주의: 본 포스트는 저자가 학습하면서 작성한 글이므로 잘못된 내용이 있을 수 있습니다.
지적과 제언은 언제든지 환영입니다.
✏️ 들어서며
비슷하면서도 다른 배열과 연결 리스트
많은 언어가 배열과 연결 리스트를 언어 차원이나 언어 내장 라이브러리를 통해 지원하고 있습니다. 관계가 있는 데이터를 연속적으로 저장하는 차원에서 배열과 연결 리스트는 굉장히 유사하지만, 세부적인 구현엔 큰 차이가 있습니다.
배열은 연속적이고 고정된 메모리 공간을 할당받으며 자료형이나 크기를 변경하기 곤란하며 중간에 원소를 끼워넣기 힘든 대신 인덱스를 통한 무작위 탐색에 큰 강점을 보입니다.
반면 연결 리스트는 원소의 삽입과 삭제가 잦은 환경에 강하지만 탐색에 약합니다.
왜 그런지 연결 리스트를 살펴보면서 이해해봅시다.
🖇 연결 리스트는 무엇?
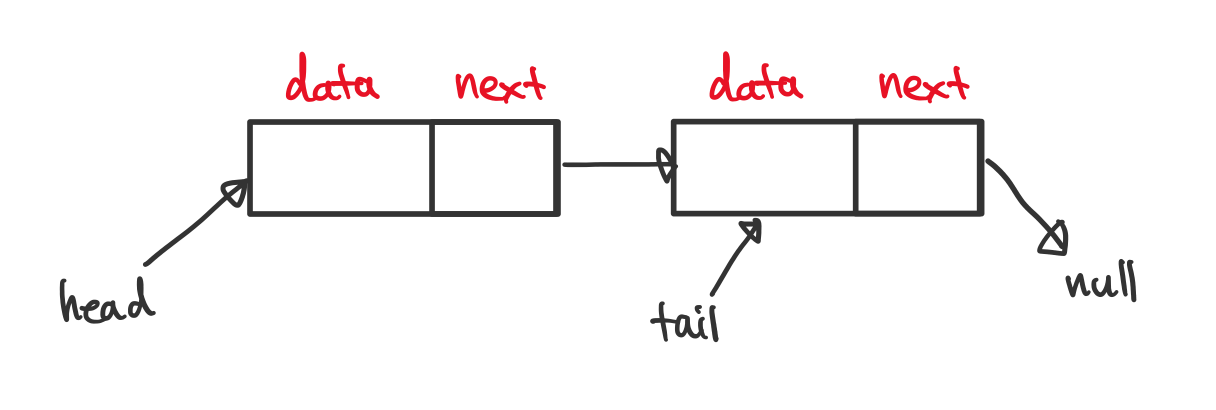
연결 리스트는 각 노드가 데이터와 주소를 가지고 서로 연결되어 있는 자료 구조입니다. 노드는 각자의 고유한 데이터와 다음 노드의 정보를 갖게 됩니다.
일부 연결 리스트는 head 와 tail 이라는 특별한 정보를 갖고 있기도 합니다.
head 와 tail 은 각각 첫 노드와 마지막 노드의 주소 정보를 저장합니다.
연결 리스트는 각 노드의 링크가 어떻게 구성되어 있냐에 따라
- 단일 연결 리스트 (singly linked list)
- 이중 연결 리스트 (doubly linked list)
- 다중 연결 리스트 (multiply linked list)
- 원형 연결 리스트 (circular linked list)
로 나뉘며 여기에서는 다중 연결 리스트를 제외한 나머지를 다루겠습니다.
단일 연결 리스트
단일 연결 리스트는 다음 노드로 향하는 링크 하나만을 갖는 연결 리스트입니다.
첫 노드(head)로부터 일렬로 늘어선 구조이므로 첫 노드의 주소 정보가 필요합니다.
연결 리스트 중 가장 쉽게 구현할 수 있지만 노드가 유실되면 해당 노드의 뒤쪽은 모두 사용할 수 없게 되는 단점이 있습니다.
검색
노드를 하나하나 따라가면서 검색합니다.
head 노드로부터 data를 확인하고, 아니면 next에 표시된 다음 노드의 data를 순차적으로 확인합니다.
