가상 메모리를 지원하는 핵심 mechanism으로 paging을 활용하면 고성능 오버헤드가 발생할 수 있다.
address space를 고정된 크기로 작게 나누는 paging은 거대한 mapping information을 필요로 한다. 이런 mapping information은 physical memory에 저장되어있기 때문에 paging은 virtual memory를 찾기위한 추가적인 메모리가 필요하다.
따라서 paging이 너무 느리기 때문에 속도를 높일 방법, 추가적인 메모리 참조를 피할 방법이 필요하다.
address translation의 속도를 위해서 translation lookaside buffer(TLB)라는 것이 필요하다.
TLB는 chip의 memory-management-unit(MMU)중 일부이고, 자주쓰이는 virtual-to-physical address translation에 자주쓰이는 하드웨어 cache이다. 그래서 address translation cache라고도 불린다.
 virtual memory참조가 발생하면 하드웨어는 첫번째로 TLB를 확인해서 참조하려는 address가 있는지를 살펴보고 있다면 빠르게 translation을 수행하고 반면에, TLB에 없다면 page table에서 address를 찾고 찾은 address를 TLB에 추가하여 다시 TLB에서 찾는다.
virtual memory참조가 발생하면 하드웨어는 첫번째로 TLB를 확인해서 참조하려는 address가 있는지를 살펴보고 있다면 빠르게 translation을 수행하고 반면에, TLB에 없다면 page table에서 address를 찾고 찾은 address를 TLB에 추가하여 다시 TLB에서 찾는다.
Example: Accessing An Array
예를들어 10개의 int원소를 담는 배열이 virtual address 100(01100100)에서 시작한다고 가정해보자. 그리고 추가적으로 page의 크기는 16byte인 8bit의 virtual space가 있다고 하자. 4bit는 VPN으로 나머지 4bit는 offset으로 활용되어 아래와같은 그림이된다.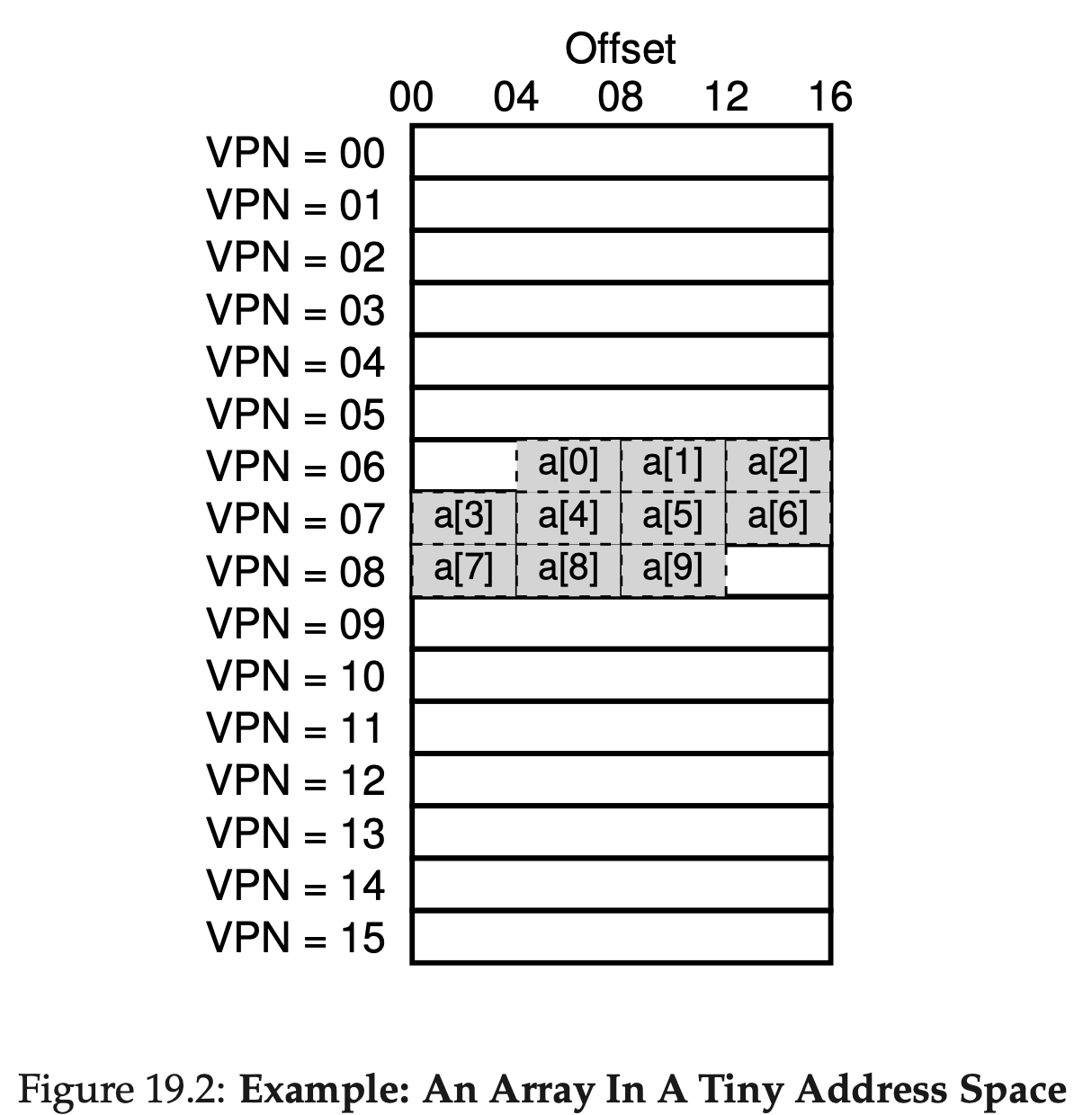 만약 첫번째 array[0]에 접근하는 경우에는 TLB에 아무런 address가 cache되지 않았기 때문에 page table에서 느리게 address를 찾아서 TLB에 추가해야 한다. 하지만 a[1]에 접근할 때는 이미 같은 page가 TLB에 cache되어있으므로 빠르게 TLB에서 address를 찾을 수 있다.
만약 첫번째 array[0]에 접근하는 경우에는 TLB에 아무런 address가 cache되지 않았기 때문에 page table에서 느리게 address를 찾아서 TLB에 추가해야 한다. 하지만 a[1]에 접근할 때는 이미 같은 page가 TLB에 cache되어있으므로 빠르게 TLB에서 address를 찾을 수 있다.
