자주 사용되는 탐색 알고리즘에 하나로 깊이 우선 탐색, 너비 우선 탐색이 있다. 코딩 테스트 준비를 하면서 꼭 알아야 할 알고리즘이라고 생각되는데 이름과 쓰임이 헷갈린다 흔히 깊이 우선 탐색은 BFS, 너비 우선 탐색은 DFS로 불린다. 이 두가지를 알기 위해서는 스택, 큐, 재귀함수에 대해서 알아야한다. 스택과 큐에 대해서는 이전에 다뤘다.(링크 참고) 그래서 다루지 않았던 재귀함수에 대해서만 간단히 다루고 넘어가겠다.
-
재귀함수
재귀함수란 함수에서 자기 자신을 다시 호출해 작업을 수행하는 함수이다. 이런 방식이기에 특정 분기까지 반복해서 작업해야 할 때 사용한다. 지속적인 작업으로 인해서 함수가 호출되고 그로 인해 지역변수, 매개변수, 반환값을 모두 저장해야 해서 반복문에 비해 메모리를 많이 사용하게 되고 이로 인해 속도 저하가 발생한다. 재귀함수의 주의사항으로는 재귀함수에 종료조건을 설정해야 한다. 그렇지 않으면 함수를 계속해서 호출하게 되고 stack overflow문제가 발생한다. 그리고 종료조건이 없으면 무한 반복문이 되니까 종료조건을 설정 해야한다. -
깊이 우선 탐색 : Depth First Search = DFS
하나의 경우에 대하여 모든 경우의 수를 조사하고 다음 경우의 수를 조사하면서 해를 찾는 과정이다. 내가 이해한 바로는
예를 들어 미로찾기에서 한 방향으로 계속해서 간 후에 갈 곳이 없게되면 가장 가까운 갈림길에서 다시 가는 방법이다. 따라서 모든 노드를 방문하게 된다. BFS보다 간단하게 구현이 가능하다. 하지만 탐색 속도는 느리다.