시간 복잡도는 최선의 경우 O(1) , 최악의 경우 모든 노드를 탐색해야 하므로 O(n) 입니다. (tail 노드 정보를 가지고 있는 경우 n-1의 시간이 걸림)
삽입
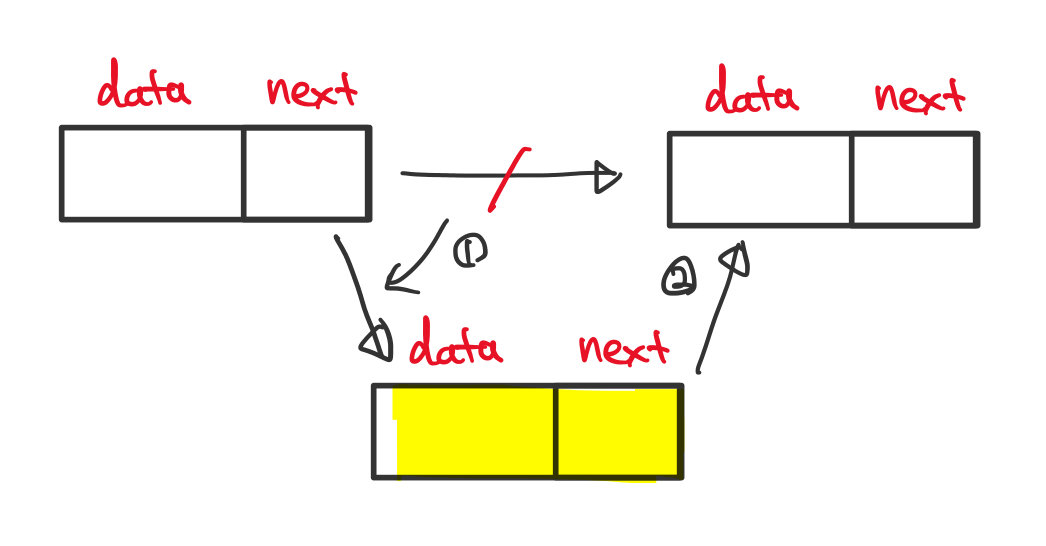
검색과 마찬가지로 삽입할 위치까지 하나하나 따라간 다음 새로운 노드를 생성하고 주소 정보를 바꿉니다.
시간 복잡도는 최선의 경우 첫 노드로 삽입하는 경우이므로 O(1) , 최악의 경우 O(n) 입니다. (tail 노드 정보를 갖고 있는 경우)
삭제
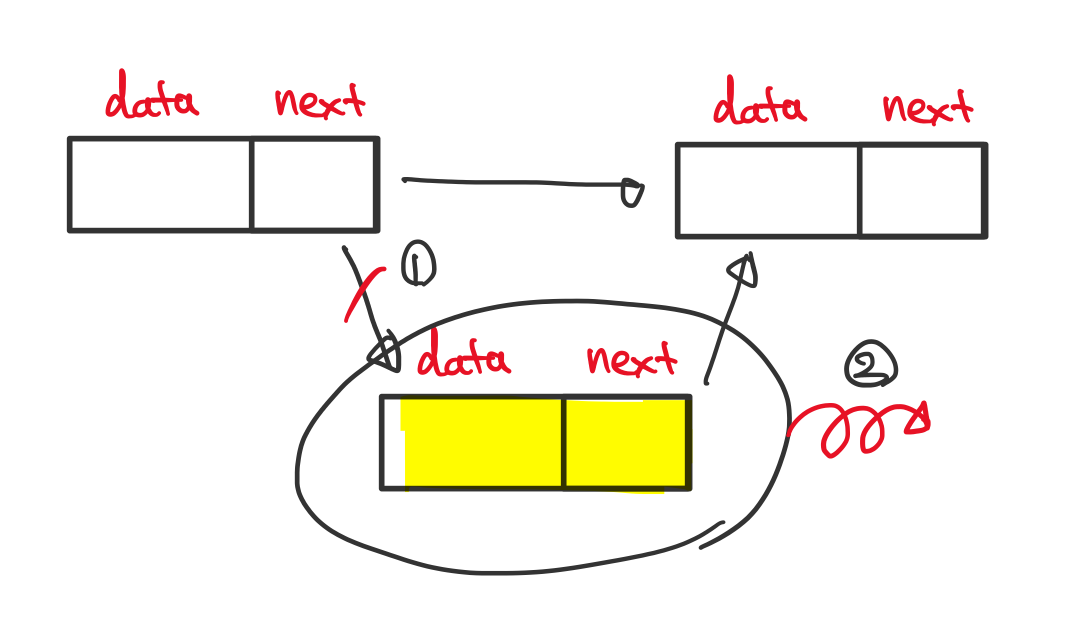
검색, 삽입과 마찬가지로 삽입할 위치까지 따라간 다음 이전 노드의 next를 삭제할 노드의 next로 변경한 뒤 삭제할 노드의 메모리를 해제합니다.