이처럼 TLB를 활용하면 공간적 인접성으로 퍼포먼스의 향상을 기대할 수 있다. 예제에서는 page의 크기가 16byte정도로 매우 작았지만 일반적인 page의 크기는 4KB 정도로 Array based TLB는 매우 효과가 좋다.
Who Handles The TLB Miss?
TLB miss를 다루는 것은 하드웨어일까 OS일까?
예전에는 hardware에 complex-instruction set computer(CISC)를 지니고 있어서 모든 TLB miss를 hardware가 관리하였다(hardware managed TLB).
하지만 요즘날에는 software managed TLB라고 알려진 방식을 사용한다. TLB miss시에 하드웨어는 현재 명령을 멈추고, 커널모드로 들어가서 trap handler로 점프한다. 여기서 trap handler가 OS에 코딩된 내용이다.
return from trap instruction과 return from trap system call은 조금 차이가 있다는 것을 알아야 한다. 후자의 경우 OS로 trap한 이후의(after) 명령을 재개한다. 반면에 전자의 경우 TLB miss hadling trap에서 돌아올 때 다음 명령이아닌 발생시킨(caused) 명령을 이어서 수행해야한다. 그래서 후자는 다시한번 TLB 명령을 수행하게 된다.
그리고 TLB miss handling code를 수행할 때 무한대로 TLB miss가 발생하지 않도록 각별한 주의를 기울여야 한다. 예를들면 TLB miss handler를 physical memory에 유지시키거나, TLB의 일부 항목을 영구적으로 유지시켜서 항상 그 TLB는 hit할 수 있도록 만드는 방식이다.
software managed TLB의 장점은 flexibility이다. 이는 OS로 하여금 하드웨어가 어떻게 변하던 간에 page table에 원하는 자료구조를 사용할 수 있도록한다.
그리고 두번째 장점은 19.1과 software managed TLB인 19.3의 코드를 보면 알 수 있듯이 simplicity이다.
TLB Contents: What's In There?
일반적인 TLB는 fully associative라 불리는 32 혹은 64 또는 128개의 entry를 갖고있다. 기본적으로 원하는 translation은 TLB의 어떤 위치에도 있을 수 있고, 이를 찾기 위해 병렬적으로 모든 TLB를 탐색한다.
TLB entry는
VPN | PFN | other bits위와같은 형태이다. 각각의 entry에는 VPN, PFN이 모두 존재하는데 이는 위에서 언급했듯이 원하는 translation이 TLB의 어떤 위치에도 존재할 수 있기 때문이다.
