참고 영상 - 자바 ORM 표준 JPA 프로그래밍 - 기본편
JPA 데이터 타입 분류
엔티티 타입
- @Entity로 정의
- 데이터가 변해도 식별자(@Id)로 추적 가능
Trasaction commit시에 영속성 컨텍스트에서 데이터의 변화를 감지해서
변경사항이 있다면 update query를 날립니다.
값 타입
- int, Integer, String처럼 값으로 의미를 가지는 객체
- 식별자가 없으므로 추적이 불가(영속성 컨텍스트에서 @Id + Entity type 으로 추적)
- 생명주기를 엔티티에 의존
- 값 타입은 공유 금지!
기본 값 타입
- 기본 타입 (int, double)
- 래퍼 클래스 (Integer, Long)
- String
임베디드 타입
- embedded type, 복합 값
컬렉션 값 타입
- collection value type
임베디드 타입
새로운 값 타입을 정의 가능
주로 기본 값 타입을 모아서 복합 값 타입라고도 합니다.
값 타입과 불변
값 타입 공유 참조
임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 Side effect 발생
임베디드 타입으로 사용중인 객체 타입안의 상태를 변경하면 해당 객체 타입을 사용하는 모든 엔티티들이 동일한 값을 사용하게 됩니다.
객체타입, 배열은 Heap영역에 들어가기 때문에 해당 타입들은
사용에 주의가 필요합니다.
영속성 컨텍스트에 존재하는 영속 객체들 또한 Heap에 존재하는 값이며
영속 객체가 포함하는 값 타입 또한 Heap안에 존재합니다.
Copy method나 불변 객체로 사용하기를 권장합니다.
(Integer, String가 대표적인 불변 객체)
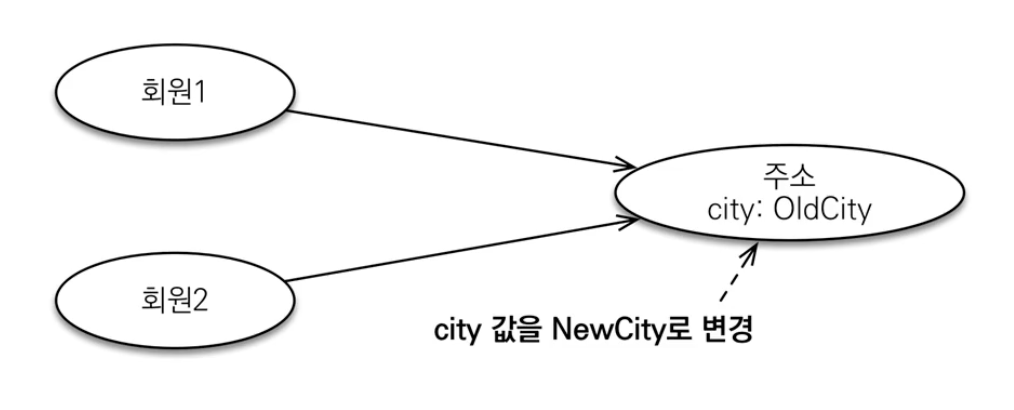
값 타입의 비교
값 타입 : 비교를 참조 값이 아니라 포함하는 값이 같으면 같은 것으로 본다.
값 타입은 동일성 비교(==)가 아니라 동등성 비교(equals)를 해야합니다.
Hash function을 사용하는 것도 고려하여 hashcode()도 함께
재정의하기를 권장합니다.