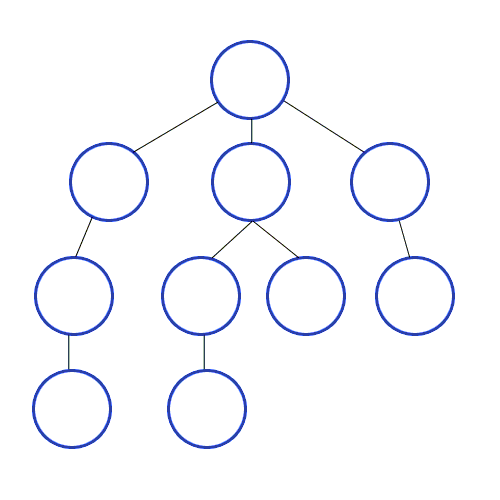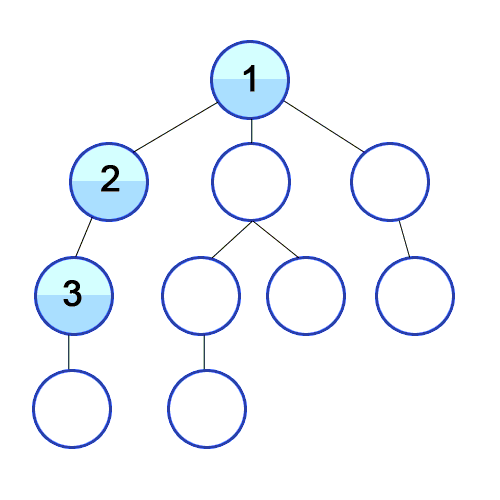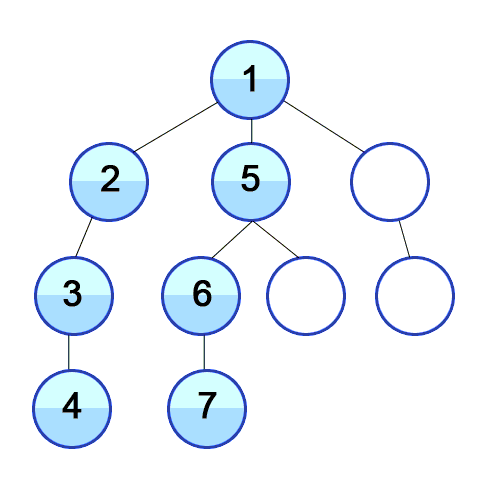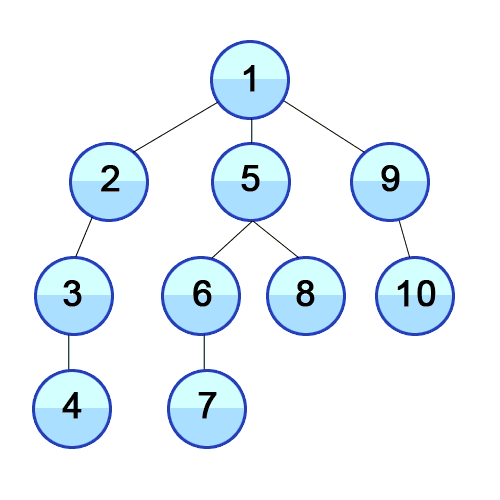
-
스택으로 구현 (재귀함수)
Step 1 : 탐색 시작 노드를 스택에 넣고 방문처리한다.
Step 2 : 스택에 최상단 노드(가장 나중에 방문한 노드)에 방문하지 않은 노드가 있으면 스택에 넣고, 최상단 노드는 방문처리한다. 방문하지 않은 노드가 없다면 스택에 최상단 노드를 꺼낸다.
Step 3 : Step 2를 수행할 수 없을 때까지 반복한다. -
대표적인 문제 : 미로찾기(최단경로는 아님), 사이클 확인(순환여부 확인)
- 너비 우선 탐색 : Breadth First Search = BFS
하나의 경우에 대하여 다음 단계의 모든 경우의 수를 조사하면서 해를 찾는 과정이다.
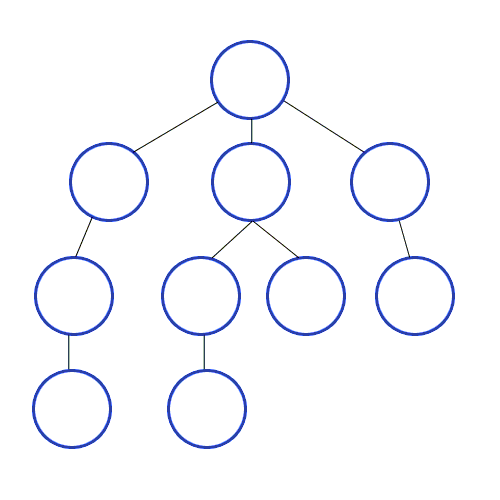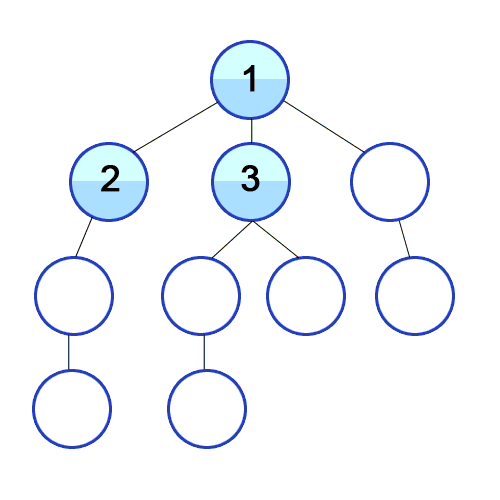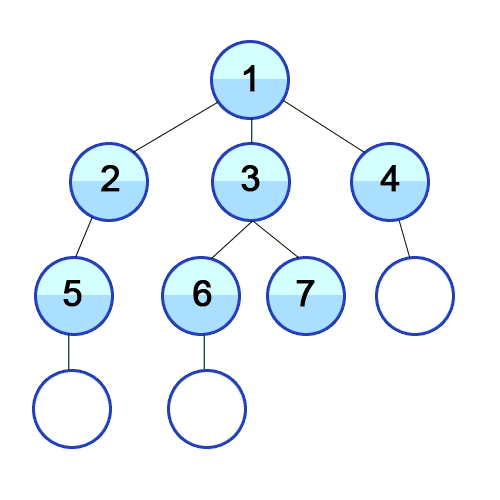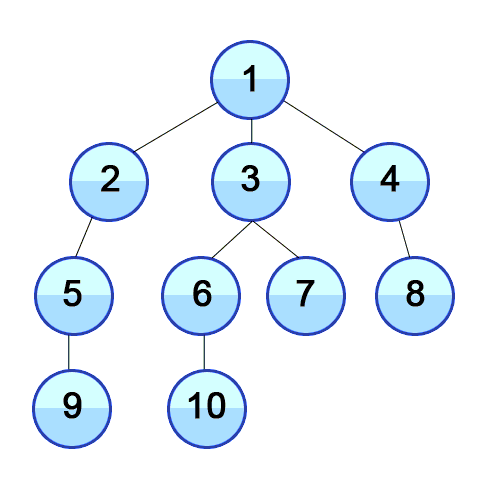
-
큐로 구현
Step 1 : 탐색 시작 노드를 큐에 넣고 방문처리한다.
Step 2 : 큐에서 노드를 꺼낸 후에 해당 노드의 인접 노드를 큐에 넣고 방문처리한다.
Step 3 : Step 2를 수행할 수 없을때까지 반복한다. -
대표적인 문제 : 최단경로
-
시간복잡도
dfs와 bfs 방식은 모든 노드를 검색한다는 점에서 시간복잡도가 동일하다. 방식에 의한 복잡도 차이는 있다. 인접 리스트는 O(N+E), 인접 행렬은 O(N²)의 시간복잡도를 가진다. 일반적으로 E(간선)의 크기가 N²에 비해 상대적으로 적기 때문에 인접 리스트 방식이 효율적이다. -