시간 복잡도는 최선의 경우 첫 노드로 삽입하는 경우이므로 O(1) , 최악의 경우 O(n) 입니다. (tail 노드 정보를 갖고 있는 경우)
원형 단일 연결 리스트
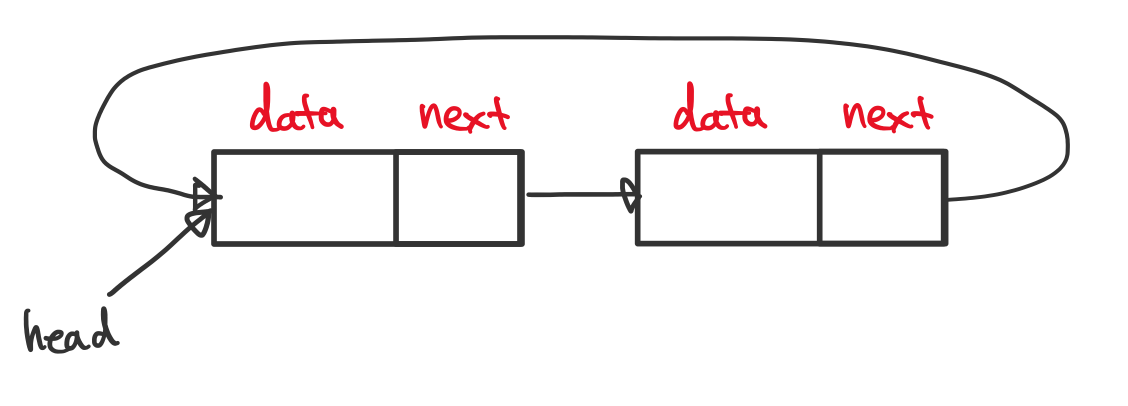
단일 연결 리스트와 크게 다르지 않으나, 마지막 노드의 next가 첫 노드를 가리켜 순환하도록 구성된 것이 특징입니다.
마지막 노드의 next를 설정해 주어야 하는 것 이외에는 단일 연결 리스트와 동일합니다.
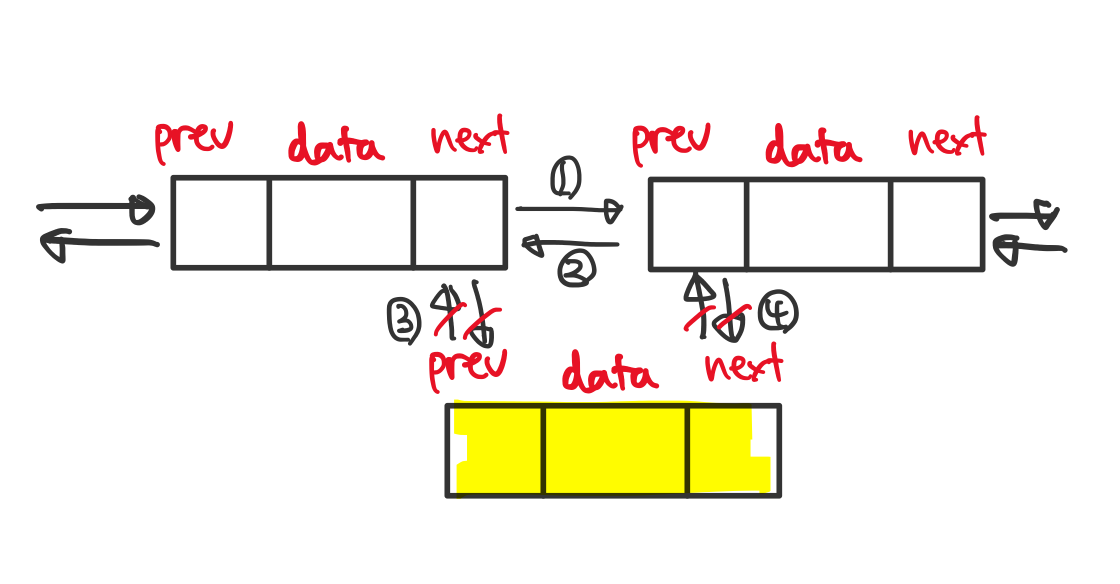
이중 연결 리스트
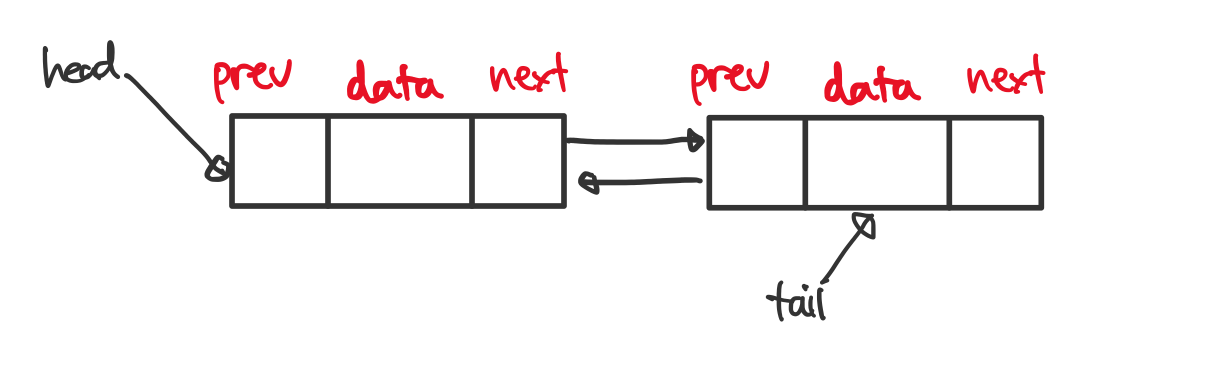
