
Crawling
- 웹사이트에 있는 데이터를 사용하기 위해 홈페이지 내용을 수집하고 추출하는 것
- http 요청을 보내고 응답으로 받은 페이지를 분석해 필요한 데이터만 추출
cheerio,Puppeteer,Selenium,BeautifulSoup등의 라이브러리를 사용해서 크롤링 가능- 검색 엔진에 사용 - 웹 크롤러가 수집한 데이터에 검색 알고리즘을 적용해 사용자의 검색에 대한 응답으로 관련 링크를 제공
1. 대상 선정
- 웹 상의 고유한 ID인
URI가 존재 → 보통URL
URI
- 특정 리소스를 식별하는 통합 자원 식별자(Uniform Resource Idenrifier)
- 논리적 또는 물리적 리소스를 식별하는 고유한 문자열 시퀀스
URL
- 웹 주소로 컴퓨터 네트워크 상에서 리소스가 어디에 있는지 알려주기 위한 규약
-URI의 서브셋
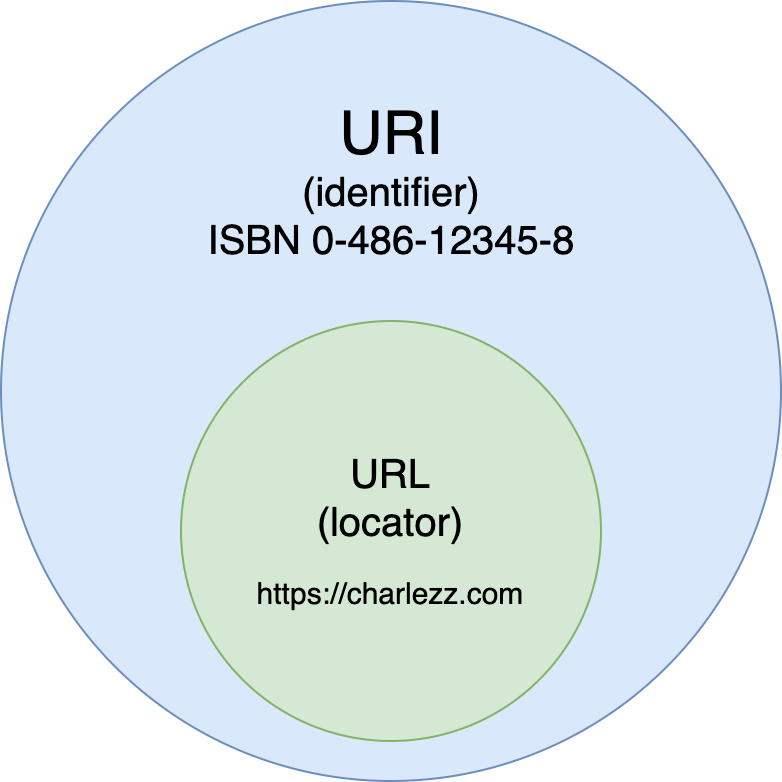 → URI는 식별하고 URL은 위치를 가리킨다
→ URI는 식별하고 URL은 위치를 가리킨다
2. 데이터 로드
- API인 경우
XML,JSON형식의 데이터 - 웹 페이지인 경우
HTML형식의 데이터
3. 데이터 분석
- 로드된 데이터에서 필요한 부분을 뽑아낸다
- 필요한 부분은 수집하고, 필요하지 않은 부분은 수집하지 않도록 선정
4. 수집
- 데이터 분석을 통해 수집할 내용을 선정한 후 데이터를 추출해 메모리 상에 저장
Cache
- 자주 사용하는 데이터나 값을 저장해놓는 임시 장소로 계산이나 접근 시간을 줄이기 위한 저장소