Code
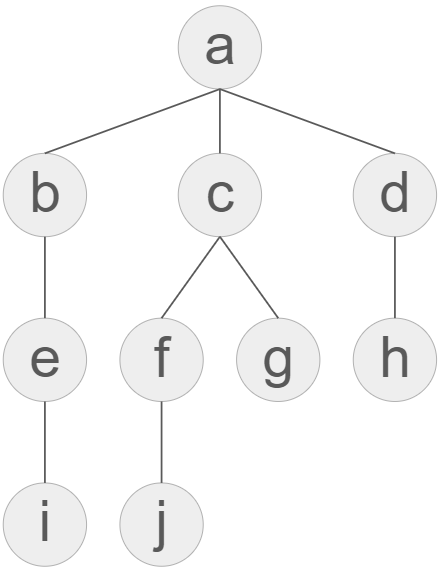
node에 이름을 이렇게 부여했다.
graph = {
'a': ['b', 'c', 'd'],
'b': ['e'],
'c': ['f', 'g'],
'd': ['h'],
'e': ['i'],
'f': ['j'],
'g': [],
'h': [],
'i': [],
'j': []
}
def dfs(start_node, visited_node=[]):
visited_node.append(start_node)
for now in graph[start_node]:
if now not in visited_node:
visited_node = dfs(now, visited_node)
return visited_node
def bfs(start_node):
visited_node = [start_node]
queue = [start_node]
while queue:
now = queue.pop(0)
for next_node in graph[now]:
if next_node not in visited_node:
visited_node.append(next_node)
queue.append(next_node)
return visited_node
print("dfs의 결과: ", dfs('a'))
print("bfs의 결과: ", bfs('a'))출력
dfs의 결과: ['a', 'b', 'e', 'i', 'c', 'f', 'j', 'g', 'd', 'h']
bfs의 결과: ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']