단일 연결 리스트와 다르게 각 노드가 이전 노드도 가리키는 것이 특징입니다.
노드의 유실 방지 대책을 세워 놓은 경우 단일 연결 리스트보다 노드 유실과 같은 돌발 상황에 대처하기 좋습니다.
검색
단일 연결 리스트와 같이 노드를 하나하나 따라가면서 검색합니다.
시간 복잡도는 최선의 경우 O(1) , 최악의 경우 모든 노드를 탐색해야 하므로 O(n) 입니다. (tail 노드 정보를 가지고 있는 경우 n-1의 시간이 걸림)
삽입
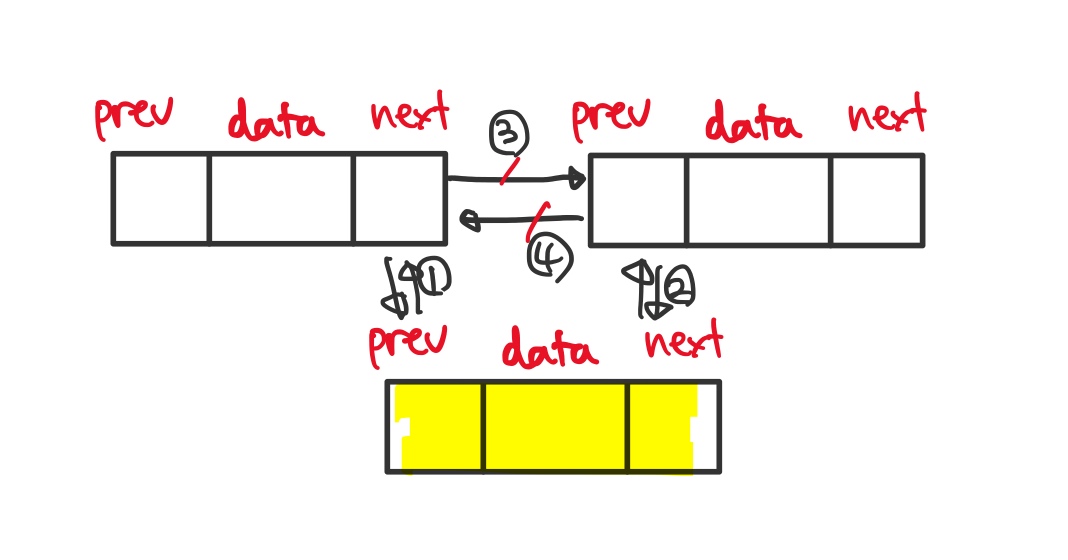
검색과 마찬가지로 삽입할 위치까지 하나하나 따라간 다음 새로운 노드를 생성하고 주소 정보를 바꿉니다.