좀 더 주목해야 할 것은 other bits이다. 일반적으로 TLB에는 valid bit, protection bit가 존재한다. 그밖에도 address-space identifier, dirty bit같은 것들도 존재한다.
TLB Issue: Context Switch
TLB는 현재 프로세스에만 적용되는 virtual-to-physical translation을 갖고 있기 때문에 다른 프로세스에서는 이 translation이 아무 쓸모가 없다. 따라서 하드웨어와 OS는 이전에 사용하던 translation을 현재 프로세스가 사용하지 않도록 해야만 한다. 예를들어 프로세스 P1의 VPN10번이 PFN 100번과 mapping되어있고, P2의 VPN10번은 PFN 170번에 mapping되어있다. 그리고 OS는 P1에서 P2로 context switch를 할 계획이다.
예를들어 프로세스 P1의 VPN10번이 PFN 100번과 mapping되어있고, P2의 VPN10번은 PFN 170번에 mapping되어있다. 그리고 OS는 P1에서 P2로 context switch를 할 계획이다.
두 프로세스 모두 VPN이 10이고 하드웨어는 이를 구분할 수 없기 때문에 문제가 될 수 있다.
첫번째 방법은 context switch시에 TLB를 flush(씻어내다)하여 다음 프로세스가 진행될 때 TLB를 비우는 것이다.
software-managed TLB에서는 명시적인 하드웨어 명령을 통해서 이를 수행할 수 있고, hardware managed TLB에서는 page table base register가 변경될 때 flush가 수행될 수 있다. 두 경우 모두 valid bit을 0으로 만들고 TLB의 내용물을 제거한다.
이렇게함으로써 한 프로세스가 다른 프로세스의 TLB에 접근하지 않도록 만들 수 있지만 context switch가 발생할 때마다 flush를 하게되면 무조건적으로 새로운 프로세스의 code, data영역에선 적어도 한번은 TLB miss가 발생하게된다.
이러한 overhead를 줄이기 위해서, context switch시에 TLB를 공유할 수 있도록 하는 address space identifier(ASID)라는 추가적인 하드웨어를 추가하는 시스템도 있다. 따라서 flush를 하지 않고, ASID를 활용하여 서로다른 프로세스에서 TLB 공유하면서도 구분할 수 있게된다.
따라서 flush를 하지 않고, ASID를 활용하여 서로다른 프로세스에서 TLB 공유하면서도 구분할 수 있게된다.

한편 또다른 예시로 매우 유사한 TLB를 생각해 볼 수 있다. 예를들어 두개의 프로세스가 code영역을 공유하는 경우를 생각해 볼 수 있다.
Issue: Replacement Policy
다른 cache와 마찬가지로 TLB도 cache Replacement에 대해 생각해봐야한다. 특히 새로운 TLB를 추가할 때 예전 TLB를 대채해야한다.
이 문제에 대해서는 page를 disk로 swap할 때 다룰 것이다.
A Real TLB Entry
 MIPS TLB는 32-bit address space, 4KB의 page를 갖고있다. 따라서 우리는 20bit VPN, 12bit offset이 있음을 알 수 있다.
MIPS TLB는 32-bit address space, 4KB의 page를 갖고있다. 따라서 우리는 20bit VPN, 12bit offset이 있음을 알 수 있다.
하지만 위의 그림에서 볼 수 있듯이 실제 VPN은 19bit이다. 절반은 kernel이 사용하는 부분이고 나머지 절반이 유저가 사용하는 address space이므로 19bit만 사용한다고 한다.
그리고 VPN은 최대 24bit의 PFN으로 translate할 수 있으므로 최대 64GB 메모리까지 지원이 가능하다고 한다.
그리고 G라고 쓰여진 global bit는 프로세스가 공유되는 page를 나타낸다. 만약 G가 1로 설정되어있다면 ASID는 무시되고 프로세스가 공유된다.
그런데 만약 8bit 크기의 ASID를 넘어서는 동시에 256개 이상의 프로세스가 동작한다면 어떻게될까...?
우리는 하드웨어에 의해서 page가 어떻게 cache되었는지를 나타내는 3bit 크기의 Coherent bit(C)가 있다. 그리고 page가 다시 쓰여진 적이 있는지 여부를 나타내는 dirty bit(D) 그리고 valid한 translation이 존재하는지 여부를 나타내는 valid bit(V)가 존재한다.
출처 : OSTEP
