node.js
- 해당 게시글은 Javascript의 작동방식에 대해 좀 더 자세히 알아보기 위해 작성되었습니다.
- 전에 작성한 적이 있지만 부족한 점이 많아보여 다시 작성합니다.
- node.js의 개념, 특징, 동기, 비동기에 관해 다뤄보려 합니다.
- node.js는 흔히 이야기 하는 single thread, non blocking I/O 방식으로 작동됩니다.
node.js 개념
- node.js 란 Javascript 의 back-end runtime 으로 Javascript 가 구동되는 환경을 말한다.
- 이는 사용되는 언어가 node.js가 아닌 Javascript 라는 것을 말합니다.
- Javascript 는 원래 front-end 인 브라우저에서만 작동하지만 node.js 를 통해 백엔드에서도 자바스크립트를 사용할 수 있게 해줍니다. 또한 다른 여러가지 장점을 얻을 수 있으며 아래에서 설명합니다.
백엔드 & 프론트엔드 동일한 언어 사용의 장점
- Code Reusability: 동일한 언어를 사용하므로 백과 프론트에서 코드 교환이 가능하므로 서로간 코드를 재사용할 수 있습니다.
- Familiarity: 프론트와 백엔드가 동일한 언어를 사용하므로 비교적 수월하게 다른 진영의 코드를 배우고 사용할 수 있습니다.
- Consistency: 동일한 언어를 사용하므로 인해 전체 프로그램 전반에 걸쳐 일관성 보장에 도움이 됩니다. 동일한 코딩 규칙, 라이브러리 및 프레임워크를 프론트와 백엔드 모두에게 적용할 수 있으며, 이는 앱이 응집력 있고 원할하게 작동하도록 하는 데 도움이 됩니다.
- Better Communication: 동일한 언어를 사용하므로 같이 일하는 집단의 의사소통을 좀 더 원할하게 만들어 주며 더 나은 협업을 이루어 내도록 도와줍니다.
- Performance: 서버와 클라이언트 간에 전송해야 하는 데이터의 양을 줄여 페이지 로드 시간이 빨라질 수 있습니다.
V8
- Javascript 는 원래 브라우저에서만 작동했으며 각 브라우저마다 Javascript 언어를 실행하는 엔진이 존재합니다.
| 브라우저 | 엔진 |
|---|
| Chrome | V8 |
| IE | Chakra |
| Firefox | Spider monkey |
| Safari | JavaScriptCore |
- node.js 는 V8 엔진을 사용하며 해당 엔진은 코드를 해석하는데 compiler 와 interpreter 두가지 모두를 사용합니다.
- 이로인해 interpret 언어인 JavaScript 의 단점을 극복해 더 나은 효율성과 퍼포먼스를 자랑합니다.
- V8 엔진이 작동하는 방식을 알려면 compile 과 interpret 가 어떤 방식인지 알아야 하며 아래에 설명합니다.
compile & interprete
- 인간이 현대에 작성하는 프로그래밍 언어는 대부분 high-level 언어이며 이러한 source code 는 기계가 읽고 실행할 수 있는 low-level 언어로 해석이 필요합니다. source code 를 실행하는 방법은 크게 두가지가 있으며 이를 compile(컴파일) 또는 interpret(인터프리트) 라고 합니다.
- compile: 컴파일러가 프로그램 실행 전 전체 source code 를 한번에 machine code 로 변환 후 실행 가능한 파일을 만든 뒤 프로그램을 실행합니다. 이때 source code 를 machine code 로 변환하는 과정을 컴파일 이라고 합니다.
- machine code 는 low-level 코드로 2진법으로 구성되어 있습니다. 기계 입장에서 이해 가능한 언어로 바로 실행 가능하며 이는 매우 효율적입니다.
- 컴파일 언어의 대표적인 예: C, C++
- interprete: 인터프리터가 코드를 전체가 아닌 한줄 단위로 byte code 로 변환 후 즉시 실행합니다.
- byte code: 소프트웨어 프로그램인 인터프리터에 의해 실행되도록 만들어진 코드 이며 인터프리터는 이를 실행 후 저장하지 않고 버립니다. 따라서 인터프리터는 다음 코드를 만난다면 전과 내용이 같더라도 같은 작업을 반복해 실행하기 때문에 일반적으로 컴파일 언어보다 간단하지만 느립니다.
