APM(Application Performace Monitoring)을 통해 프로젝트 부하 테스트를 진행하던 중 병목 현상이 발생했다.
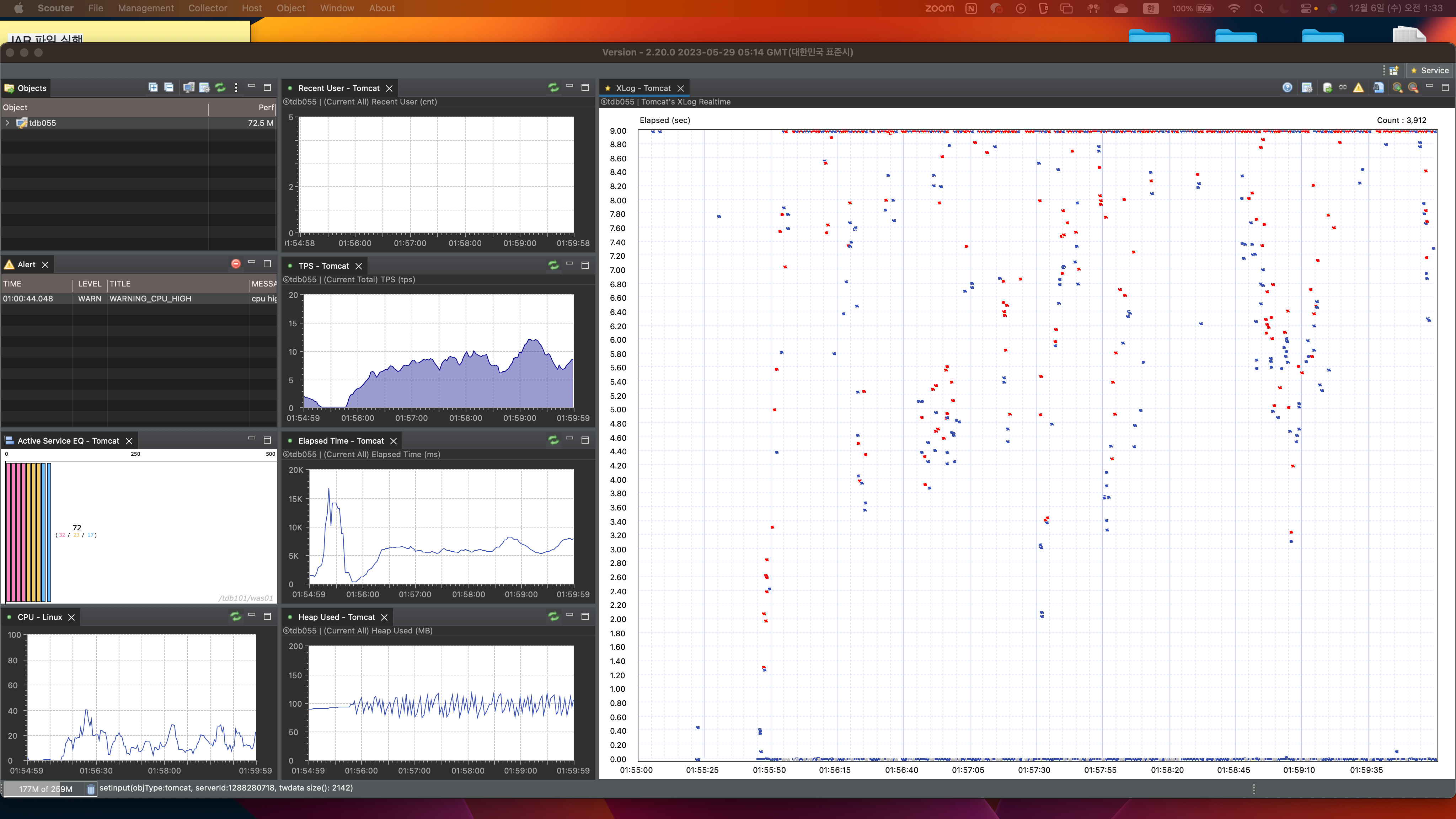
- 초당 100건의 요청을 보낸 결과 (
실전에서 본인이 맡은 부분이 이러면 똥줄 탄다고 한다.) - 빨간색 : 실패
- 파란색 : 성공
현재 WAS와 DB 서버는 각각 1대씩 구성되있다. 다양한 방법을 통해 병목 포인트를 찾았는데, 찾기까지 과정을 서술해보려 한다.
1. Linux TOP 명령어
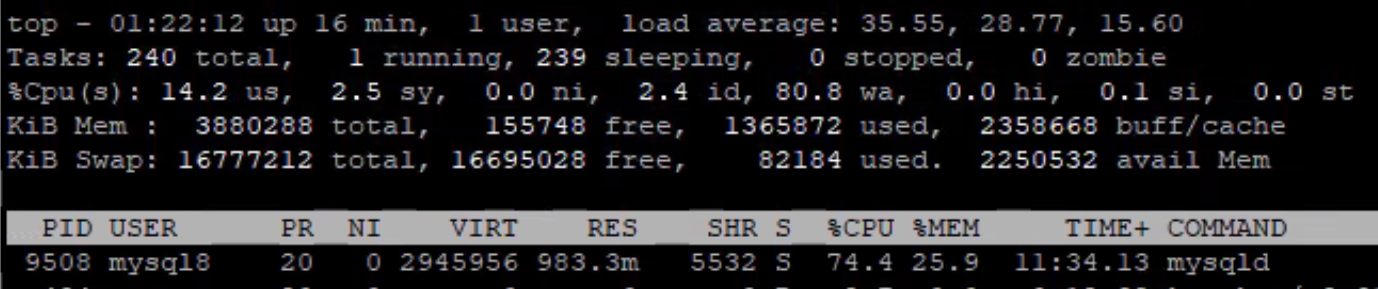
top 명령어를 통해 어플리케이션, DB 서버의 상태를 파악 했다.