시간 복잡도는 최선의 경우 첫 노드 또는 마지막 노드로 삽입하는 경우이므로 O(1) , 최악의 경우 O(n) 입니다. (거꾸로 따라갈 수도 있으므로 소요 시간 n/2+1)
삭제
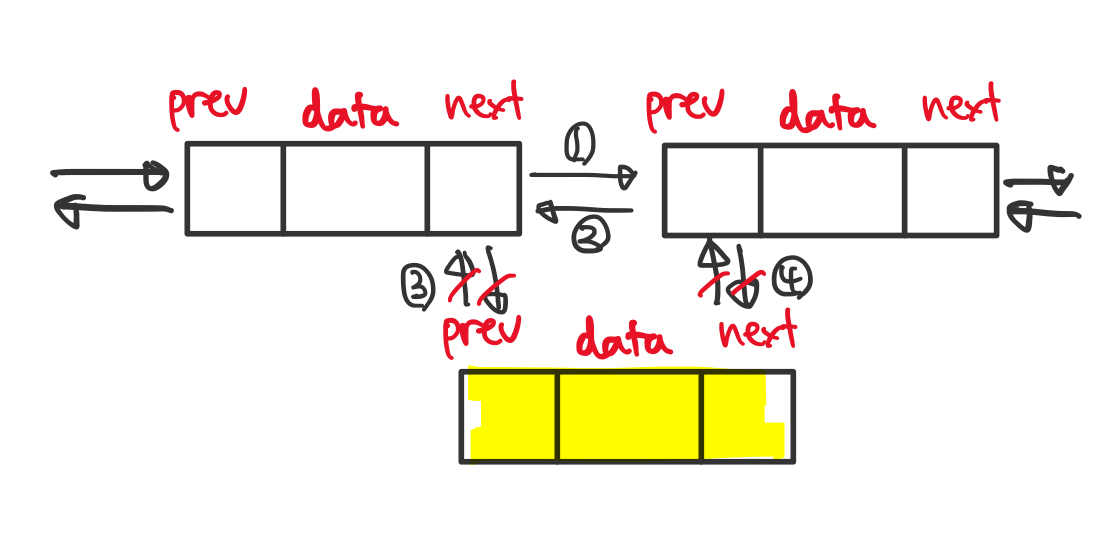
검색, 삽입과 마찬가지로 삽입할 위치까지 따라간 다음 이전 노드의 next를 삭제할 노드의 next로 변경한 뒤 삭제할 노드의 메모리를 해제합니다.
시간 복잡도는 최선의 경우 첫 노드 또는 마지막 노드로 삭제하는 경우이므로 O(1) , 최악의 경우 O(n) 입니다. (거꾸로 따라갈 수도 있으므로 소요 시간 n/2+1)
원형 이중 연결 리스트
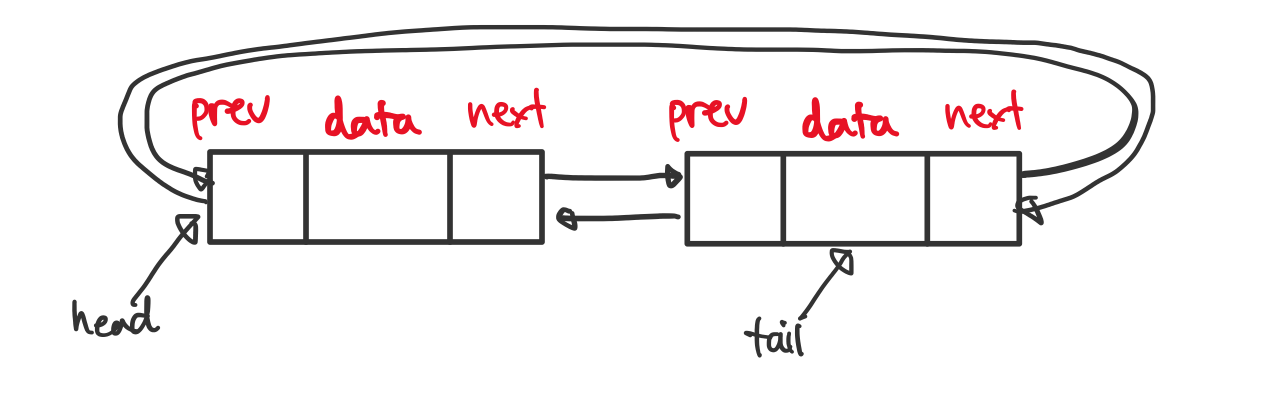
이중 연결 리스트와 크게 다르지 않으나, 첫 노드와 마지막 노드가 서로를 가리켜 순환하도록 구성된 것이 특징입니다.
