알고리즘
1.재귀 알고리즘
나 자신을 다시 호출한다는 뜻으로, 호출한 함수 안에서 그 함수를 다시 호출(recursive call)함으로 반복하는 것을 의미한다. 주 형식은 다음과 같다.
def recursive_call(x):
print(x)
recursive_call(x+1)
recursive_call(1)그렇다면 재귀함수를 쓰는 이유는 무었이냐고 하면 일단 변수를 많이 만들 필요가 없고 코드가 간결하여 사용하기 편하다.
반복문으로 쓰인 코드는 재귀함수로 바꿔쓸 수 있는데 다음 코드를 통해 살펴보자면
for i in range(5,0,-1):
for j in range(i):
print('*',end='')
print()def recusion(num):
if num > 0:
print('*'*num)
return recusion(num-1)
else:
return 1
recusion(5)두 코드 다 표를 출력하는 코드이고 실제로 똑같이 나온다.
두번째 재귀함수 코드를 보자면 함수안에 if else구문이 있는데 num이 0 보다 크면 num만큼 를 출력하라고 한다. 그다음에 num에서 -1한 것을 다시 함수 위쪽의 num자리 즉,recusion(num)에 다시 넣고 함수를 돌리라는 것이다.계속 돌리다가 그만하는 시점은 else구문인 return 1 그러니까 num이 0보다 크지 않을때 1을 반환하라는 것이다. 그래서 위의 코드와 똑같은 구문이 나오는 것이다.
재귀함수는 보통 팩토리얼,최대공약수, 하노이의 탑 등에 사용된다.
2.하노이의 탑
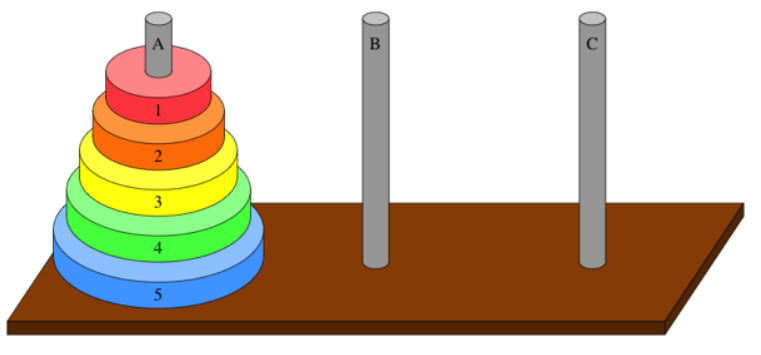
위에 보이는 것이 하노이의 탑이라는 것으로 알고리즘 문제 단골로 많이 출제되는 문제이다.
하노이의 탑은 A에 있는 원판들을 규칙에 따라 C로 옮기면 되는데 규칙은 다음과같다.
1.한번에 한개의 원판만 옮길 수 있다
2.작은원판 위에 큰 원판이 올라갈 수 없다
3.위에 아무것도 없는 원판만 옮길 수 있다
이 규칙에 따라 재귀함수를 써서 풀어보면 다음과 같다
def moveDisk(diskC,fromB,toB,viaB):
if diskC == 1:
print(f'{diskC}d를 {fromB}에서{toB}(으)로이동')
else:
moveDisk(diskC-1,fromB,viaB,toB)#diskC-1개들을 경유기둥으로 이동
print(f'{diskC}d를 {fromB}에서{toB}(으)로이동')#diskC를 목적기둥으로 이동
moveDisk(diskC-1,viaB,toB,fromB)#diskC-1개들을 도착기둥으로 이동
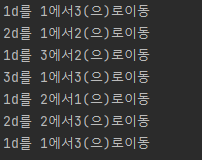
moveDisk(3,1,3,2)함수는 원판 움직임을 나타내는 함수 moveDisk를 만들었고 매개변수 diskC,fromB,toB,viaB 만들었는데
이는 차례대로 원판 개수,출발기둥, 도착기둥,경유기둥을 나타낸다.
코드를 해석해 보자면 원판이 하나일 때는 무조건 출발기둥에서 도착기둥으로 이동시키는데
아닐 경우에는 원판을 경유기둥으로 이동시킨 뒤 도착기둥으로 이동시키라는 코드 이다. 그래서 실행시켜보면 아래와 같은 결과를 확인해 볼 수 있다.
