 병행성에 대해 알아보겠습니다.
