관계형 데이터베이스
행과 열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스. SQL이라는 언어를 사용하여 조작.
(ex. MySQL, PostgreSQL, 오라클, SQL Server, MSSQL 등)
관계형 데이터베이스는 표준 SQL을 지키지만 각각의 제품에 특화시킨 SQL 사용.
(오라클 → PL/SQL, SQL Server → T-SQ, MySQL → SQL 사용)
1. MySQL
대부분의 운영체제와 호환. 현재 가장 많이 사용하는 데이터베이스. C, C++로 만들어져 B-트리 기반의 인덱스, 스레드 기반의 메모리 할당 시스템, 매우 빠른 조인, 최대 64개의 인덱스 제공.
대용량 데이터베이스를 위해 설계됨. 롤백, 커밋, 이중 암호 지원 보안 등의 기능 제공하며 많은 서비스에서 사용.
2. PostgreSQL
MySQL 다음으로 개발자들이 선호하는 데이터베이스.
디스크 조각이 차지하는 영역을 회수할 수 있는 장치인 VACCUM이 특징. SQL 뿐만 아니라 JSON을 이용해 데이터 접근 가능. 지정 시간에 복구하는 기능, 로깅, 접근 제어, 중첩된 트랜잭션, 백업 등 가능.
3. NoSQL
Not Only SQL이란 슬로근에서 생격난 데이터베이스. SQL 사용하지 않는 데이터베이스. (ex. MongoDB, redis)
- MongoDB
json에 접근 가능하며, 데이터가 저장되면 와이어드타이거 엔진이 기본 스토리지 엔진으로 장착된 키-값 데이터 모델에서 확장된 도큐멘트 기반의 데이터베이스. - redis
인메로리 데이터베이스이자 키-값 데이터 모델 기반의 데이터베이스
인덱스
데이터를 빠르게 찾을 수 있는 하나의 장치. 책으로치면 마지막 장 찾아보기 페이지 같은 기능. '항목'을 통해 원하는 내용을 빠르게 찾을 수 있음. 이처럼 인덱스를 설정하여 테이블에서 찾고자하는 데이터를 빠르게 찾을 수 있음.
B-트리
인덱스는 보통 B-트리라는 자료 구조로 형성됨.
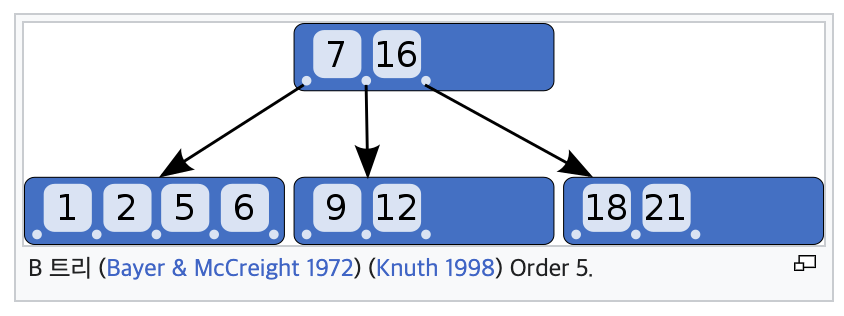
루트 노드(아래 그림의 7, 16), 리프 노드(1,2,5,6), 브랜치 노드(루트 노드와 리프 노드 사이의 노드)로 나뉨.
전산학에서 B-트리(B-tree)는 데이터베이스와 파일 시스템에서 널리 사용되는 트리 자료구조의 일종으로, 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조이다.
방대한 양의 저장된 자료를 검색해야 하는 경우 검색어와 자료를 일일이 비교하는 방식은 비효율적이다. B-트리는 자료를 정렬된 상태로 보관하고, 삽입 및 삭제를 대수 시간으로 할 수 있다.
https://ko.wikipedia.org/wiki/B_%ED%8A%B8%EB%A6%AC
인덱스가 효율적인 이유 & 대수확장성
효율적인 단계를 거쳐 모든 요소에 접근할 수 있는 균형 잡힌 트리 구조와 트리 깊이의 대수확장성 때문.
대수확장성
: 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것을 의미.
기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 하목의 수는 4배씩 증가.
인덱스 만드는 방법
[MySQL]
클러스터형 인덱스와 세컨더리 인덱스가 있음. 클러스터형 인덱스는 테이블당 하나를 설정 가능. 프라이머리 키 옵션으로 기본키로 만들면 클러스터형 인덱스를 생성 가능. 기본키로 만들지 않고 unique not null 옵션으로 클러스터형 인덱스 만들 수 있음.
[MongoDB]
문서를 만들면 자동으로 ObjectID가 형성됨. 해당 키가 기본키로 설정되며, 세컨더리키도 부가적으로 설정해서 기본키와 세컨더리키를 같이 쓰는 복합 인덱스 설정 가능.
인덱스 최적화 기법
- 인덱스는 비용이다
인덱스는 두 번 탐색하도록 강요함. B-트리의 높이를 균형 있게 조절하는 비용도 들고, 데이터를 효율적으로 조회할 수 있도록 분산시키는 비용도 들기 때문에 쿼리에 이쓴 필드에 인덱스를 무작정 다 설정하는 것은 답이 아님. - 항상 테스팅하라
각 서비스마다 사용하는 객체 깊이나 테이블 양이 다르기 때문에 테스팅을 하며 걸리는 시간을 최소화하는 방법 모색 필요. - 복합 인덱스는 같음, 정렬, 다중 값, 카디널리티 순이다
여러 필드를 기반으로 조회할 때 복합 인덱스 생성. 생성 순서에 따라 인덱스 성능이 달라짐.
(1) 어떠한 값과 같음을 비교하는 == 혹은 equal 쿼리가 있다면 제일 먼저 인덱스로 설정
(2) 정렬할 때 쓰는 필드라면 그다음 인덱스로 설정
(3) 다중 값을 출력해야하는 필드가 > 혹은 < 처럼 많은 값을 출력해야하는 쿼리에 스는 필드라면 나중에 인덱스 설정
(4) 카디널리티 : 유니크한 값의 정도. 카디널리티가 높은순서를 기반으로 인덱스를 생성
출처
면접을 위한 cs 전공지식 노트 (주홍철 지음, 출판사 길벗)
https://songsunkite.tistory.com/211