값 타입(VO)는 hashcode() 재정의도 값들을 기준으로 해야함
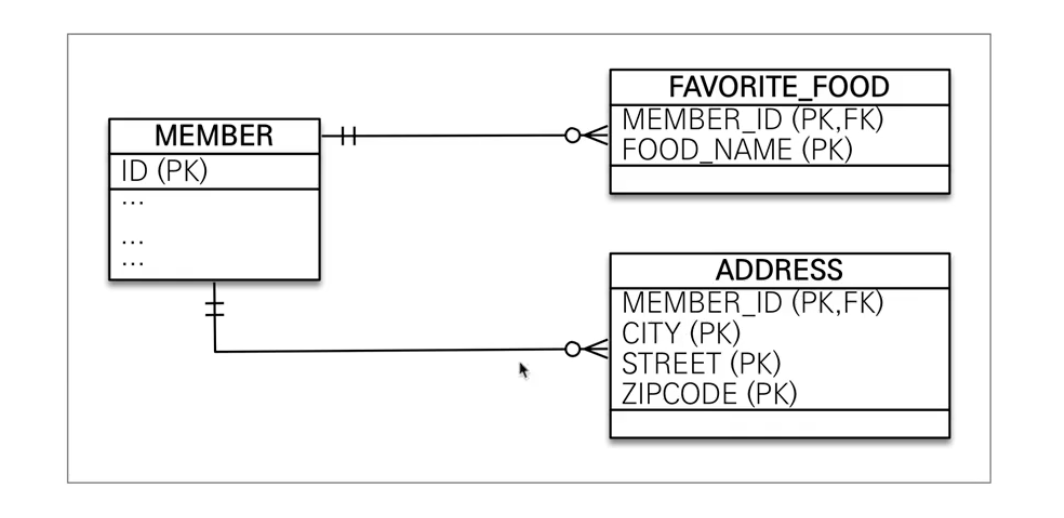
값 타입 컬렉션
값 타입 컬렉션은 아래와 같이 Table로 표현됩니다. ADDRESS를 보면 모든 스키마에 PK가 적용됩니다.
만약 모든 컬럼에 PK가 적용되지 않으면 중복되는 값이 나오게됩니다.
만약에 ID를 추가하게 되면은 값 타입이 아니라 엔티티가 됩니다.
값 타입과 동일하게 불변으로 다루는 것을 권장합니다.
값 타입 컬렉션 룰
- 기본적으로 값 타입 컬렉션에 변경 사항이 발생하면, 주인 엔티티와 연관된 모든
데이터를 삭제하고 새로운 값을 다시 저장합니다. - 기본 키 null 입력 x, 중복 저장 x
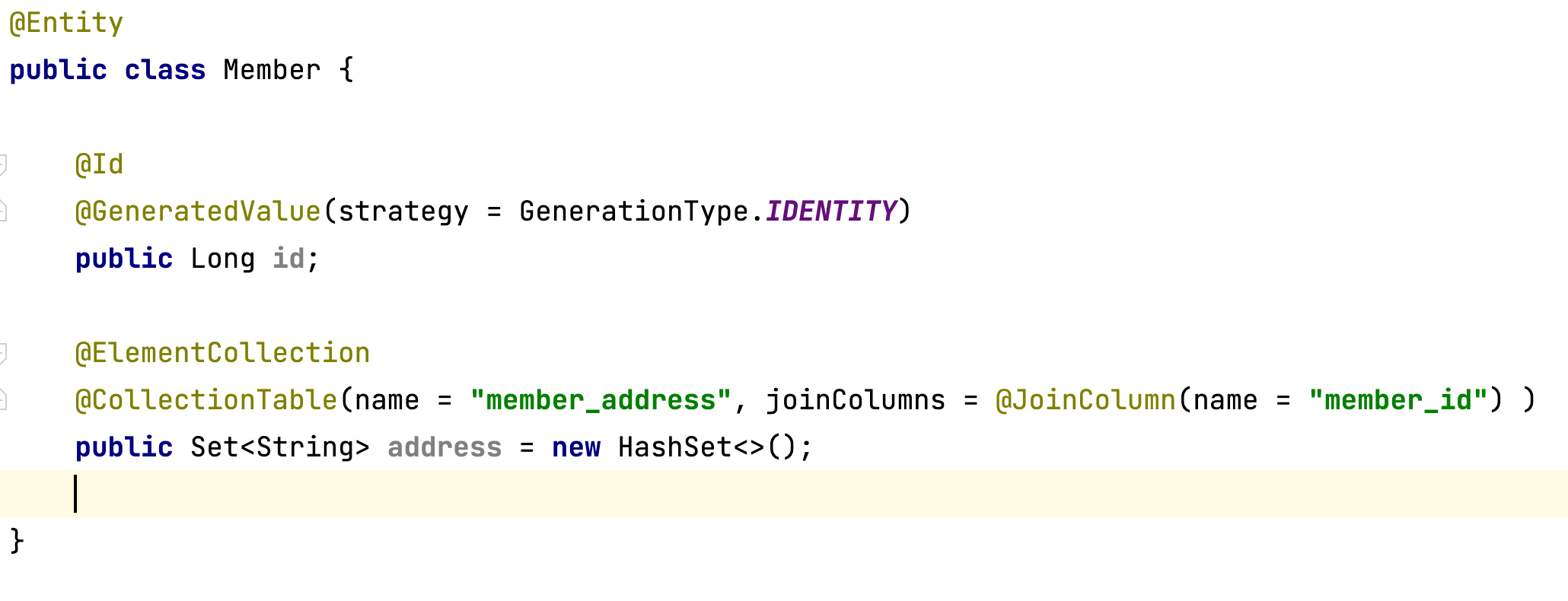
팁
- 값 타입은 영속성 전이 ALL + 고아 객체 제거 기능이 기본 설정입니다.
