지금까지 배운 것들로 데이터를 추출해서 비교해보자.
1.스타벅스 위치데이터
먼저 스타벅스 데이터를 가져와보고자 한다.
# 페이지 접근
url = "https://www.starbucks.co.kr/store/store_map.do?disp=locale"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(url)위의 페이지 접근 코드를 실행시키면 다음과 같은 창이 나온다.
스타벅스의 서울 전체의 위치코드만 알고싶으므로 서울 버튼을 클릭 후 전체 버튼을 클릭해야된다
그래서 다음과 같은 코드를 써주었다
# 지역 버튼 클릭
jiyeog_star = driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a").click()
jiyeog_star
#서울 버튼 클릭
sido_star = driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a").click()
sido_star
# 전체 버튼 클릭
all_star = driver.find_element_by_css_selector("#mCSB_2_container > ul > li:nth-child(1) > a").click()
all_star버튼밖에 없으므로 css_selector를 사용했다.
# 데이터 추출
import requests
from bs4 import BeautifulSoup
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
content = soup.find("div", id = "mCSB_3_container")
contents = content.find_all("li")
contents[0]데이터를 추출하기 위해 데이터가 담겨있는 섹션인 "div"와 id를 찾은 후 "li"로 된 모든 값들을 넘겨받는다.
그 후 데이터 정리를 하는데, 전화번호는 필요없으니 지우고 "매장이름","주소","구"를 contents에서 뽑아낸 후 설정하고, 브랜드도 같이 붙여준다
#데이터 정리
starbucksList = []
for li in contents:
name = li.find("strong").text.strip()
address = li.find("p").text.strip().replace("1522-3232","")
gu =address.split(" ")[1]
print(name, address, gu)
each ={
"매장이름": name,
"주소" : address,
"구" : gu,
"브랜드": "스타벅스"
}
starbucksList.append(each)이렇게 실행하면 다음과 같이 나온다

그리고 깔끔하게 보기위해 pandas실행하면 다음과 같이 나온다
import pandas as pd
dfstar = pd.DataFrame(starbucksList)
dfstar.head(10)2.이디야 위치데이터
위와 똑같이 접근 해주고 주소버튼을 클릭 해주니 스벅과는 좀 다른 모습이 떴는데, 이디야는 직접 매장명이나 위치명을 검색해애 하는 구조이다.
그러니 위의 스타벅스 처럼 버튼을 클릭해서 데이터를 추출할 수 없다.
그래서 선택한 방법이 서울에 있는 구를 반복문 돌려서 검색하여 추출하자는 것이다.
이를 시행하기 위해선 일단 서울의 어떤 구가 있고, 몇개의 구가 있는지 알아보기 위해 스타벅스의 구 를 추출한다
#스벅 구 리스트 뽑기
gu_list = list(dfstar["구"].unique())
len(gu_list)모든 구를 검색하기 위해선 위에서 말했다 싶이 반복문을 먼저 써야 되는데 반복문 안에 위치를 검색할 수 있는 공간인"#keyword"를 지정해 놓고 검색초기화, 입력, 검색 버튼 클릭을 반복한다.
그 다음은 스타벅스때와 똑같이 해준다.
eidiyaList =[]
for gu in tqdm_notebook(gu_list):
driver.find_element_by_css_selector("#keyword")
# 검색 초기화
driver.find_element_by_css_selector("#keyword").clear()
# 입력
driver.find_element_by_css_selector("#keyword").send_keys(f"서울 {gu}")
# 검색 버튼 클릭
driver.find_element_by_css_selector("#keyword_div > form > button").click()
# 이디야 구별 매장 정보 수집
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
ul_tag = soup.find("ul",id ="placesList")
dl_all = ul_tag.find_all("dl")
for dl in dl_all:
name = dl.find("dt").text.strip()
address = dl.find("dd").text.strip()
gu = address.split(" ")[1]
each ={
"매장이름": name,
"주소" : address,
"구" : gu,
"브랜드" : "이디야"
}
eidiyaList.append(each)그리고 이 뽑힌 데이터로 또 똑같이 정리하면
dfedi = pd.DataFrame(eidiyaList)
dfedi.head(10)
3.시각화 및 분석
먼저 시각화 하기 전 두 데이터를 합쳐준다.
# 데이터 합치기
df_sum = pd.concat([dfstar,dfedi])
df_sum.reset_index(drop=True,inplace=True)
df_sum.tail()그 후 지도표현을 위해 구글맵API를 사용한다.
import googlemaps
gmaps_key ="AIzaSyDUt5AySy0XWvpoznvFekqEqoGY0zEKZaA"
gmaps = googlemaps.Client(key= gmaps_key)
gmaps
실행시킨 후 "<googlemaps.client.Client at 0x2148c32adf0>" 같은 글이 뜨면 성공한 것이다.
