안녕하세요. 이번 글에서는 leader epoch이 처음으로 제안된 (KIP-101) Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation에 대한 번역과 개인적인 후기를 작성해보았습니다.

Log Replication Protocol
leader epoch에 대해 다루기 전에, 먼저 카프카에서 파티션 로그가 리더 브로커에서 팔로워 브로커로 복제되는 과정에 대해서 살펴보도록 하겠습니다.로그 복제 과정은 producer의 ack 설정이나 min.isr 설정과 같은 요소에 따라 일부 차이가 존재할 수 있습니다만, 이번에는 핵심 용어를 중심으로 전반적인 과정을 다루는 것을 목표로 하였습니다.
예시에서는 하나의 파티션에 3개의 replica가 존재하는 경우를 가정하였습니다. broker-101은 리더 브로커이며, 나머지 브로커(broker-102, broker-103)는 팔로워 브로커입니다. min.isr은 1을 가정하였습니다.
Follwer Fetch Request
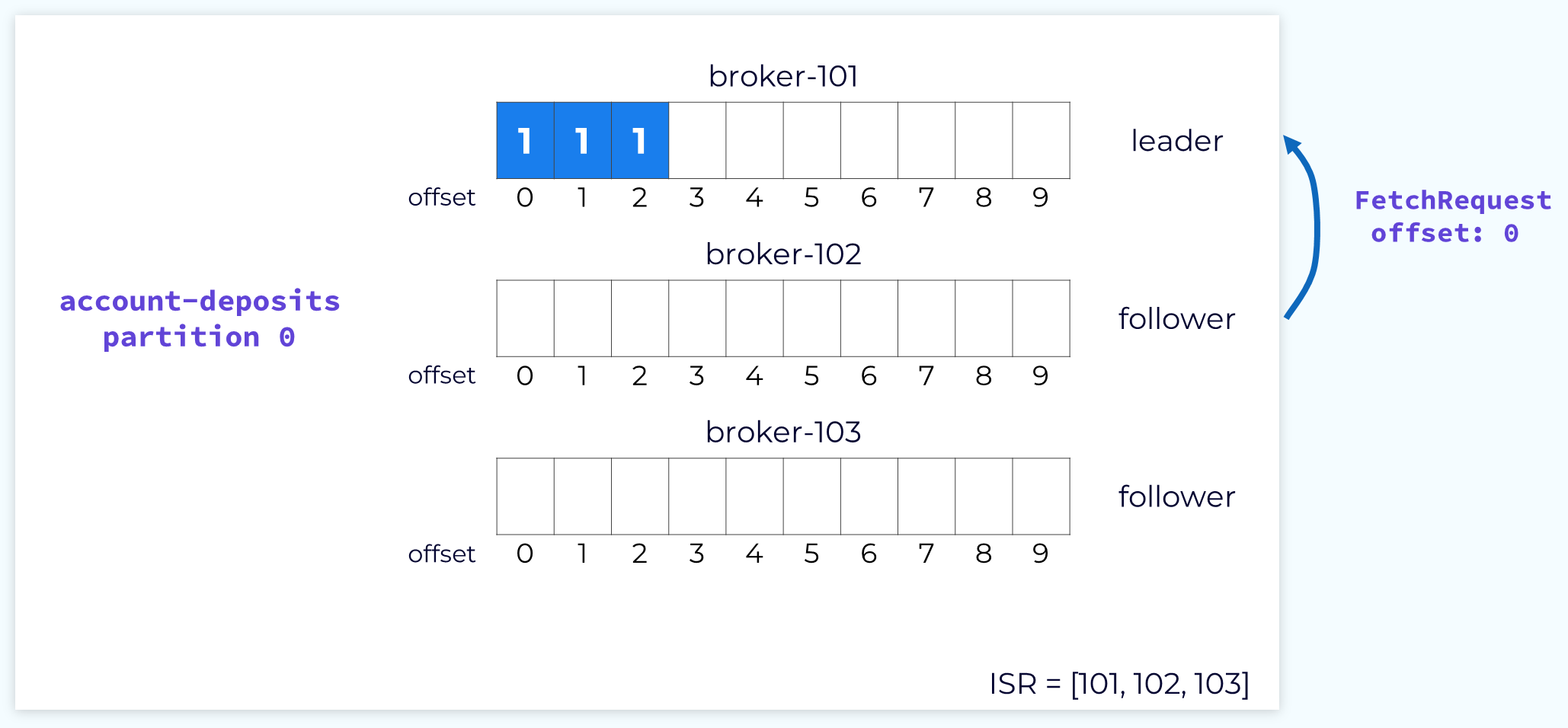
팔로워 브로커는 주기적으로 리더 브로커에게 로그 복제를 위한 FetchRequest를 전송합니다. FetchRequest에는 현재 팔로워 브로커가 가지고 있는 offset이 포함되어 있습니다.
