
Raft Consensus Algorithm
raft는 etcd에서 채택하고 있는 분산합의 알고리즘이다. 분산합의 알고리즘은 노드들이 서로 상태를 교환하고, 동기화하는 일련의 과정을 의미한다. 분산합의 알고리즘은 대표적으로 Raft, Paxos, Apache Zookeeper에서 사용하는 ZAP등이 있다.
Leader-Follower
Raft에서는 Leader-Candidate-Follower의 클러스터 구조를 사용한다. 리더는 클러스터에서 이뤄지는 모든 변화를 기록하고 관리하는 역할을 담당한다. 팔로워는 주로 데이터를 읽는 기능과, 자신이 처리할 수 없는 요청을 리더로 전달하는 기능을 한다. Candidate는 현재 클러스터에서 리더에 문제가 생긴 경우, 리더가 될 자격을 갖춘 팔로워 노드에 해당한다. 이와 관련된 설명은 Election에서 다루었다.
Log Replication
클라이언트로 부터 새로운 요청이 전달되면, 리더(S5)는 로컬에 해당 로그를 저장하고 로그를 복제하여(AppendLogEntry) 팔로워 노드들에게 전송한다. 모든 로그는 고유한 인덱스 값을 갖는다.
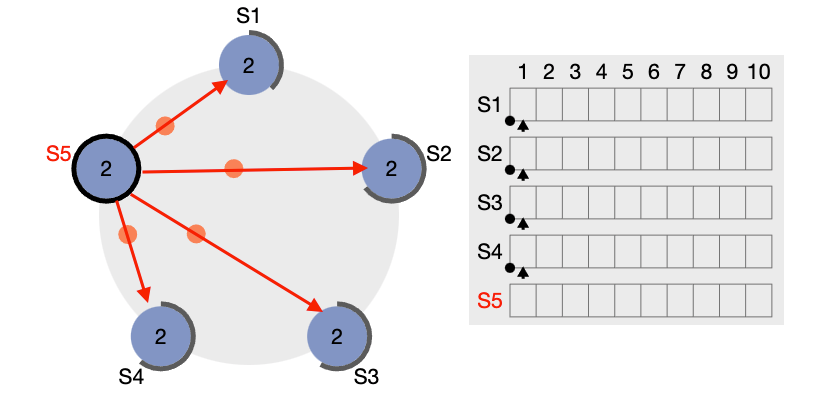
AppendLogEntry를 받은 노드는 로그의 인덱스와 자신의 로컬에 저장된 인덱스를 비교한다. 요청의 순서가 올바른 경우, 팔로워는 해당 로그를 복제하고 성공 응답을 리더에게 전달한다. 요청의 순서가 올바르지 않거나, 팔로워가 일시적인 장애로 인해 outdated된 경우, 팔로워는 nextIndex를 실패 응답에 실어서 리더에게 전달한다. 리더는 팔로워가 보낸 nextIndex 값을 보고 현재 팔로워의 상태를 파악하고 밀린 로그들을 팔로워에게 다시 전송하여 복구를 진행한다.
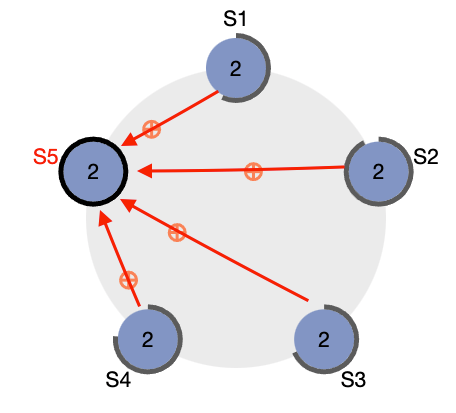
과반수 이상의 노드에서 성공 응답이 도착하면, 리더가 마지막으로 해당 로그를 커밋하고, 클라이언트에게 성공 응답을 전송한다.
Election
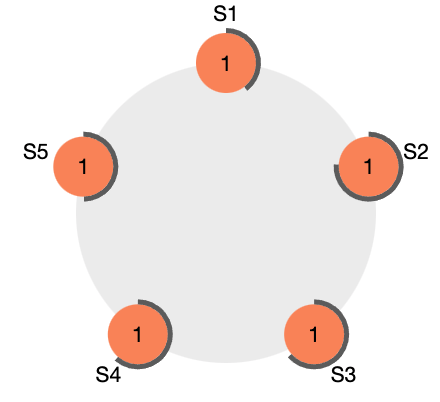
리더는 클라이언트로부터 새로운 요청이 없더라도, 지속적으로 팔로워에게 AppendLogEntry를 전송하여 자신이 살아있음을 알린다. 만약 리더에 문제가 생겨, 팔로워가 ElectionTimeout 시간만큼 AppendLogEntry를 받지 못한 경우, 팔로워는 리더가 되기 위한 후보자, Candidate으로 전환된다.
아래의 그림은 클러스터에 리더가 부재가 존재하는 상태를 나타낸다. 검은 색 띠처럼 표현된 것은 팔로워가 후보자가 되기까지 남은 시간을 나타낸다.
아래의 그림은 ElectionTimeout이 경과한 노드가 후보자가 되어, 다른 노드들에게 선거를 요청하는 것을 표현한 그림이다.
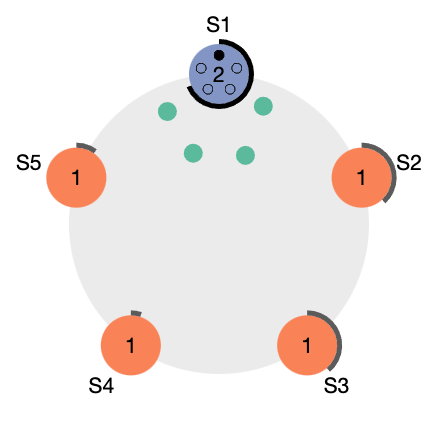
모든 선거는 회차(ElectionTerm)을 가지며, 매 선거가 마다 이 값이 1씩 증가한다. 후보자가 된 노드는 다른 노드들에게 이번 선거에서 자신에게 투표할 것을 요청한다. 한 노드는 매 선거마다 하나의 노드에만 투표를 할 수 있고, 같은 회차에서 가장 많은 표를 받은 노드가 새로운 리더로 선출된다. 만약 선거에서 동률이 나올 경우에는, 선거를 다시 진행한다.
팔로워 마다 ElectionTimeout이 랜덤하게 정해지기 때문에, 후보자로 빠르게 전환된 노드가 주로 다음 리더로 선발된다.
References
https://swalloow.github.io/raft-consensus/
https://kasunindrasiri.medium.com/understanding-raft-distributed-consensus-242ec1d2f521
