Chapter3. 프로세스의 메모리 구조
많은 현대 프로그래밍 언어에서는 변수의 타입에 따라 변수가 위치할 메모리 섹션이 결정된다. 예를 들어 배열이나 객체는 힙영역에 내장 타입의 변수는 스택 영역에 할당한다는 규칙이 있을 수 있다. 따라서 프로그래머에게 선택권이 없으므로 고민할 부분도 없어 메모리 구조를 전혀 모른채로 프로그래밍을 하기도 한다.
그러나 C++에서는 변수를 선언하는 방법에 따라 변수가 위치하게 되는 메모리 섹션이 달라질 수 있으며, 그에 따라 성능 상의 유의미한 차이를 만들어내기도 한다. 따라서 C++ 프로그래밍을 한다면 프로세스 메모리의 구조를 어느정도는 이해해야할 필요가 있다.
프로그램은 실행하게 되면 OS로부터 가상메모리(보조기억장치에 파편화된 메모리 덤프들을 저장해두고 필요에 따라 주기억장치에 로드함으로써(페이징 기법) 실제 물리적 메모리 크기보다 더 큰 크기를 갖는 가상메모리를 구현함)를 할당받아 주어진 가상 메모리 내에서 돌아간다. 이렇게 실행중인 프로그램을 프로세스라고 하며 시스템마다 세부적으로 조금씩 다를 수 있지만 크게 보면 다음과 같은 구조를 가지고 있다.
1)
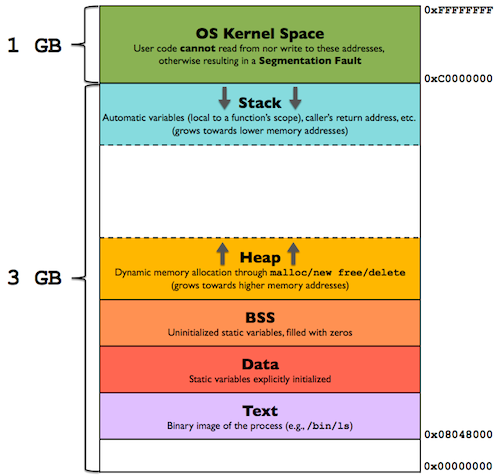
위 그림은 32bit 프로세스의 메모리 구조이다. 32bit 시스템에서는 메모리 주소가 32bit로 표현된다. 그리고 커널 메모리가 1~2G를 차지하기 때문에 실제로 유저 영역의 메모리 크기는 2~3G이다. 그림에 표현된 각 박스는 메모리 섹션 또는 세그멘트라고 불린다.
- 고정 크기 메모리 섹션
.text 섹션은 기계어 코드가 위치한 영역이며 cpu에서 이 코드들을 처리하면서 프로세스의 흐름이 제어된다. 기계어 코드들은 한번 빌드된 후에는 바뀌지 않기 때문에 .text 섹션의 크기는 불변이다.
.data 섹션과 .bss 섹션은 전역 변수가 위치하는 영역이다. 전역 변수는 프로세스와 라이프 사이클을 같이 하기 때문에 이들 역시 고정 크기의 섹션이다. .bss와 .data의 차이는 초기화 여부이다. 둘을 구분 하는 이유는 OS에서 zero-fill-on-demand라는 기술을 통해 bss를 관리하기 때문이다. 따라서 .bss 영역은 모두 0으로 초기화 되어있고, 초기화 하지 않은 전역변수는 모두 0인 상태로 시작하게 된다. 한편 .data 섹션은 프로세스 로딩 중 주어진 초기값으로 초기화된다.
heap 영역은 프로세스가 동작하는 도중에 동적으로 할당, 해제되는 메모리 섹션이다. 가용 메모리를 탐색하고 메모리의 파편화를 최소화하도록 관리하는 것은 OS의 역할인데, 가용 메모리를 탐색하는 것 자체가 오버헤드라고 할 수 있기 때문에 힙 메모리의 할당이 잦은 프로세스는 동작속도가 느려진다. 때문에 힙 영역 탐색에 대한 오버헤드를 줄이기 위해, 힙 메모리 해제가 필요한 상황에서 바로 해제하지 않고 동일한 객체 타입이 다시 필요한 상황에 재활용하기 위해서 별도의 풀을 만들어 관리하는것이 일반적이다. 이러한 최적화 기법을 오브젝트 풀링이라고 한다.
stack 영역은 함수의 지역 변수, 파라미터 등이 위치하는 메모리 섹션이다. 함수가 호출되면 해당 함수의 스택 프레임이 스택 영역에 쌓이게 되고 함수가 끝날 때 해당 스택 프레임이 자동으로 제거된다.
각 함수의 스택 프레임의 크기 크리고 프레임 내의 지역변수들 위치는 컴파일 타임에 결정된다. 즉, 컴파일 타임에 길이 정보가 결정되지 않은 배열 등을 지역변수로 선언하는 것은 비표준 구문이다. 일부 컴파일러는 이를 허용하는데 이를 위해 스택 프레임의 크길르 임의로 더 크게 잡는 등 메모리 관리 측면에서 낭비가 발생한다.
- 함수 문맥 전환
함수의 호출에서는 생각보다 많은 작업이 발생하게 된다. 먼저 함수의 파라미터를 스택에 push한다. 그리고 함수가 종료될 때 제어흐름을 다시 원래 제어 흐름으로 되돌릴 수 있도록 함수 종료후 EIP(명령어 레지스터)가 가리켜야할 주소(함수 호출 명령어 다음 명령어의 주소)를 스택에 push한다. 또한 함수 종료 후 원래 함수의 스택 프레임으로 되돌아와야 하므로 EBP(베이스 포인터; 함수의 지역변수나 파라미터 변수에 접근하기 위한 기준 주소)를 스택에 push한다.
그 다음 ESP(스택 포인터; 실행중인 스택 프레임의 top을 가리킴)를 EBP에 복사하여 새로운 함수의 스택 프레임 바닥을 만들어주고 함수 내의 모든 지역변수 크기 이상만큼 ESP를 감소시켜(스택은 베이스가 더 큰 주소, 탑이 더 작은 주소이므로) 스택 프레임을 만들어준다. 이후 함수가 종료되면 ESP를 증가시켜 해당 함수의 스택 프레임을 소멸시키고 미리 스택에 저장해둔 값들을 이용해 EBP와 EIP를 복구하고 스택에 저장되어있는 파라미터를 소멸시킨다.
이와 같이 함수 문맥 전환만으로도 어느정도 오버헤드가 발생하기 때문에 함수 몸체가 작은 함수들은 문맥 전환 없이 호출 구문에서 인라이닝되는 것이 좋다. C++ 컴파일러는 스스로 판단하여 인라이닝이 유리한 경우 자동으로 인라이닝을 시켜준다. 함수 정의시 inline이라는 키워드를 붙일 수 있는데 그렇다고 하더라도 인라이닝은 강제가 아니라 제안일 뿐이며 최종 판단은 컴파일러가 한다. 인라이닝 외에도 만약 재귀함수를 반복문으로 변경하기 수월하다면 반복문으로 바꿔주는 것으로 문맥 전환에 의한 오버헤드를 제거해 줄 수 있다.
1) "GABRIELE TOLOMEI", In-Memory Layout of a Program (Process), https://gabrieletolomei.wordpress.com/miscellanea/operating-systems/in-memory-layout/