Follower Fetch Response
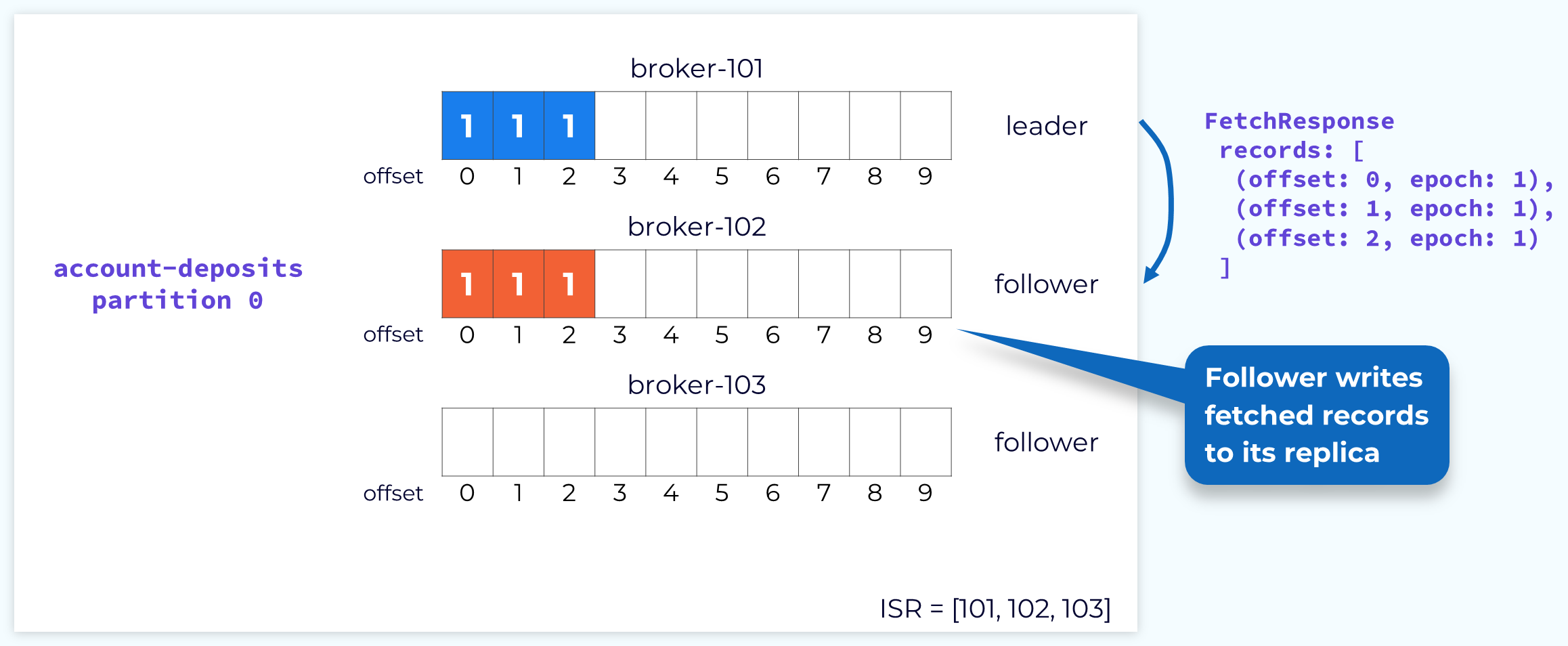
리더 브로커는 팔로워 브로커가 보낸 FetchRequet의 offset을 확인하고 해당 오프셋 이후로 쌓인 데이터를 FetchResponse에 담아 전달합니다. 이 과정을 통해 하나의 팔로워 노드에 데이터 복제가 이뤄집니다.