- 지연 로딩이 기본 전략
- 실무에서는 값 타입 컬렉션 대신 일대다 관계 고려
- 정말 너무 다순한 구조에 사용,

JPQL
엔티티 객체를 조회하는 객체 지향 쿼리
- 검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색
- 모든 DB 데이터를 객체로 변환해서 검색하는 것은 불가능
- SQL을 추상화
- ANSI 표준 문법을 모두 지원
- 엔티티 객체를 대상으로 쿼리
- 결국 SQL로 변환
Criteria & QueryDSL
공통점 : JPQL Builder
📗 Criteria : JPQL Builder
JPQL은 결국 문자열, 동적 쿼리를 생성하기 피곤하다.
하지만 복잡해서 실무에서 사용안함
대안으로 QueryDSL을 많이 사용
📗 QueryDSL : JPQL Builder
그냥 QueryDSL을 사용하자
장점
- SQL과 유사한 구문
- 동적 쿼리 편리함
- 컴파일때 에러를 잡음
JPQL 기본 문법
- 엔티티와 속성은 대소문자 구분
- JPQL 키워드는 대소문자 구분X
- 테이블 이름이 아닌 엔티티 이름
- 별칭 필수 (as 생략가능)
Typed Query, Query
Typed Query : 반환 타입이 명확할 때 사용
Query : 반환 타입이 명확하지 않을 때 사용

결과 조회 API
2개 이상 : getReusltList()
- 결과가 없다면 empty list 반환
1개 : getSingleResult()
- 💀 결과가 없거나 2개 이상이면 예외, Spring Data JPA에서는 편의성을 위해 Optional 제공
간단한 예제
builder형식을 제공하여 편하게 사용 가능

프로젝션
- Select 절에 조회할 대상을 지정하는 것
- 엔티티, 임베디드, 스칼라(숫자, 문자등 기본 데이터 타입)
- 엔티티 프로젝션은 모두 영속성 컨텍스트에서 관리
엔티티 프로젝션: select m From Member m
엔티티 프로젝션: select m.team From Member m
- 유지보수를 위해서는 SQL 문법과 비슷하게
"select t from Member m join Team t"
같은 구문으로 사용하는 것을 권장
임베디드 타입 프로젝션: select m.address From Member m
- 임베디드 타입으로 지정된 값만 VO class로 가져옵니다.
식별자가 없는 값 객체이므로 영속성 컨텍스트에서 관리 X
스칼라 타입 프로젝션: select m.username, m.age From Member m
- Query, Object[], new keyword
3가지 방식으로 값을 매핑이 가능합니다.

new keyword
qlString에 new package.class(args..) 형식으로 추가됩니다.
그리고 조회 컬럼의 타입과 순서에 맞는 생성자가 사용됩니다.


⭐️Fetch Join⭐️
- SQL 조인 종류 X
- JPQL에서 성능 최적화를 위해 제공
- 연관되는 엔티티, 컬렉션을 한 번에 함께 조회하는 기능
일반 Join과의 차이점이라면 일반 Join은 조회의 주체가 되는 Entity의 상태만 조회절에 묶입니다. 그래서 조회절에는 필요없지만 조건절에 필요한 경우 사용이 될 수 있습니다.