- 인터프리터 언어의 대표적인 예: Python, Javascript, Ruby
- 컴파일 언어는 코드를 실행하기 전에 compile 단계를 거치므로 인터프리터 언어보다 준비되는 시간은 오래 걸리지만 한번 컴파일된 machine code 는 기계가 바로 실행할 수 있으므로 엄청난 시간 단축을 가져옵니다.
- node.js 는 Google 에서 만든 Chrome 브라우저의 V8엔진으로 작동합니다.
- V8 엔진은 위에서 설명한 compiler 와 interpreter 의 장점을 합쳐 사용합니다.
- V8 엔진은 초기 실행시에는 인터프리터를 이용해 source code 를 byte code 로 변환해 실행하며 이와 동시에 자주 사용되는 코드와 패턴을 파악합니다. 이를 찾으면 Turbofan 이라는 컴파일러를 이용해 해당 byte code 를 machine code 로 컴파일 합니다.
- 위 과정을 Just-In-Time (JIT) compilation 이라고 합니다(프로그램을 실행하는 시점에서 필요한 부분을 컴파일 하는 방식).
- V8 엔진이 다른 Javascript 엔진 보다 뛰어난 이유입니다.
작동방식
- 흔히 이야기 하는 node.js 는 single thread, non-blocking I.O 에 관해 알아보도록 하겠습니다.
- node.js 는 크게 event loop, event queue, call stack 으로 구성되어 있으며 특정 상황에 O/S kernel 에 작업을 위임합니다. 지금부터 이를 알아보도록 하겠습니다.
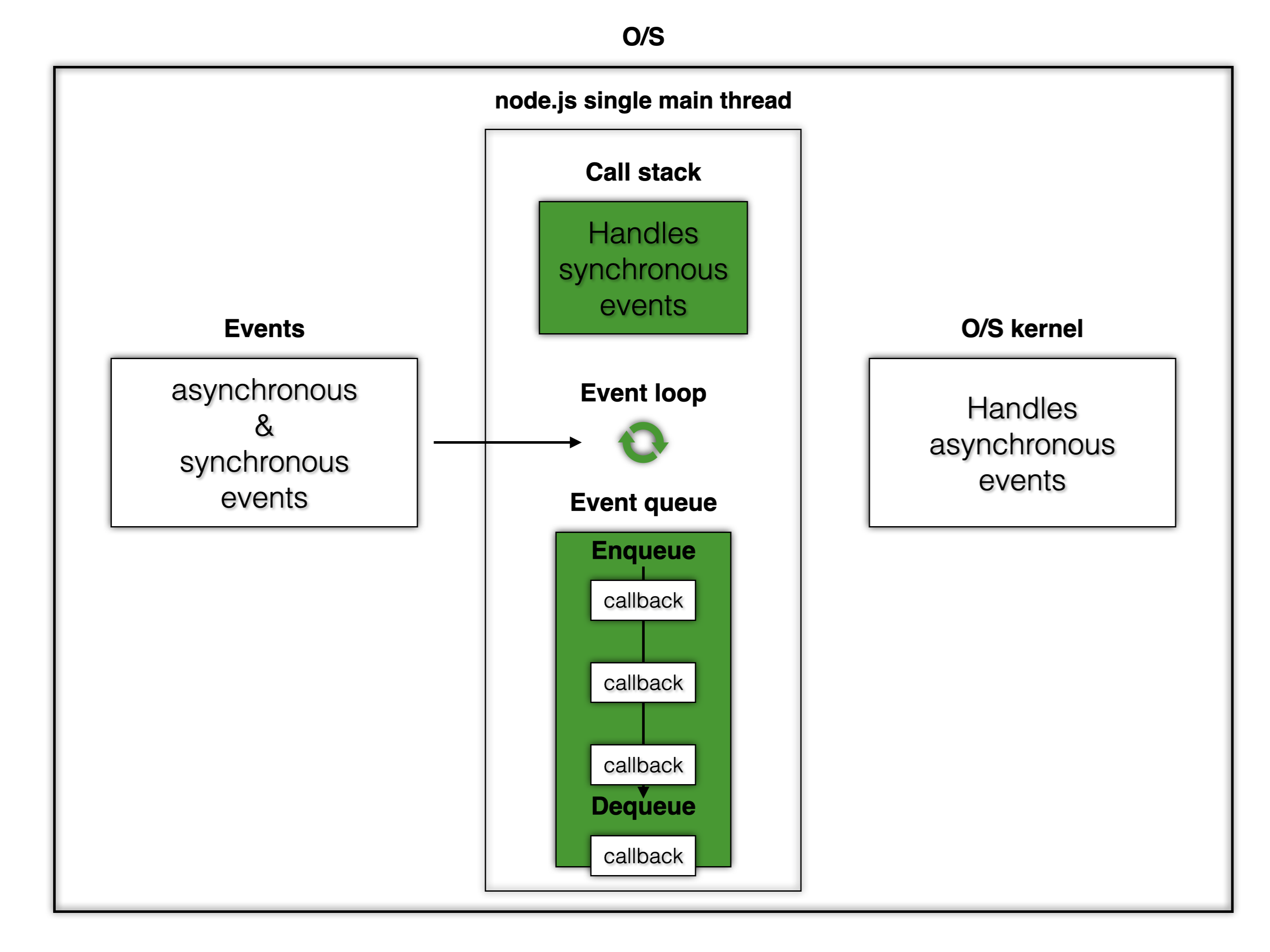
single thread: node.js 는 싱글 스레드로 구성되어 있으며 이 스레드는 main thread 라고도 불리웁니다. 또한 해당 스레드가 아래 설명에 나올 event loop 과 call stack 을 관리합니다. event loop: 이벤트 루프는 node.js 에서 제일 중요한 역할이며 프로그램이 실행되면 event loop 는 이벤트가 발생하기 까지 대기(listening)상태에 들어갑니다. 이벤트가 발생하면 event loop 는 해당 이벤트가 synchronous(동기) 이벤트인지 asynchronous(비동기) 이벤트인지 판별 합니다.
synchronous 이벤트이면 call stack 으로 해당 이벤트를 push 하며 만약 해당 동기 이벤트가 callback 함수를 가지고 있다면 callback 을 event queue 에 queue 합니다.asynchronous 이벤트이면 O/S kernel 에게 해당 작업을 위임합니다.