3.병합정렬
병합정렬은 어느 한 정렬을 하나씩 다 분해했다가 크기 순으로 다시 정렬하며 붙이는 정렬로 코드는 크게 분해하는 부분과 합치는 부분으로 나뉜다
def mSort(ns):
if len(ns) <2:
return ns
midIdx = len(ns) //2 #중간에 있는 값
leftN = mSort(ns[0:midIdx])
rightN = mSort(ns[midIdx:len(ns)]) #하나하나분할함
mergeN = []
leftIdx = 0; rightIdx = 0
while leftIdx <len(leftN) and rightIdx<len(rightN):
if leftN[leftIdx] < rightN[rightIdx]:
mergeN.append(leftN[leftIdx])
leftIdx += 1
else:
mergeN.append(rightN[rightIdx])
rightIdx += 1
mergeN = mergeN +leftN[leftIdx:]
mergeN = mergeN +rightN[rightIdx:]
return mergeN
nums = [8,1,4,3,2,5,10,6]
print(f'{mSort(nums)}')if len(ns) <2:
return ns
midIdx = len(ns) //2
leftN = mSort(ns[0:midIdx])
rightN = mSort(ns[midIdx:len(ns)])
바로 위의 if문이 배열num를 분해하는 코드인데 원소개수가 2개 이하일때까지 분해 하라는 뜻이다. 그리고 바로 midIdx라는 변수를 설정했는데 이 변수는 좌우를 나누기 위한 기준 즉, 중간값을 의미한다.그리고 그 아래의 두 변수도 왼쪽정렬 오른쪽정렬을 뜻한다.
mergeN = []
leftIdx = 0; rightIdx = 0
while leftIdx <len(leftN) and rightIdx<len(rightN):
if leftN[leftIdx] < rightN[rightIdx]:
mergeN.append(leftN[leftIdx])
leftIdx += 1
else:
mergeN.append(rightN[rightIdx])
rightIdx += 1
mergeN = mergeN +leftN[leftIdx:]
mergeN = mergeN +rightN[rightIdx:]
return mergeN
mergeN이라는 새 배열을 지정한 후, leftIdx = 0; rightIdx = 0 이라는 각각의 인덱스를 만들어 준후 while을 돌리는데 조건은 두 그룹 인덱스가 두 그룹 원소 갯수를 넘지 말것이라는 조건하에 오른쪽이 더 큰 원소를 가져간다는 if조건을 따라 두 집단의 인덱스가 커지고 마침내 mergeN 이라는 배열로 합치게 된다.
4.버블정렬
인접하는 인덱스의 값들을 처음부터 끝까지 순차적으로 비교하면서 큰숫자를 가장 끝으로 옮기는 정렬이다.
예를 들어
num = [2,5,9,10,4]
위와 같은 정렬이 있으면 맨 처음 값인 2와 다른 값들을 [2,5],[2,9],[2,10],[2,4]로 비교한 후 자신의 자리를 찾은 뒤 2다음 값인 5를 [5,9],[5,10],[5,4]로 2를 제외한 다른 값들을 2가 한것처럼 비교한 후 자리를 찾는 과정을 값마다 계속 반복 해주는 것이다.
import random
import bubbleM
if __name__ =='__main__':
nums = random.sample(range(1,21),10)
print(f'not sorted nums: {nums}')
result = bubbleM.sortBubble(nums)
print(f'sorted nums by asc: {result}')
result = bubbleM.sortBubble(nums,asc=False)
print(f'sorted nums by desc: {result}')import copy
def sortBubble(ns,asc=True):
c_ns = copy.copy(ns)
length = len(c_ns)-1
for i in range(length):
for j in range(length - i):
if asc:
if c_ns[j] > c_ns[j+1]:
c_ns[j],c_ns[j+1] = c_ns[j+1],c_ns[j]
else:
if c_ns[j] < c_ns[j + 1]:
c_ns[j], c_ns[j + 1] = c_ns[j + 1], c_ns[j]
print(f'ns : {c_ns}')
print()
return c_ns
위의 2개 코드는 리스트를 랜덤으로 뽑은 후 버블정렬 후 오름차순 내림차순으로 나타내고,그 과정도 함께 나타내는 코드이다.
첫번째 코드는 지역 변수를 num을 설정해 주고 random으로 10개의 숫자의 임의로 생성했다.
버블 정렬은 무조건 오름차순으로 나오는데 'asc=False'를 사용해서 오름차순이 아니라고 설정했다.
두번째 코드에서는 'asc=True' 라고 한번더 오름차순임을 설정했다.
밑에 보면 length = len(c_ns)-1 코드가 있는데 c_ns의 길이는 갯수의 -1을 왜 하는걸까 싶었는데 버블정렬은 인접 인덱스와 비교하므로 자기 자신은 빼야하기 때문이다.
그러한 이유로 첫번째for문은 length고 두번째for문은 i를 뺀 나머지를 돌린다.
if문에서 오름차순과 내림차순이 만들어지는 코드가 나오는데
if asc:
if c_ns[j] > c_ns[j+1]:
c_ns[j],c_ns[j+1] = c_ns[j+1],c_ns[j]
else:
if c_ns[j] < c_ns[j + 1]:
c_ns[j], c_ns[j + 1] = c_ns[j + 1], c_ns[j]오름차순은 [j]가 [j+1]보다 크면 자리를 바꾸라고 하고있고,내림차순은 그 반대로 하라고 설정해놓았다.