- 공간이 부족할 경우 우선순위가 낮은 데이터를 교체
Cache Hit: 참조하고자 하는 데이터가 캐시에 존재하는 경우Cache Miss: 참조하고자 하는 데이터가 캐시에 존재하지 않는 경우comlulsory miss: 해당 메모리 주소가 처음 요청되어 발생하는 missconflict miss: A와 B가 같은 캐시 메모리 주소에 할당되어 발생하는 miss, 캐시 공간이 남는데도 주소 할당으로 발생하는 misscapacity miss: 메모리 공간이 부족해서 나는 miss
캐시 배치 정책
Directed Mapped Cache
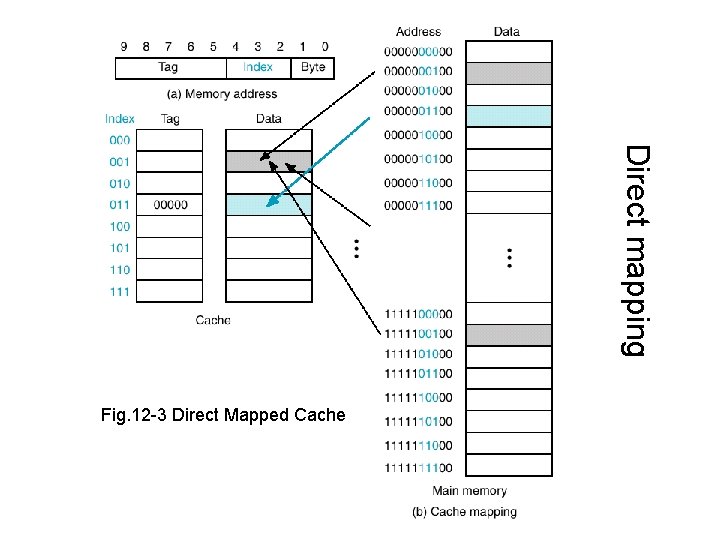
- 가장 기본적인 캐시 배치 정책으로 DRAM의 여러 주소가 캐시 메모리의 한 주소에 대응되는 N:1 방식
- 예시 그림에서는 캐시 메모리 하나 당 DRAM 4개의 주소에 대응
- 앞부분 일부는
Tag Field, 끝부분 일부는Index Field Index Field를 사용해 캐시 메모리 주소에서 데이터 참조
→Conflict miss발생 가능
Fully Associative Cache
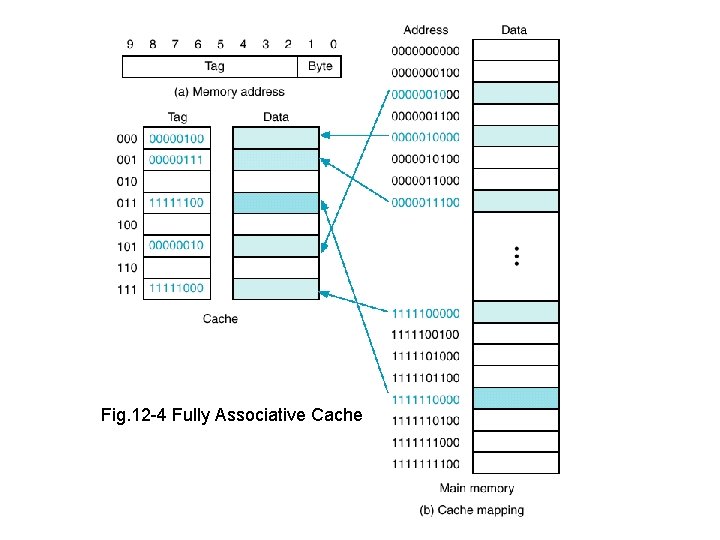
- 캐시 메모리 주소 중 비어있는 곳에 데이터 할당
→ 저장이 간단하고Conflict miss가 발생하지 않지만 원하는 데이터를 찾기까지tag bit를 일일이 비교해야하기 때문에 시간이 오래 걸릴 수 있다
Set Associative Cache