call stack: 따라서 call stack 은 위의 두가지 이벤트 타입중 synchronous(동기) 작업만 수행합니다. call stack 은 event loop 에 의해 push 되어진 이벤트를 실질적으로 수행하는 역할을 하며 이는 node.js V8 엔진의 single thread 에 의해 이루어 집니다. 따라서 해당 작업이 이루어 지는 동안 같은 thread 를 사용하는 event loop 는 자동으로 blocked 됩니다.
- 이는 event loop 이 call stack 이 수행하는 작업이 완료되거나 비어지기 까지 확인하고 있음을 의미합니다. 절대 event loop 이 멈춰있다는 뜻이 아닙니다.
- The event loop doesn't stop entirely while the call stack is executing a synchronous event. It still checks if the call stack is empty or if a task has been completed.
event queue: event loop 이 만나는 이벤트들 중 callback 함수를 포함하고 있는 이벤트들이 있는데 이 callback 함수들이 event loop 에 의해 enqueue 되어 큐에 들어가게 됩니다. 그리고 처음 이벤트 작업이 call stack 에서 완료될 시 event loop 는 위 설명처럼 blocked 되어 있다가 dequeue 를 통해 event queue 의 callback 을 꺼내 push 를 통해 다시 call stack 에 넣어줍니다.
- 이후 call stack 의 역할대로 작업을 수행하며 이러한 방식을 통해 event loop 는 동기 작업을 수행합니다.
O/S kernel: 따라서 O/S kernel 은 위의 두가지 이벤트 타입중 asynchronous(비동기) 작업만 수행합니다.
- O/S kernel 은 node.js 외부 환경 이므로 event loop 는 계속해서 다른 이벤트를 만날 수 있습니다. 이것이 node.js 를 효율적으로 만들어 주는 비동기 방식 과정입니다.
- O/S kernel 로부터 비동기 작업을 마친 이벤트가 만약 callback 이 있다면 O/S kernel 는 이를 event loop 에게 알리며 event loop 는 해당 callback 을 이때 event enqueue 에 queue 합니다.
- 위 과정을 계속 반복합니다. 이를 요약하자면 아래와 같습니다.
- event loop: 앱 내부에 일어나는 모든 이벤트 그리고 그와 연관된 콜백을 call stack, event queue 그리고 O/S kernel 을 통해 관리합니다.