위치데이터를 뽑아 올 것이니 일단 위도,경도를 설정해준다. 그 후 데이터에 위도,경도를 추가해준다
#지도 위도,경도
import numpy as np
df_sum["위도"]=np.nan
df_sum["경도"]=np.nan
#원 데이터에 주소,위도,경도 추가
for idx, rows in tqdm_notebook(df_sum.iterrows()):
tmp = gmaps.geocode(rows["주소"], language="ko")
if tmp:
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
df_sum.loc[idx, "위도"] = lat
df_sum.loc[idx, "경도"] = lng
else:
print(idx, rows["주소"])이 데이터들을 지도 데이터로 저장 하면 다음과 같은 모습이 된다.
# 지도 데이터 저장
df_sum.to_csv("../date/df_sum_realymaps.csv",sep=",",encoding="utf-8")
df_sum_csv = pd.read_csv("../date/df_sum_realymaps.csv",encoding="utf-8",index_col=0)
df_sum_csv.tail()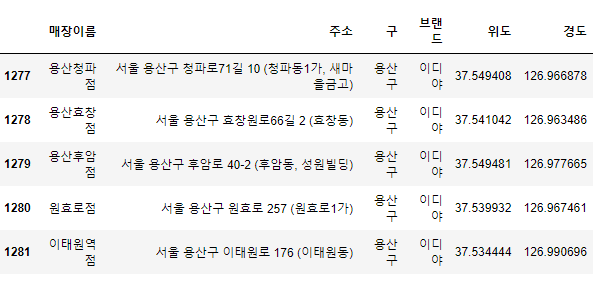
일단 나는 막대그래프와 지도 그래프로 시각화 할 것이다.
일단 막대그래프로 시각화 해보면서 한글설정도 같이 하자면 다음과 같은 코드를 사용한다.
from matplotlib import font_manager
from matplotlib import rc
f_path = "C:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc("font", family=font_name)
rc("axes", unicode_minus=False)
get_ipython().run_line_magic("matplotlib", "inline")df_sum_count=df_sum_csv.pivot_table(index="구",columns="브랜드",values="값", aggfunc=np.sum)
df_sum_count.tail()df_sum_count.plot.bar(rot=0, figsize=(17,6), color=["green", "blue"])또한 위에서의 자료를 통해서 지도에 원그래프로 나타내보았다.
seoul_center = [37.517692, 126.989912]
my_map = folium.Map(
location = seoul_center,
zoom_start = 11.5,
tiles = "StamenToner"
)
for idx, rows in df_sum_count.iterrows():
# 스타벅스
folium.Circle(
location = [rows["위도"], rows["경도"]],
radius = rows["스타벅스"] * 50,
fill = True,
color = "green",
fill_color = "green",
popup = idx,
tooltip = idx,
).add_to(my_map)
# 이디야
folium.Circle(
location = [rows["위도"], rows["경도"]],
radius = rows["이디야"] * 50,
fill = True,
color = "blue",
fill_color = "blue",
popup = idx,
tooltip = idx,
).add_to(my_map)
my_map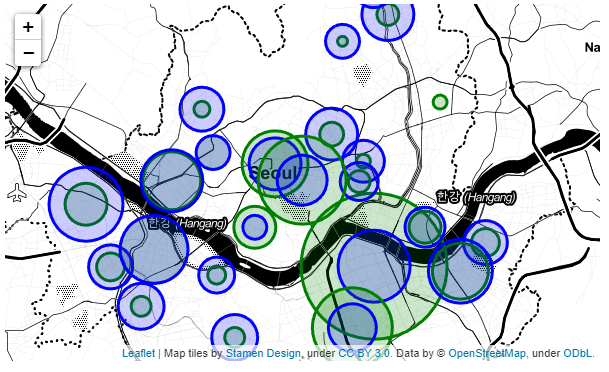
분석 결과 : 스타벅스는 주로 강남,서초,중구,용산과 같은 비싼 도시들에 주력해서 자리를 잡고있지만, 이디야는 서울 곳곳에 고루 포진되어 있다. 만약 이디야가 스타벅스 근처에서 매장을 연다면 스타벅스 매장과 이디야 매장 개수가 정비례 해야 하는데 강남 같은 경우는 약 2배 정도 매장 수가 차이나고,반대로 노원구나 영등포구 같은 경우는 스타벅스 매장이 이디야 매장의 0.5배이다. 그리고 도봉구를 제외한 다른구를 보면 이디야는 약20개 매장이 있는 반면에 스타벅스는 강남을 제외한 다른 구들에서는 매장이 20개 이상인 구가 몇개 없다. 따라서 이디야가 스타벅스 옆에 의도적으로 매장을 세우는 것이 아니라. 이디야는 구마다 매장이 많으므로 많은 매장으로 인해 어쩔 수 없이 위치기 겹치는 것이다.