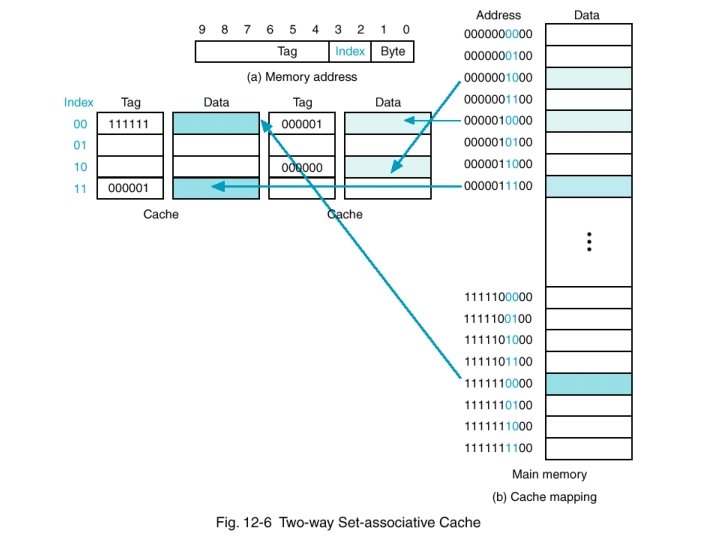
Directed Mapping+Fully Associative Mapping- cache의 몇 개의 block을 묶어 하나의
set으로 구성 → cache는 여러 개의 set으로 구성 - 하나의 set이 2개의 block으로 이루어져 있으면
2-way set associative cache, 하나의 set이 3개의 block으로 이루어져 있으면3-way set associative cache
→ Direct Mapping보다 검색은 느리지만 저장이 빠르고, Fully Associative Mapping보다 저장은 느리지만 검색이 빠르다
캐시 쓰기 정책
언제 메인 메모리의 값을 변경할 것인가에 대한 정책
캐시 Hit 시 쓰기 정책
Write Through
- 쓰기 동작 시 주 기억장치와 캐시의 메모리 값을 동시에 변경
→ 구조가 단순하고 일관성이 있지만 항상 메인 메모리에 접근하기 때문에 속도 문제
Write Back
- 캐시에서만 메모리 값을 변경하고 해당 주소의 데이터가 바뀔 때만 메인 메모리에 복사
→ 속도가 빠르지만 일관성 문제
캐시 Miss 시 쓰기 정책
Write-Allocate
- 캐시 Miss 발생 시 캐시에만 기록
No Write-Allocate
- 캐시 Miss 발생 시 메모리에만 기록
캐시 교체 정책
FIFO(First In First Out)
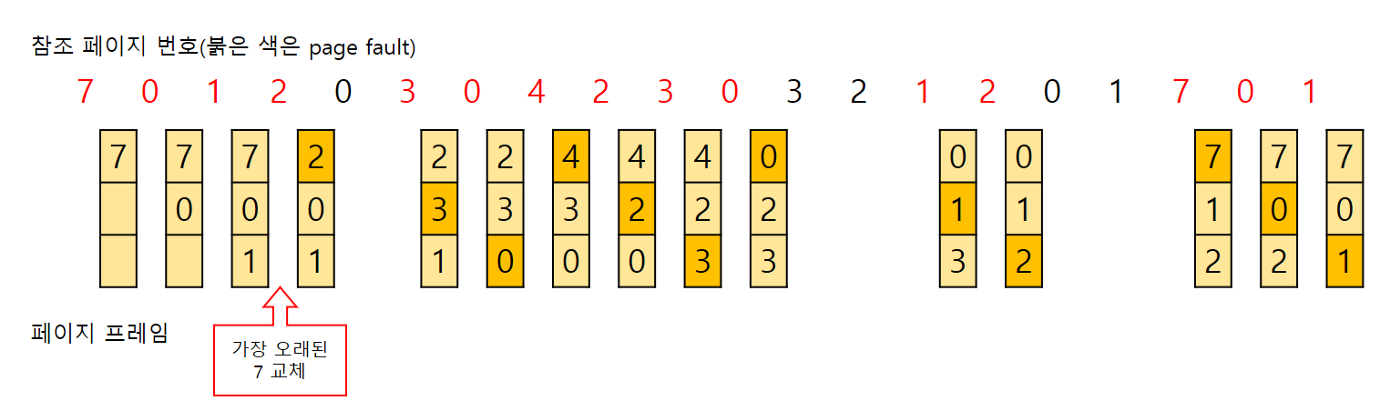