Committing Partition Offsets
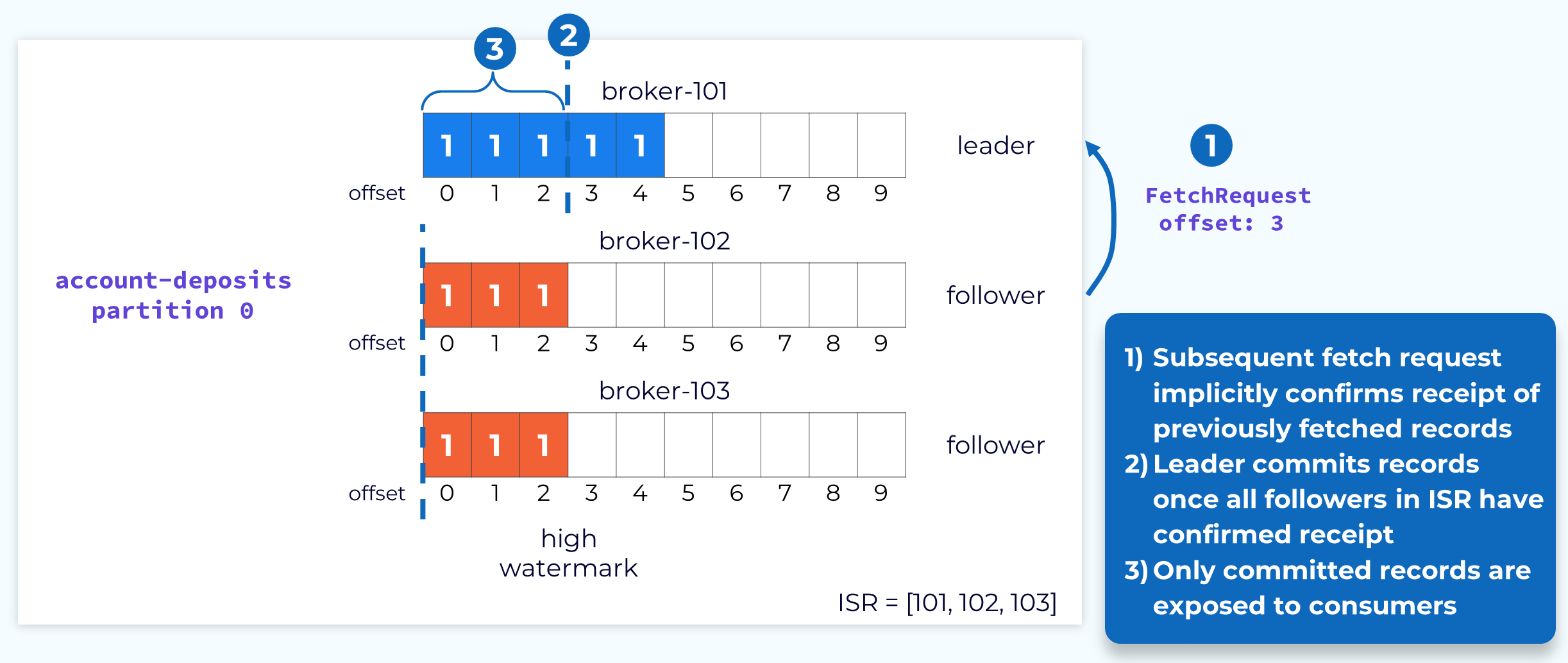
리더 노드는 모든 노드에 성공적으로 메시지가 복제된 경우, 해당 지점까지의 offset을 commit 합니다. Commit이 완료되어야 비로서 컨슈머들이 해당 파티션에서 데이터를 조회할 수 있습니다.
그런데, 카프카는 RPC call을 최소화하기 위해 FetchResponse에 대한 ack 응답을 전송하지 않습니다. 그렇다면 팔로워 노드에 데이터가 성공적으로 복제되었다는 사실을 리더 노드에 어떻게 전달할까요?
카프카에서는 FetchRequest에 포함된 offset을 활용합니다. FetchRequest를 전송한 팔로워 노드는 해당 요청에 포함되어 있는 offset은 이전 데이터를 성공적으로 전달 받았음을 의미합니다. 따라서, FetchRequset를 전달받은 리더 노드는 ISR에 포함된 팔로워 노드들의 FetchRequest 속 offset을 확인하고 이를 통해 commit 지점을 업데이트 합니다. 또한, FetchResponse를 통해 팔로워 노드들에게 변경된 commit offset을 전달합니다. 마지막으로 commit된 offset을 high watermark라고 부릅니다.
기존 High Watermark 방식의 Replication Protocol의 한계
앞서 설명드린 방식의 log replication protocol에는 몇 가지 문제점이 있습니다.
바로, 리더 브로커와 팔로워 브로커의 high watermark 업데이트 시점에 지연이 발생한다는 것입니다. 리더 노드는 FetchRequest를 전달받은 시점에 high watermark를 업데이트 하지만, 팔로워 노드는 FetchResponse를 받은 시점에서야 high watermark를 업데이트 할 수 있기 때문입니다. High watermark 업데이트 지연은 특정 상황에서 메시지 유실 뿐만 아니라 정합성 붕괴까지 이어질 수 있습니다.
예시를 통해 좀 더 자세히 알아보도록 하겠습니다.
Scenario 1: High Watermark Truncation followed by Immediate Leader Election
High watermark 업데이트 지연이 발생한 브로커 노드가 급작스럽게 리더 노드로 선출되는 경우입니다.
