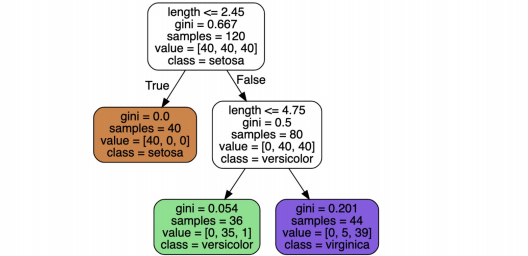
지도 학습
- 학습 대상이 되는 데이터에 정답을 붙여서 학습 시키고, 모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 "답"을 얻고자 하는 것
- 결정나무 모델이 어떻게 데이터를 분류했는지 확인하는 과정
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regioins(X=iris.data[:, 2:], y=iris.target,
clf=iris_tree, legend=2)
plt.show() 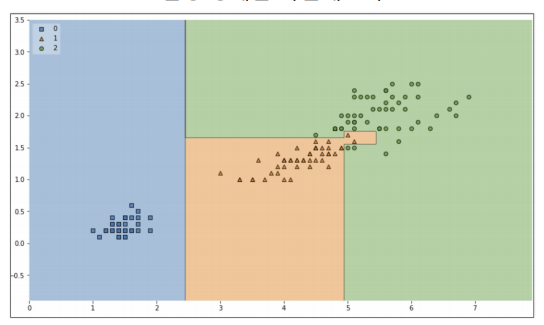
-
Accuracy 확인과정
from sklearn.metrics import accuracy_score y_pred_tr = iris_tree.predict(iris.data[:, 2:]) accuracy_score(iris.target, y_pred_tr)
-
0.99333333 의 값이 나왔다
-
위의 데이터 분석 결과를 일반화할 수 있는지 의문을 가져보아야 한다.
-
일반화 할 때 복잡한 경계면은 모델의 성능을 악화시키기 때문에 데이터 분리 과정이 필요하다.
데이터 분리
확보된 데이터 중 모델 학습에 사용하지 않고 제외한 데이터를 가지고 모델 테스트를 한다.
from sklearn.datasets import load_iris import pandas as pd iris = load_iris()데이터를 훈련 / 테스트로 분리
stratify 옵션은 테스트용 데이터를 동일 비율로 분리되게 해주는 기능from sklearn.model_selection import train_test_split features = iris.data[:, 2:] labels = iris.target X_train, X_test, y_train, y_test = train_test_split(features, labels ,test_size=0.2, random_state=13, stratify=labels import numpy as np np.unique(y_test, return_counts=True)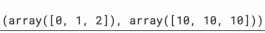
다시 돌아와서, train 데이터만 대상으로 결정나무모델 만들기
일관성을 위해 random_state만 고정, 모델 단순화를 위해서 max_depth 조정할 수 있다.
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassfier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)train 데이터에 대한 accuracy 확인해보기
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(X_train)
accuracy_score(y_train, y_pred_tr)
의사 결정나무 모델 다시 한 번 확인해보기
from graphviz import Source
from sklearn.tree import export_graphviz
Source(export_graphviz(iris_tree, feature_names=['length', 'width'],
class_names=iris.target_names, rounded=True, filled=True))
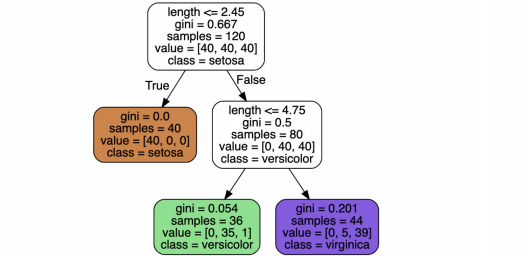
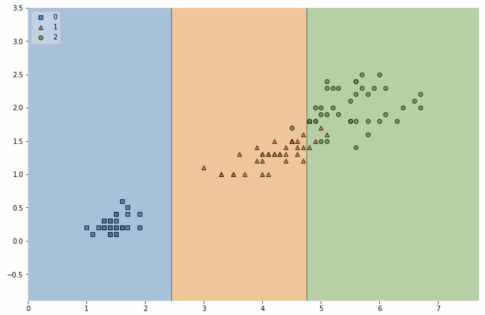
훈련데이터에 대한 결정경계를 확인해보기
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regionis
plt.figure(figsize=(12,8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
plt.show()
테스트 데이터에 대한 accuracy
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)
위의 모델을 사용하는 방법.
ex: iris가 sepal & petal의 length, width가 각각 [4.3,2,1.2,1.0] 이라면
test_data = [[4.3,2.0,1.2,1.0]]
iris_tree.predict_proba(test_data)
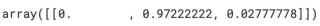
> iris 의 범주 값 및 주요 특성 확인하기
iris.target_names
test_data = [[4.3,2.0,1.2,1.0]]
iris.target_names[iris_tree.predict_proba(test_data)]
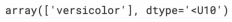
iris_tree.feature_importances_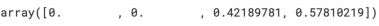
iris_clf_model = dict(zip(iris.feature_names, iris_tree.feature_importance_))
iris_clf_model 
