들어가며
Firebase 는 실시간 데이터베이스와 간편한 백엔드 서비스로 많은 개발자들의 사랑을 받고 있습니다. 하지만 모든 것이 완벽할 순 없죠. Firebase 를 사용하다 보면 한 가지 큰 벽에 부딪히게 됩니다. 바로 검색 기능입니다.
문제 상황: Firebase 의 한계
Firebase 는 기본적으로 완전 일치 검색만을 지원합니다. 예를 들어, " 안녕하세요 " 라는 데이터가 있다면 " 안녕 " 으로는 검색이 불가능합니다. 이는 사용자 경험을 크게 저하시키는 요인이 되죠.
그렇다면 이 문제를 어떻게 해결할 수 있을까요? 여기 제가 삽질 끝에 찾아낸 해결책을 소개합니다.
해결 방안: 키워드 생성 전략
문제 해결의 핵심은 다음과 같습니다:
- 검색 가능한 모든 키워드 조합을 미리 생성
- 생성된 키워드를 배열로 저장
- 배열에 포함된 키워드로 검색

이제 이 방법을 구현하는 코드를 자세히 살펴보겠습니다.
구현 코드 상세 분석
1. 텍스트 정제 함수
먼저, 입력된 텍스트를 검색에 적합한 형태로 변환하는 함수를 만듭니다.
export const cleaningText = (text: string): string => {
const regEx = /[`~!@#$%^&*()_|+\-=?;:'",.<>\{\}\[\]\\\/ ]/gim;
return text.replace(regEx, "").toLowerCase();
};이 함수는 특수 문자와 공백을 제거하고, 모든 문자를 소문자로 변환합니다. 이를 통해 "Hello, World!" 와 "hello world" 가 모두 "helloworld" 로 변환되어 일관된 검색이 가능해집니다.
코드 분석:
-
const regEx = /[`~!@#$$$\\/ ]/gim;
- 이 정규표현식은 제거할 특수문자와 공백을 정의합니다.
g: 전역 검색 (모든 일치 항목 찾기)i: 대소문자 구분 없음m: 다중 행 모드
-
text.replace(regEx, "")replace메서드는 정규표현식에 일치하는 모든 문자를 빈 문자열로 대체합니다.
-
.toLowerCase()- 모든 문자를 소문자로 변환합니다.
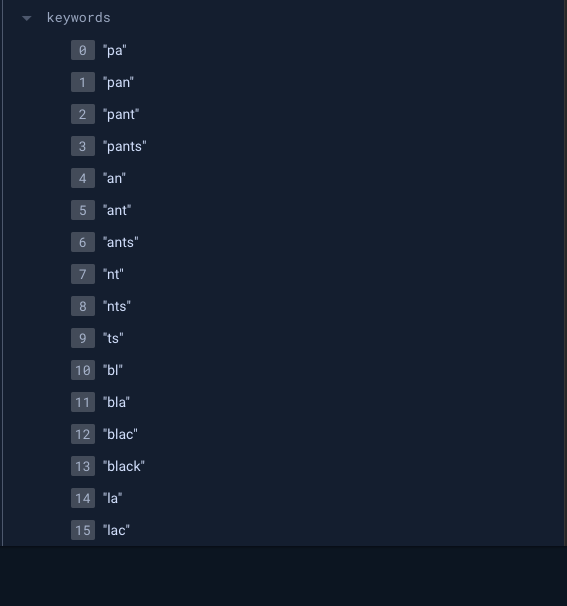
2. 키워드 생성 함수
다음으로, 검색 가능한 모든 부분 문자열을 생성하는 함수를 만듭니다.
export const createKeywords = (texts: string[]): string[] => {
const keywords = new Set<string>();
texts.forEach((text) => {
const cleanText = cleaningText(text);
const length = cleanText.length;
for (let i = 0; i < length; i++) {
let temp = "";
for (let j = i; j < length && j < i + 11; j++) {
temp += cleanText[j];
if (temp.length >= 2) {
keywords.add(temp);
}
}
}
});
return Array.from(keywords);
};이 함수는 입력된 텍스트의 모든 2~10 글자 부분 문자열을 생성합니다. 예를 들어, "hello" 에서 "he", "hel", "hell", "hello", "el", "ell", "ello", "ll", "llo", "lo" 와 같은 키워드가 생성됩니다.
코드 분석:
-
const keywords = new Set<string>();- 중복을 자동으로 제거하는 Set 객체를 생성합니다.
-
texts.forEach((text) => { … })- 입력받은 각 텍스트에 대해 반복합니다.
-
const cleanText = cleaningText(text);- 각 텍스트를 정제합니다.
-
이중 for 루프:
- 외부 루프
for (let i = 0; i < length; i++):
- 모든 가능한 시작 위치를 순회합니다. - 내부 루프
for (let j = i; j < length && j < i + 11; j++):
- 각 시작 위치에서 최대 10 글자까지의 부분 문자열을 생성합니다.
- 외부 루프
-
if (temp.length >= 2) { keywords.add(temp); }- 2 글자 이상의 부분 문자열만 키워드로 추가합니다.