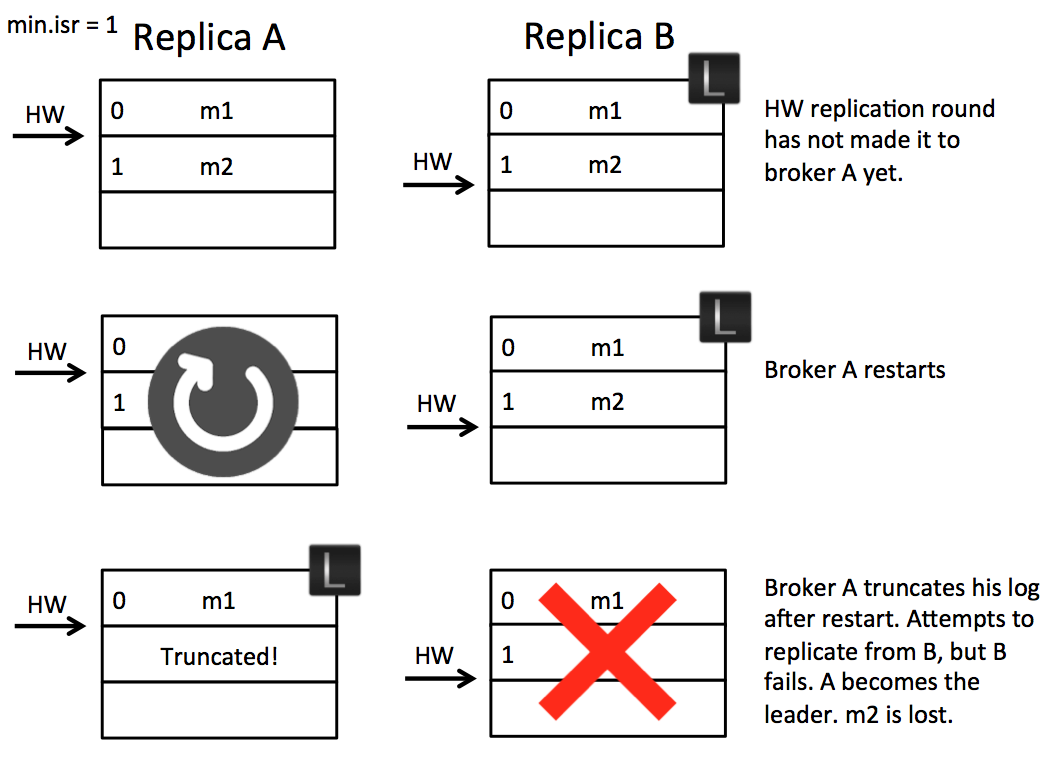
2개의 replica를 갖는 하나의 파티션이 있습니다. 파티션은 A 브로커와 B 브로커로 구성되어 있으며, B 브로커가 파티션의 리더 브로커입니다.
-
1번 오프셋(m2)까지 복제를 마친 팔로워 브로커 A가 리더 브로커 B에게
FetchRequest(offset=2)를 전송합니다. -
요청을 수신한 리더 브로커 B는 1번 오프셋(m2)까지 복제가 완료된 것을 확인하고 high watermark를 업데이트 합니다. 더 복제할 로그가 없으므로, 업데이트된 high watermark에 대한 정보만을 담은
FetchResponse를 팔로워 브로커 A에게 전송합니다. -
팔로워 브로커 A가
FetchResponse를 수신하지 못하고 재시작됩니다. 재시작된 팔로워 브로커 A는 high watermark 이후의 데이터를 모두 삭제하고 리더 브로커 B에게 다시FetchRequset를 전송합니다. -
리더 브로커 B가 갑작스러운 장애로 인해 다운됩니다.
-
메시지 m2가 유실됩니다.
위 사례는 메시지 유실 뿐만 아니라 phantom read와 같은 추가적인 문제를 발생시킬 수 있습니다.
팔로워 브로커 A가 재시작되고 새로운 리더가 되기 전까지, m2는 커밋된 상태로 리더 브로커 B를 통해 컨슈머에서 접근이 가능했기 때문입니다.
Jun Rao는 이를 해결하기 위한 간단한 해결책을 2가지 제시합니다.
- 팔로워 브로커의 high watermark 업데이트를 마칠 때까지, 리더 브로커의 high watermark 업데이트를 지연시킨다.
이 방법은 추가적인 RPC call을 발생시켜 kakfa의 log replication protocol의 전반적인 latency를 크게 증가시키므로 불가능하다고 판단합니다. 이는 ack를 제거하여 효율을 높인 kafka log replication protocol의 장점을 크게 하락시키는 문제가 있습니다.
- 팔로워 브로커가 재시작되면, 로컬에 남아있는 highwater mark 이후의 데이터를 즉시 삭제하는 것이 아니라, leader broker에 fetch 요청을 전송하고 그 결과를 바탕으로 결정한다.
이 방법은 시나리오 1에서 발생한 메시지 유실 문제를 해결할 수 있습니다. 그러나 근본적으로 high watermark에만 의존한 복구 방식은 다음에 소개해드릴 상황을 근본적으로 해결할 수 없습니다.
Scenario 2: Replica Divergence on Restart after Multiple Hard Failures
모든 브로커가 동시에 종료되고, 불완전한 팔로워 브로커가 먼저 재시작되어 리더로 선출된 경우입니다.