마지막 노드의 next와 처음 노드의 prev를 설정해 주어야 하는 것 이외에는 단일 연결 리스트와 동일합니다.
✍️ 연결 리스트의 구현
단일 연결 리스트와 이중 연결 리스트를 구현하였습니다. 구현 언어는 C입니다.
단일 연결 리스트
- 리스트 노드 구조체 및 head 노드 정보
typedef struct _node {
int data;
struct _node *next;
} node;
node *head = NULL;- 삽입
void insert_node(int i, int pos) {
// 노드 동적 할당
node *new_node = (node *) malloc(sizeof(node));
new_node -> data = i;
new_node -> next = NULL;
if (head == NULL) {
head = new_node;
} else {
if (pos == 0) {
new_node -> next = head;
head = new_node;
} else {
// 삽입될 노드의 이전 노드 지정
node *prev = head;
// 삽입될 이전 위치의 주소 정보를 가져옴
for (int i = 0; i < pos - 1; i++) {
prev = prev -> next;
if (prev == NULL)
return; // 삽입할 수 없는 위치임
}
// 새로은 노드로 삽입
new_node -> next = prev -> next;
prev -> next = new_node;
}
}
}- 삭제
void delete_node(int pos) {
// 처음 노드를 삭제하는 경우
if (pos == 0) {
if (head == NULL)
return; // 노드 없음
node *target = head;
// 첫 노드의 다음 노드가 없을 때 (노드가 하나 뿐)
if (target -> next == NULL)
head = NULL;
else
head = target -> next;
free(target);
} else {
node *target_prev = head;
for (int i = 0; i < pos - 1; i++) {
target_prev = target_prev -> next;
if (target_prev == NULL || target_prev -> next == NULL)
return; // 리스트 범위를 벗어난 입력 값
}
node *target = target_prev -> next;
target_prev -> next = target -> next;
free(target);
}
}이중 연결 리스트
- 리스트 노드 구조체 및 head, tail 노드 정보
typedef struct _node {
int data;
struct _node *next;
struct _node *prev;
} node;
node *head = NULL;
node *tail = NULL;- 삽입
void insert_node(int i, int pos) {
// 노드 동적 할당
node *new_node = (node *) malloc(sizeof(node));
new_node -> data = i;
new_node -> prev = NULL;
new_node -> next = NULL;
// 리스트가 비어 있을 때
if (head == NULL) {
head = new_node;
tail = new_node;
} else {
if (pos == 0) {
// 기존 head와 새로운 노드(head)를 연결하고 head 변경
head -> prev = new_node;
new_node -> next = head;
head = new_node;
} else {
// 삽입될 노드의 이전 노드 지정
node *new_prev = head;
// 삽입될 이전 위치의 주소 정보를 가져옴
for (int i = 0; i < pos - 1; i++) {
new_prev = new_prev -> next;
if (new_prev == NULL)
return; // 삽입할 수 없는 위치
}
// 새로운 노드로 삽입
new_node -> next = new_prev -> next;
new_prev -> next = new_node;
new_node -> prev = new_prev;
// 마지막 노드이면 tail로 설정, 아니면 이전 노드 정보 연결
if (new_node -> next == NULL)
tail = new_node;
else
new_node -> next -> prev = new_node;
}
}
}- 삭제
void delete_node(int pos) {
// 처음 노드를 삭제하는 경우
if (pos == 0) {
if (head == NULL)
return; // 노드 없음
node *target = head;
// 첫 노드의 다음 노드가 없을 때 (노드가 하나 뿐)
if (target -> next == NULL) {
head = NULL;
tail = NULL;
} else {
head = target -> next;
target -> next -> prev = NULL;
// 노드가 더 없으면 tail과 head의 주소는 같음
if (head -> next == NULL)
tail = head;
}
free(target);
} else {
node *target_prev = head;
for (int i = 0; i < pos - 1; i++) {
target_prev = target_prev -> next;
if (target_prev == NULL || target_prev -> next == NULL)
return;
}
node *target = target_prev -> next;
if (target -> next == NULL) {
tail = target_prev;
} else {
target -> next -> prev = target_prev;
}
target_prev -> next = target -> next;
free(target);
}
}🧹 마치며
연결 리스트는 크기가 가변적이고 삽입과 삭제 연산이 간단해 배열보다 유리한 점이 많지만, 잦은 탐색에 취약한 모습을 보입니다.
이러한 연결 리스트의 약점을 보완해줄 수 있는 다른 자료구조가 다수 있는데, 이는 추후에 다뤄 보도록 하겠습니다.