-
return Array.from(keywords);- Set 을 배열로 변환하여 반환합니다.
3. 검색 쿼리 함수
마지막으로, 실제 검색을 수행하는 함수를 구현합니다.
export const getProducts = async (
startAfterDoc: DocumentSnapshot | null,
limitNumber = 10,
filters: any = {},
order: {
field: string;
direction: "asc" | "desc";
} = { field: "name", direction: "asc" }
): Promise<{
products: Product[];
lastVisible: DocumentSnapshot | null;
hasMore: boolean;
}> => {
try {
const productsRef = collection(db, "products");
let productsQuery = query(productsRef);
// 키워드 필터링
if (filters.keywords) {
if (typeof filters.keywords === "string") {
productsQuery = query(
productsQuery,
where("keywords", "array-contains", cleaningText(filters.keywords))
);
} else if (Array.isArray(filters.keywords) && filters.keywords.length > 0) {
productsQuery = query(
productsQuery,
where("keywords", "array-contains", cleaningText(filters.keywords[0]))
);
}
}
// 페이지네이션 및 정렬 적용
if (startAfterDoc) {
productsQuery = query(productsQuery, startAfter(startAfterDoc));
}
productsQuery = query(productsQuery, limit(limitNumber));
const snapshot = await getDocs(productsQuery);
let products: Product[] = [];
snapshot.forEach((doc) => {
products.push({ ...doc.data(), productId: doc.id } as Product);
});
// 클라이언트 측 추가 필터링 (다중 키워드 AND 연산)
if (Array.isArray(filters.keywords) && filters.keywords.length > 1) {
const additionalKeywords = filters.keywords.slice(1);
products = products.filter((product) =>
additionalKeywords.every((keyword: string) =>
product.keywords.includes(cleaningText(keyword))
)
);
}
const lastVisible = snapshot.docs[snapshot.docs.length - 1] || null;
const hasMore = snapshot.docs.length === limitNumber;
return { products, lastVisible, hasMore };
} catch (err) {
console.error(err);
return { products: [], lastVisible: null, hasMore: false };
}
};이 함수는 키워드 필터링, 페이지네이션, 그리고 다중 키워드에 대한 AND 연산을 지원합니다. Firebase 의 쿼리 제한을 우회하기 위해 클라이언트 측에서 추가 필터링을 수행하는 점이 특징입니다.
코드 분석:
-
함수 매개변수:
startAfterDoc: 페이지네이션을 위한 시작 문서limitNumber: 한 번에 가져올 문서 수filters: 검색 필터 (키워드 등)order: 정렬 옵션
-
쿼리 구성:
const productsRef = collection(db, "products"); let productsQuery = query(productsRef);- 'products' 컬렉션에 대한 참조를 생성하고 초기 쿼리를 설정합니다.
-
키워드 필터링:
if (filters.keywords) { if (typeof filters.keywords === "string") { productsQuery = query( productsQuery, where("keywords", "array-contains", cleaningText(filters.keywords)) ); } else if (Array.isArray(filters.keywords) && filters.keywords.length > 0) { productsQuery = query( productsQuery, where("keywords", "array-contains", cleaningText(filters.keywords[0])) ); } }- 단일 키워드의 경우:
array-contains쿼리를 사용합니다. - 다중 키워드의 경우: 첫 번째 키워드로 필터링합니다.
- 단일 키워드의 경우:
-
페이지네이션:
if (startAfterDoc) { productsQuery = query(productsQuery, startAfter(startAfterDoc)); } productsQuery = query(productsQuery, limit(limitNumber));startAfter: 이전 페이지의 마지막 문서 이후부터 쿼리합니다.limit: 결과 수를 제한합니다.
-
결과 처리:
const snapshot = await getDocs(productsQuery); let products: Product[] = []; snapshot.forEach((doc) => { products.push({ ...doc.data(), productId: doc.id } as Product); });- 쿼리를 실행하고 결과를 Product 객체 배열로 변환합니다.
-
클라이언트 측 추가 필터링:
if (Array.isArray(filters.keywords) && filters.keywords.length > 1) { const additionalKeywords = filters.keywords.slice(1); products = products.filter((product) => additionalKeywords.every((keyword: string) => product.keywords.includes(cleaningText(keyword)) ) ); }- 다중 키워드의 경우, 클라이언트 측에서 추가 필터링을 수행합니다.
every메서드를 사용하여 모든 키워드가 포함된 제품만 필터링합니다.
-
반환 값:
const lastVisible = snapshot.docs[snapshot.docs.length - 1] || null; const hasMore = snapshot.docs.length === limitNumber; return { products, lastVisible, hasMore };products: 필터링된 제품 목록lastVisible: 마지막으로 반환된 문서 (다음 페이지 쿼리에 사용)hasMore: 더 많은 결과가 있는지 여부
사용 방법
이제 이 기능을 어떻게 사용하는지 살펴보겠습니다:
- 데이터를 저장할 때
createKeywords함수로 키워드 배열을 생성합니다. - 생성된 키워드 배열을 데이터와 함께 Firebase 에 저장합니다.