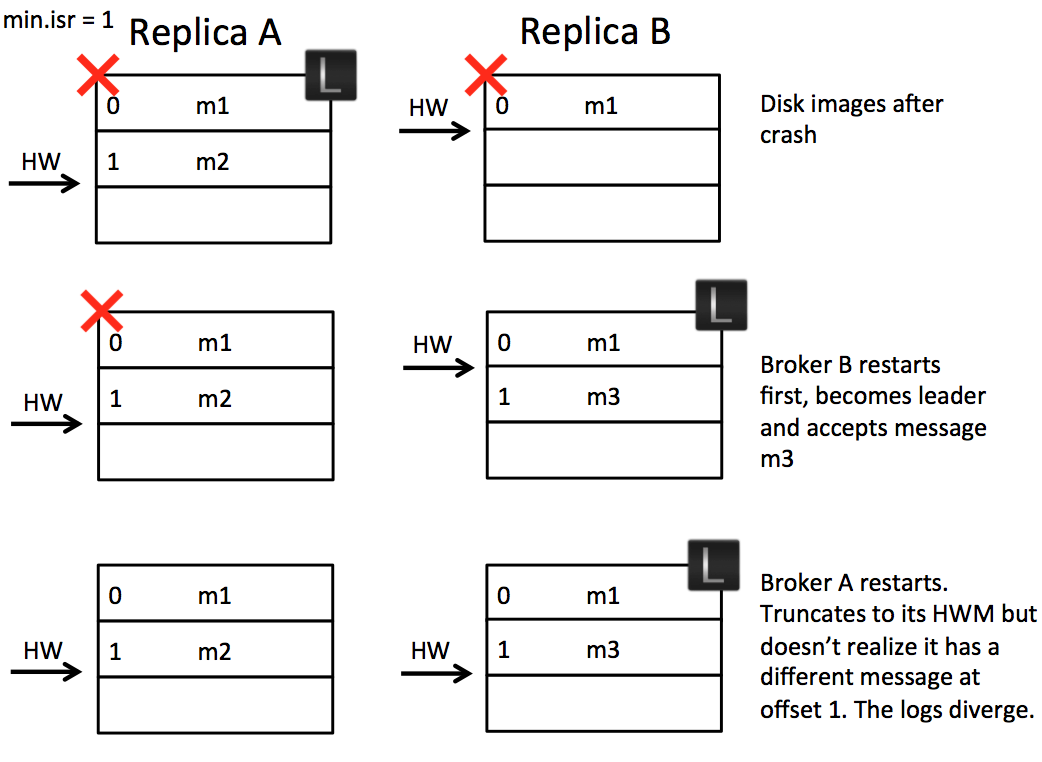
위 예시에서는 브로커 B에서 메시지 m2에 대한 FetchResponse 응답을 받았지만, 디스크에 flush 되지 않은 상황을 가정하였습니다. 동일하게 2개의 replica로 구성된 하나의 파티션이며, A가 리더 브로커, B가 팔로워 브로커인 상황입니다.
- 전원 공급 차단 등으로 인해 브로커 A, B가 모두 재시작된다.
- 브로커 B가 먼저 재시작되어, 리더가 된다.
- 리더가 된 브로커 B가 프로듀서로부터 메시지
m3를 받아서 쓴다. - 브로커 A가 팔로워로 재시작된다.
브로커 A와 B는 서로 다른 메시지를 갖고 있지만, 동일한 offset을 가지고 있습니다. 이 경우, 팔로워 브로커 A는 replica로서의 기능을 상실하였습니다. 심지어 브로커 A가 FetchRequest를 전송하면 정상적으로 log replication protocol이 동작합니다. 이는 토픽의 붕괴로 이어질 수 있습니다.
Leader Epoch
이러한 문제를 해결하기 위해 KIP-101에서 leader epoch라는 개념이 도입되었습니다.