- call stack: push 되어진 이벤트나 콜백들을 수행합니다. stack 자료구조 이므로 FILO 를 따릅니다.
- event queue: call stack 이 작업을 수행하는 동안 그에 상응하는 callback 이 대기하는 queue 자료구조로 FIFO 를 따릅니다.
- O/S kernel: Asynchronous events(비동기 이벤트)를 관여하며 이는 node.js 환경이 아닌 운영체제로 부터 관리되므로 event loop 는 다른 이벤트를 처리할 수 있습니다.
single thread & non-blocing I/O
- node.js 는 하나의 메인 스레드 즉, singled main thread 를 가지고 있는데 이 스레드가 call stack 과 event loop 를 관리합니다.
- event loop 가 동기 이벤트를 만났을 때 call stack 에게 해당 작업을 수행하도록 하며 그동안 single thread 인 event loop 는 blocekd 상태가 됩니다.
- 하지만 이는 멈춰있는 상태가 아닌 call stack 이 작업을 완료할 때 까지 계속 확인을 하는 상태를 말합니다.
- event loop 가 비동기 이벤트를 만났을 때 O/S kernel 에게 해당 작업을 위임하며 이로인해 event loop 는 non-blocked 상태를 유지할 수 있습니다. 따라서 event loop 는 다른 이벤트를 계속해서 만날 수 있습니다.
- 이로인해 node.js 를 single thread, non-blocking I/O 라고 합니다.
call stack
- 처음에 call stack 은 스택 자료구조인 FILO 을 따른다 해서 아래처럼 잘못 생각했었습니다.
console.log('1');
console.log('2');
console.log('3');
- 만약 위처럼 1,2,3 을 출력해 주는 코드가 있다면
| stack |
|---|
| console.log('3') |
| console.log('2') |
| console.log('1') |
- 이런식으로 한줄씩 call stack 에 들어가는게 아닌
- 하나만 들어간 후 console.log('1') 을 실행 후
- 2를 넣은 후 실행합니다. 그 후 같은 방식으로 마지막 3을 넣고 실행합니다.
- 위와 같은 방식으로 인해 우리가 예상한 결과인 1,2,3 이 출력됩니다.
- call stack 을 이해하기 위한 좀 더 정확한 예시는 이것보단 아래와 같습니다.
function myFunction3() {
console.log('FEC 3 has been created.');
}
function myFunction2() {
console.log('FEC 2 has been created.');
myFunction3();
}
function myFunction1() {
console.log('FEC 1 has been created.');
myFunction2();
}
myFunction1();
- 위의 코드로 stack 이 어떤식으로 일을 처리하는지 알아보겠습니다.
- 예시에서 call stack 에 처음 실행되는 함수인 myFunction1() 이 처음 push 되며 함수 내부의 console.log('1') 를 바로 수행합니다.
| stack |
|---|
| myFunction2() |
| myFunction1() |
- myFunction1() 은 아직 완전히 끝난 상태가 아니므로 pop 되지 않습니다.
- 그 후 myFunction2() 를 만나 stack 에 push 됩니다. 이후 내부의 console.log('2') 를 바로 수행합니다.
| stack |
|---|
| myFunction3() |
| myFunction2() |
| myFunction1() |
- myFunction2() 는 아직 완전히 끝난 상태가 아니므로 pop 되지 않습니다.
- 그 후 myFunction3를 만나 stack 에 push 됩니다. 이후 내부의 console.log('3') 를 바로 수행합니다.
| stack |
|---|
| myFunction3() |
| myFunction2() |
| myFunction1() |
- myFunction3() 내부에 있는 console.log() 를 수행 한 뒤 myFunction3() 가 종료되고 나머지 함수들도 호출된 역순으로 종료됩니다.
- 그 과정은 아래와 같습니다.
| stack |
|---|
| myFunction3() |
| myFunction2() |
| myFunction1() |
| stack |
|---|
| myFunction2() |
| myFunction1() |
- 함수는 1,2,3 순으로 실행되며 그 역순인 3,2,1 순으로 종료됩니다.
- 이론적으로 이를 더 이해하기 위해서는 execution context 에 관해 알아야 하며 이는 다음 게시물에서 좀 더 자세하게 다뤄보도록 하겠습니다.
References

잘 보았습니다. 감사합니다.