- 검색 시
getProducts함수를 호출하여 결과를 가져옵니다.
예를 들어, 제품을 저장할 때는 다음과 같이 사용할 수 있습니다:
const product = {
name: "스마트폰",
description: "최신 기술이 적용된 스마트폰입니다.",
price: 1000000
};
const keywords = createKeywords([product.name, product.description]);
await addDoc(collection(db, "products"), {
...product,
keywords: keywords
});검색을 수행할 때는 다음과 같이 사용합니다:
const { products, lastVisible, hasMore } = await getProducts(
null,
10,
{ keywords: "스마트" }
);
console.log(products); // 검색된 제품 목록
console.log(hasMore); // 더 많은 결과가 있는지 여부장단점 분석
이 방법은 Firebase 의 한계를 극복할 수 있지만, 완벽한 해결책은 아닙니다.
장점
- Firebase 의 기본 기능만으로 부분 문자열 검색 구현
- 다중 키워드 검색 지원
- 페이지네이션으로 대량 데이터 처리 가능
단점
- 데이터 중복으로 저장 공간 증가
- 데이터 업데이트 시 키워드 배열도 함께 업데이트 필요
- 대규모 데이터셋에서 성능 저하 가능성
- 클라이언트 측 필터링으로 인한 추가 처리 부담
성능 최적화 팁
-
키워드 길이 제한:
현재 구현에서는 2~10 글자의 키워드를 생성하고 있습니다. 프로젝트의 특성에 따라 이 범위를 조정할 수 있습니다. 예를 들어, 3~8 글자로 제한하면 키워드 수를 줄일 수 있습니다.javascriptif (temp.length >= 3 && temp.length <= 8) { keywords.add(temp); } -
불용어 제거:
"the", "a", "an" 같은 흔한 단어들을 키워드에서 제외하여 저장 공간을 절약할 수 있습니다.javascriptconst stopWords = new Set(["the", "a", "an", "in", "on", "at", "for"]); if (!stopWords.has(temp)) { keywords.add(temp); } -
인덱싱 최적화:
Firebase 에서keywords필드에 인덱스를 생성하여 검색 속도를 향상시킬 수 있습니다. -
캐싱 도입:
자주 검색되는 키워드의 결과를 클라이언트 또는 서버 측에서 캐싱하여 반복적인 쿼리를 줄일 수 있습니다.
확장 가능성
이 방법을 기반으로 더 복잡한 검색 기능을 구현할 수 있습니다:
- 가중치 기반 검색:
제목, 설명 등 필드별로 가중치를 부여하여 더 정확한 검색 결과를 제공할 수 있습니다. - 오타 교정:
Levenshtein 거리 알고리즘 등을 사용하여 간단한 오타를 교정할 수 있습니다. - 자동 완성:
키워드 배열을 활용하여 검색어 자동 완성 기능을 구현할 수 있습니다.
대안 솔루션
프로젝트의 규모가 커지거나 더 복잡한 검색 기능이 필요한 경우, 다음과 같은 대안을 고려해볼 수 있습니다:
- Algolia:
Firebase 와 쉽게 통합할 수 있는 강력한 검색 엔진입니다. 복잡한 쿼리와 실시간 검색을 지원합니다. - Elasticsearch:
대규모 데이터셋에 적합한 분산형 검색 엔진입니다. 풍부한 기능을 제공하지만, 설정과 관리가 복잡할 수 있습니다. - Firebase Extensions:
Firebase 에서 제공하는 확장 기능 중 검색 관련 솔루션을 활용할 수 있습니다.
마치며
Firebase 로 검색 기능을 구현하는 과정은 쉽지 않았지만, 이 방법을 통해 만족스러운 결과를 얻을 수 있었습니다. 물론, 프로젝트의 규모가 커지거나 복잡한 검색 요구사항이 생긴다면 앞서 언급한 대안 솔루션을 고려해볼 필요가 있습니다.이 글에서 소개한 방법은 완벽한 해결책은 아니지만, Firebase 의 한계를 창의적으로 극복하는 방법을 보여줍니다. 개발 과정에서 마주치는 문제들을 해결하는 과정은 때로는 힘들지만, 그만큼 성장의 기회가 되기도 합니다.여러분의 프로젝트에서 이 방법이 도움이 되길 바랍니다. 그리고 여러분만의 창의적인 해결책이 있다면, 꼭 공유해주세요. 우리는 서로의 경험을 나누며 함께 성장할 수 있습니다.
참고 자료
- Firebase 공식 문서: 전체 텍스트 검색
- Firebase 웹 파이어스토어 검색 기능 구현하기
- Algolia 공식 웹사이트
- Elasticsearch 공식 웹사이트
- [Firebase 웹] 파이어스토어 검색 기능 구현하기(feat. 쿼리문 & Algolia)
이 글이 Firebase 에서 고군분투하고 계신 개발자 여러분께 도움이 되었기를 바랍니다. 여러분의 경험이나 추가 팁이 있다면 댓글로 공유해주세요. 함께 성장하는 개발자 커뮤니티를 만들어갑시다!