- 캐시 공간이 모자란 경우 처음 캐시에 올라온 데이터를 교체
→ 잦은 교체 문제
LRU(Least Recently Used)
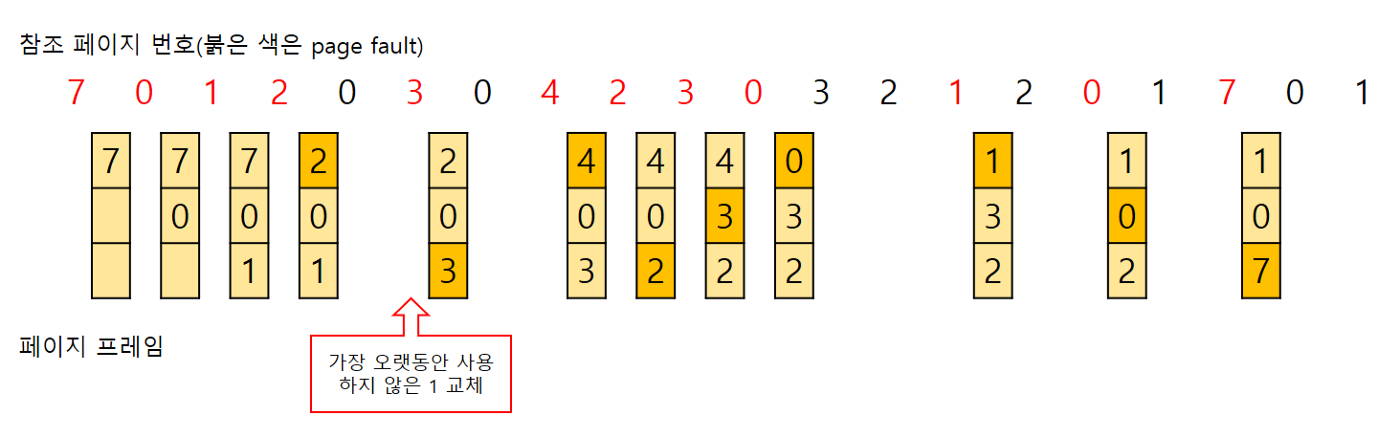
- 캐시 공간이 모자란 경우 가장 오래동안 사용하지 않은 데이터를 교체
- 자리가 없는 경우 가장 앞에 위치한 데이터를 삭제하고 새로운 데이터를 뒷부분에 입력
- 주로
Double Linked List를 사용해 head에 가까울수록 오래된 데이터, tail에 가까울수록 최근에 사용된 데이터 → 시간복잡도가O(1)
LFU(Least Frequently Used)
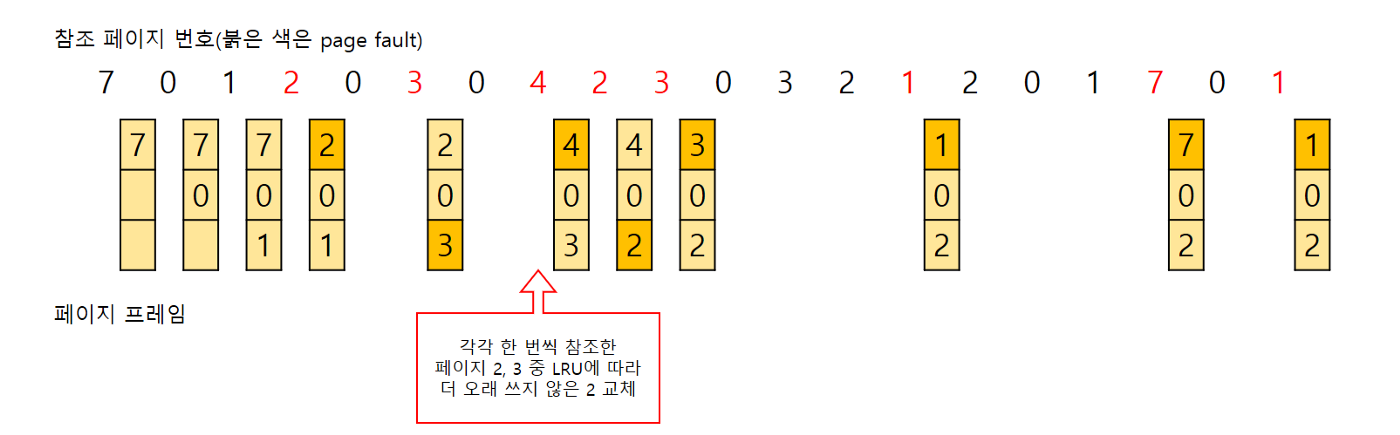
- 캐시 공간이 모자란 경우 사용 횟수가 가장 적은 데이터부터 교체
- 교체 대상이 여러 개면 LRU 알고리즘을 따름
→ 최근에 적재된 데이터가 교체될 수 있고 초반에 집중적으로 사용되고 사용되지 않는 데이터로 인해 메모리 낭비 문제
참고자료
https://www.charlezz.com/?p=44767
http://itnovice1.blogspot.com/2019/01/web-crawling.html
https://slidetodoc.com/memory-systems-chapter-12-memory-hierarchy-cache-memory/
https://velog.io/@khsfun0312/캐시-정책알고리즘
https://medium.com/pocs/페이지-교체-page-replacement-알고리즘-650d58ae266b