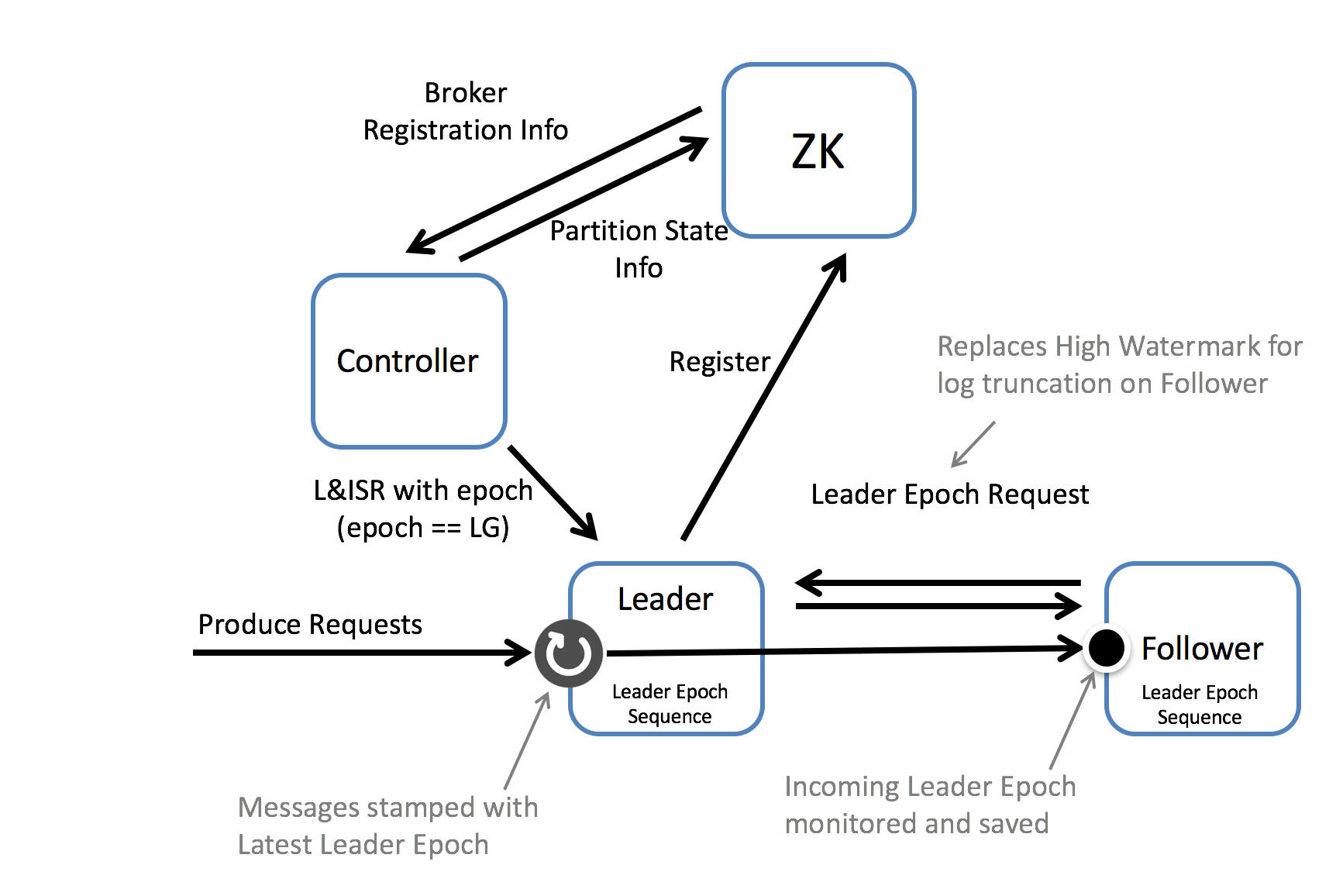
Leader Epoch는 현재 파티션 리더 브로커에 대한 임시 식별자와 같은 개념입니다. 실제로는 0부터 시작하여 새로운 리더가 선출될 때 마다 1씩 증가합니다. 리더 브로커가 바뀌면 leader epoch 또한 바뀌며, 동일한 파티션의 동일한 브로커가 다시 리더로 복귀하더라도 leader epoch은 이전과 다른 값을 갖습니다.
각 파티션에 대한 leader epoch은 controller에 의해 관리되어, zookeeper에 저장되며, 매 새로운 리더 선출시에 활용됩니다. 최근 버전에서는 내부적 구조가 위 그림과 정확히 일치하지 않을 수 있으므로, 당시 제안된 구조를 이해하는 참고용으로만 활용해주세요.
각 브로커는 리더가 새롭게 선출될 때 마다 leader epoch과 해당 시점의 offset을 기록합니다. 리더의 이름과 즉위일을 나열한 키-밸류로 이해하셔도 좋을 것 같습니다. 이를 leader epoch sequence 라고 부릅니다. 이 leader epoch sequence를 복구 시에 high watermark를 대신하여 브로커 재시작 시, 복구에 활용하게 됩니다.
브로커가 재시작 될 경우, 로컬에 기록된 high watermark 이후의 데이터를 모두 삭제하는 것이 아니라, 리더에게 leader epoch 요청한 후, 이를 비교하여 삭제 여부를 판단하게 됩니다.
leader epoch을 활용하면 앞서 언급드린 두 가지 문제를 모두 해결할 수 있습니다.
Scenario 1: High Watermark Truncation followed by Immediate Leader Election
먼저, 불완전한 팔로워 브로커의 재시작과 리더의 재시작이 연속적으로 일어나는 경우입니다.