어플리케이션 서버

DB 서버
CPU 용어 정리
- us(usage) : 사용자 사용률 + 시스템 사용률
- sy(system) : 시스템 사용률
- ni(nice) : 기본값보다 낮은 우선순위로 사용자 공간에서 실행된 시간
- id(idle) : CPU가 모든일을 끝내고 쉬고 있는 시간
- wa(wait) : 입/출력을 대기하고 있는 시간의 비율
- hi(hard interrupt) : interrupt handler 에서 사용한 시간
- si(soft interrupt) : hard interrupt 에서 처리시간이 오래 걸리는 문제로 미뤄놓은 작업을 수행한 시간
어플리케이션에 비해 DB 서버의 부하가 현저히 많은 걸 알 수 있다.
2. 어플리케이션 서버 로그
2-1. OSError: [Errno 24] Too many open files
처리되지 못한 요청들의 로그를 확인해보니 아래 예외가 발생했었다.

이는 OS의 사용자(계정) 마다 동시에 오픈할 수 있는 파일 개수가 오버됐을 때 발생하는 예외다.
아래 명령어를 실행하면 계정마다 동시에 오픈할 수 있는 파일 개수(file size)를 확인할 수 있다.
ulimit -a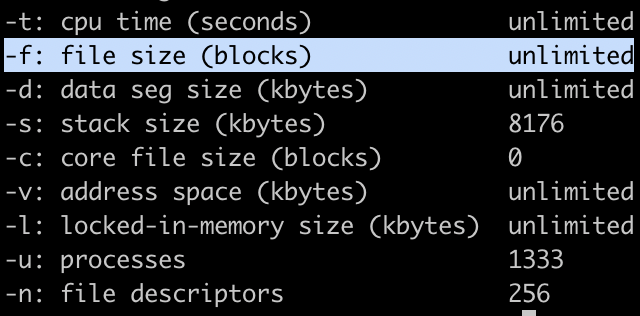
- 현재 서버에는
1024로 설정되있었다.
root 계정으로 접속하여 아래 명령어를 실행하면 계정마다 file size의 권장 수치 및 최대값을 수정할 수 있다.
vi /etc/security/limits.conf
- soft : 권장하는 수치
- hard : 최댓값
2-2. HikariPool-1 - Connection is not available, request timed out after 30000ms
동시에 오픈 할 수 있는 파일 수를 늘리고 부하 테스트를 다시 진행해봤다. 이번엔 DB의 커넥션 풀(Connection Pool)이 문제되었다.
커넥션 풀(Connection Pool)
- JDBC API를 사용하여 DB와 연결하기 위해 Connection 객체를 생성하는 작업. 비용이 굉장히 많이 드는 작업이다.
- org.springframework.transaction.CannotCreateTransactionException: Could not open JPA EntityManager for transaction
- Unable to acquire JDBC Connection
- HikariPool-1 - Connection is not available, request timed out after 3005ms.
- o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 0, SQLState: null도로를 생각해보자. 차가 천천히 간다면 많은 차선이 필요하지만, 차가 빠르게 지나간다면 2차선 정도로도 충분할 것이다.
차가 원할하게 간다면(쿼리 속도가 적당) 차선(커넥션 개수)를 늘려줘야 하지만, 느리게 간다면 차선보단 차 속도를 개선(SQL 튜닝)해야 한다.
차가 느린건지 아니면 차선이 부족한건지 확인해보기 위해 일단 차선(커넥션 풀) 개수를 늘려봤다.
스프링 부트 application.properties 기준 다음과 같이 최대 커넥션 풀 개수를 수정할 수 있다.
spring.datasource.hikari.maximum-pool-size=30그 외) CPU 코어 개수 추가
커넥션 풀 개수를 수정해도 병목 현상은 여전했다. CPU 코어 수를 기존 1개 -> 4개로 수정하고 다시 진행했다.
DB 서버 CPU 대기 시간(wa)은 줄었으나 병목 현상이 해결되진 않았다.
(기존 90 ~ 100 -> 70 ~ 80)
3. 결론 : SQL을 튜닝하자
여러 과정을 걸쳐 병목 포인트를 찾을 수 있었다. 물론, 하드웨어적인 부분이나 리소스를 더 좋게 세팅하여 이를 해결할 수 있으나, 발생하는 비용을 고려했을 때 좋은 선택은 아니라고 판단했다.
2-2 과정처럼 커넥션 풀을 늘리고 커넥션마다 SQL 실행 시간을 확인하여 특정 SQL에 대한 튜닝을 진행하는게 제일 좋은 선택지라고 결론을 내렸다.
만약, 데이터에 대한 변경이 적다면 Redis 등의 캐시를 도입하는 것도 좋은 대책이라고 판단된다.
마무리
어플리케이션 위의 서비스 보단 DB가 부하 테스트에서 더 결정적으로 작용함을 알 수 있었다.
이처럼 어플리케이션에서 설정할 수 있는 건 한정적이다. 연관된 것들을 모두 고려해야 된다. 즉, 연관된 것(ex. OS)들을 크게 볼 수 있는 역량이 있어야 한다. 이를 위해선 CS에 대한 기본 지식이 필수적이라 생각한다.
최초 DB 서버 CPU 개수는 1개로 시작하여 코어 개수를 추가하는 식으로 진행했는데 실무에서도 이처럼 CPU를 최소한으로 붙이고 이를 점점 늘려가면서 진행한다고 한다.