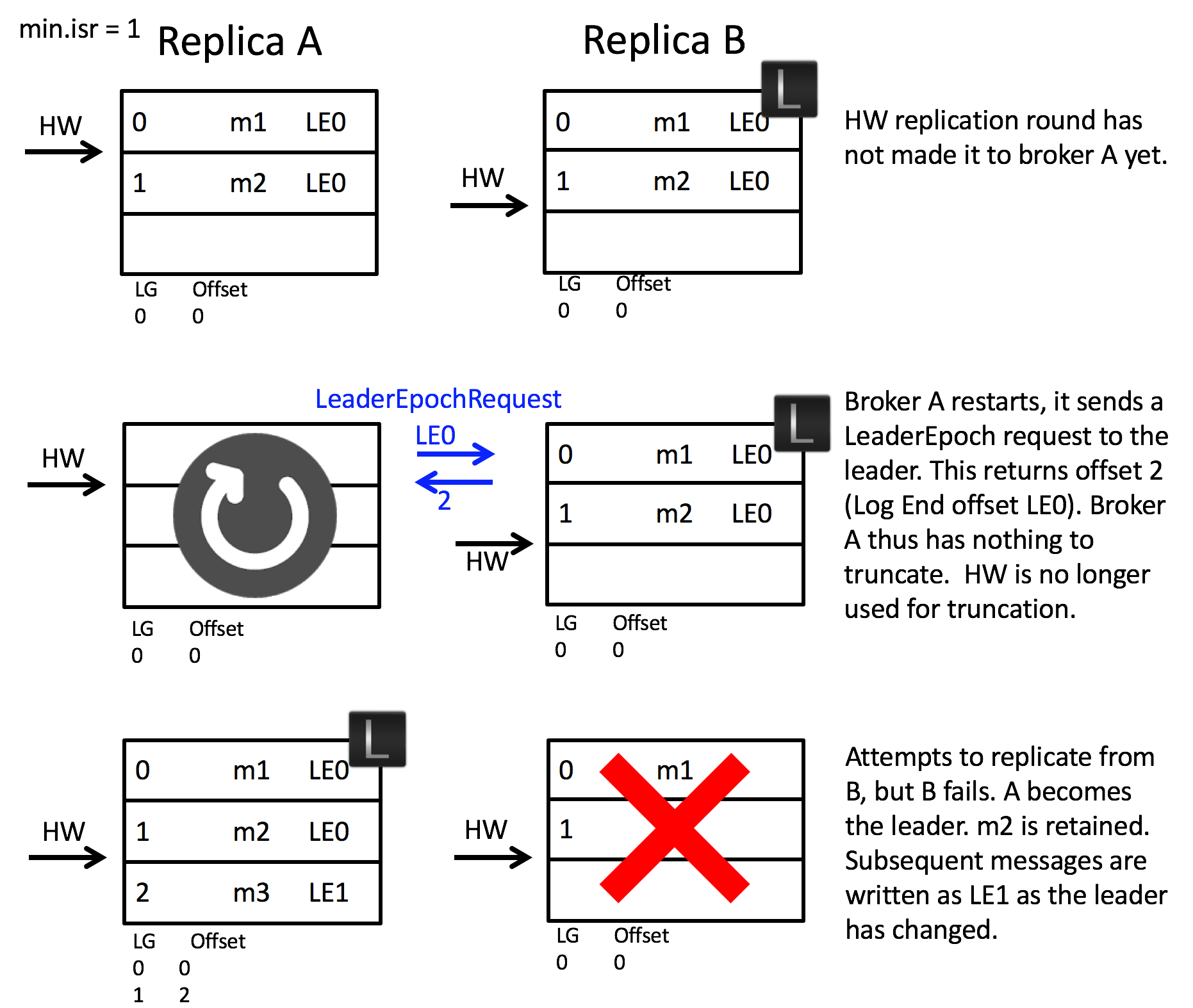
- 팔로워 브로커 A는 리더 브로커 B의 데이터를 모두 복제하였지만, high watermark를 업데이트 하지 못 한 상태로 종료되었습니다.
- 재시작된 팔로워 브로커 A는 리더 브로커에게
LeaderEpochRequst를 전송하고 현재 오프셋에 해당하는 2를 반환 받습니다. - 팔로워 브로커 A에 저장된 데이터의 길이가 해당 오프셋과 일치하므로, 팔로워 브로커 A는 high watermark와 상관없이 메시지를 삭제하지 않습니다.
- 리더 브로커 B가 장애로 인해 종료됩니다.
- 브로커 A가 새로운 리더로 선출되며 leader epoch 1을 부여받습니다. 이를 leader epoch sequence에 기록합니다.
만약 리더 브로커 B가 LeaderEpochRequest에 대한 응답을 주지 못하고 재시작 되더라도 결과는 동일합니다.
Scenario 2: Replica Divergence on Restart after Multiple Hard Failures
다음으로 모든 브로커가 동시에 종료되고, 불완전한 팔로워 브로커가 먼저 재시작되어 리더로 선출된 경우를 다시 살펴보겠습니다.
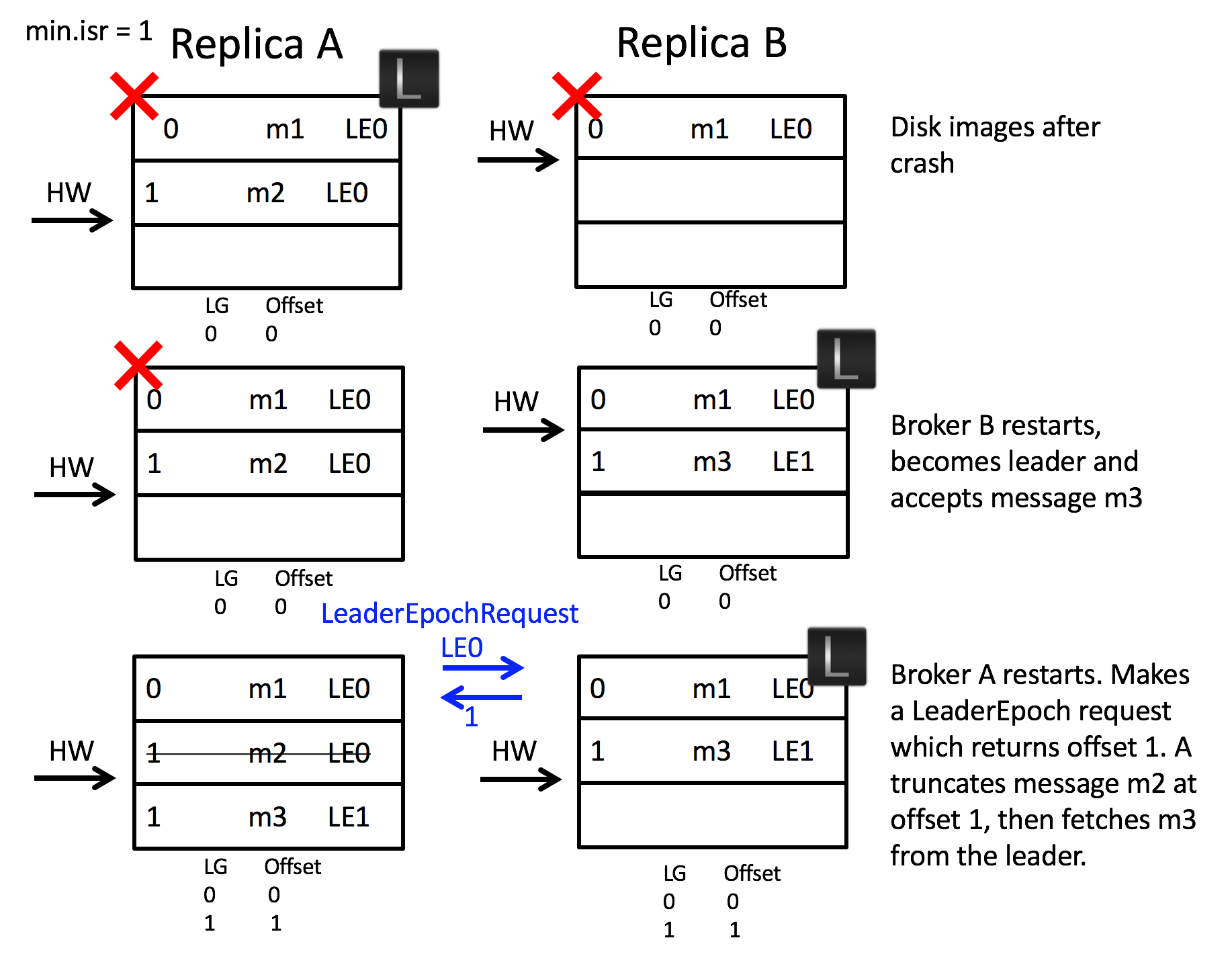
- 불완전하게 복제된 상태로 리더 브로커 A와 팔로워 브로커 B가 동시에 종료됩니다.
- 팔로워 브로커 B가 먼저 재시작되어 새로운 리더로 선출됩니다.
- 브로커 B는 리더이므로, LeaderEpoch 교환 과정을 거치지 않습니다.
- 리더가 된 브로커 B가 프로듀서로부터 새로운 메시지 m3를 전송받습니다.
- 브로커 A가 팔로워가 되어 재시작됩니다.
- 리더 브로커 B에게
LeaderEpochRequest를 전송하고 1을 반환받습니다. - 현재 로컬에 가지고 있는 메시지 오프셋은 2이므로, 현재 리더의 start offset에 해당하는 1 이후의 데이터는 모두 삭제합니다. 따라서, m2 메시지가 삭제됩니다.
leader epoch 기반의 복구를 적용하면, 불완전한 상태로 모든 브로커가 재시작되는 상황에서도 정합성 불일치가 발생하지 않습니다. m2 메시지 유실이 발생하였지만, 이는 복구 프로토콜의 문제가 아닌 min.isr 설정이 원인이라고 할 수 있습니다.
정리
이번 글에서는 카프카에 leader epoch가 도입된 배경과 내부적인 동작 원리에 대해 살펴보았습니다.
감사합니다.
References