Fetch Join은 Join절에 연관된 데이터 모두 조회절에 포함시킵니다.
N + 1의 문제가 발생하였을 때 Fetch Join을 사용하면 문제를 해결 할 수 있습니다.
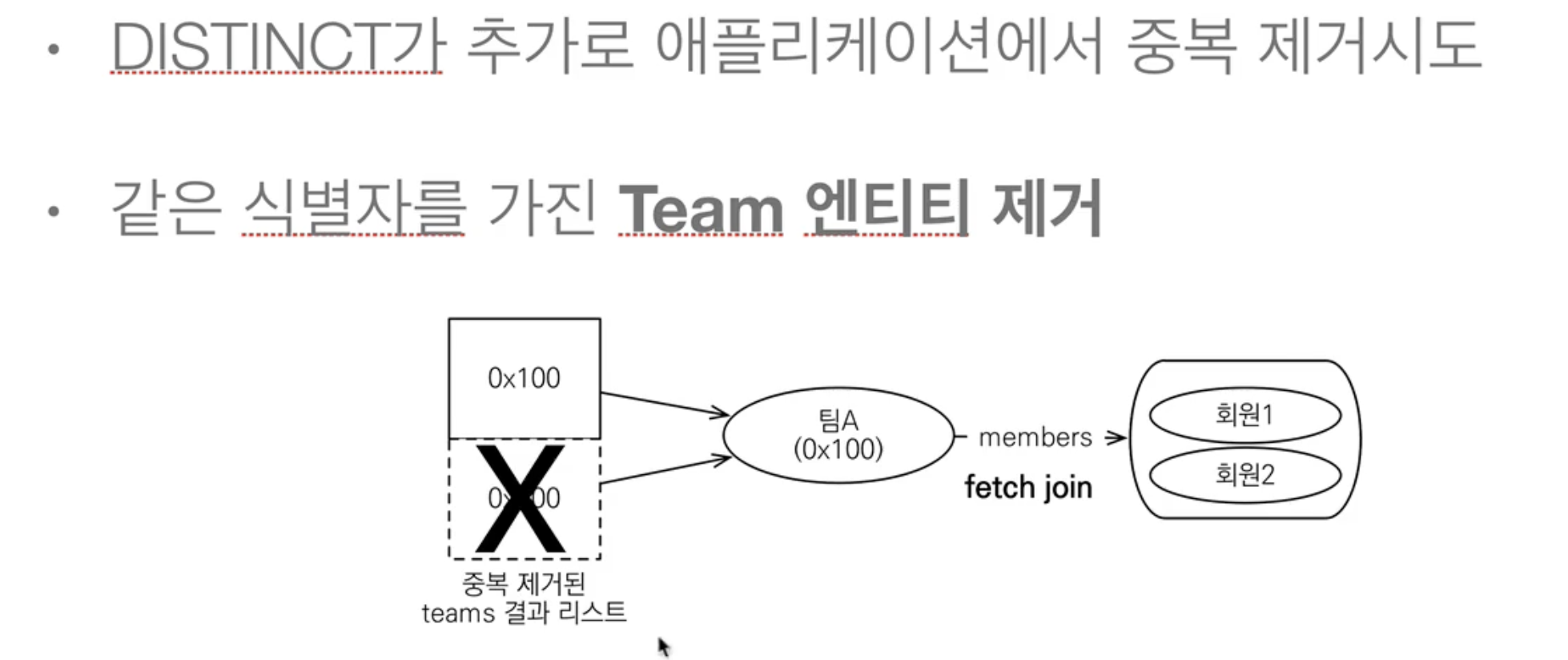
Distinct
.. From Team t Join Member m On t.id = m.team_id ..
실제 DB의 SQL 조회 결과에서는 Team이 2개가 나옵니다.
이러한 부분이 실제 JPA에 적용이 되어서
하나의 Team Instance에 N개의 Member를 참조하는 것이 아니라
Member의 개수만큼 Team이 생성됩니다.
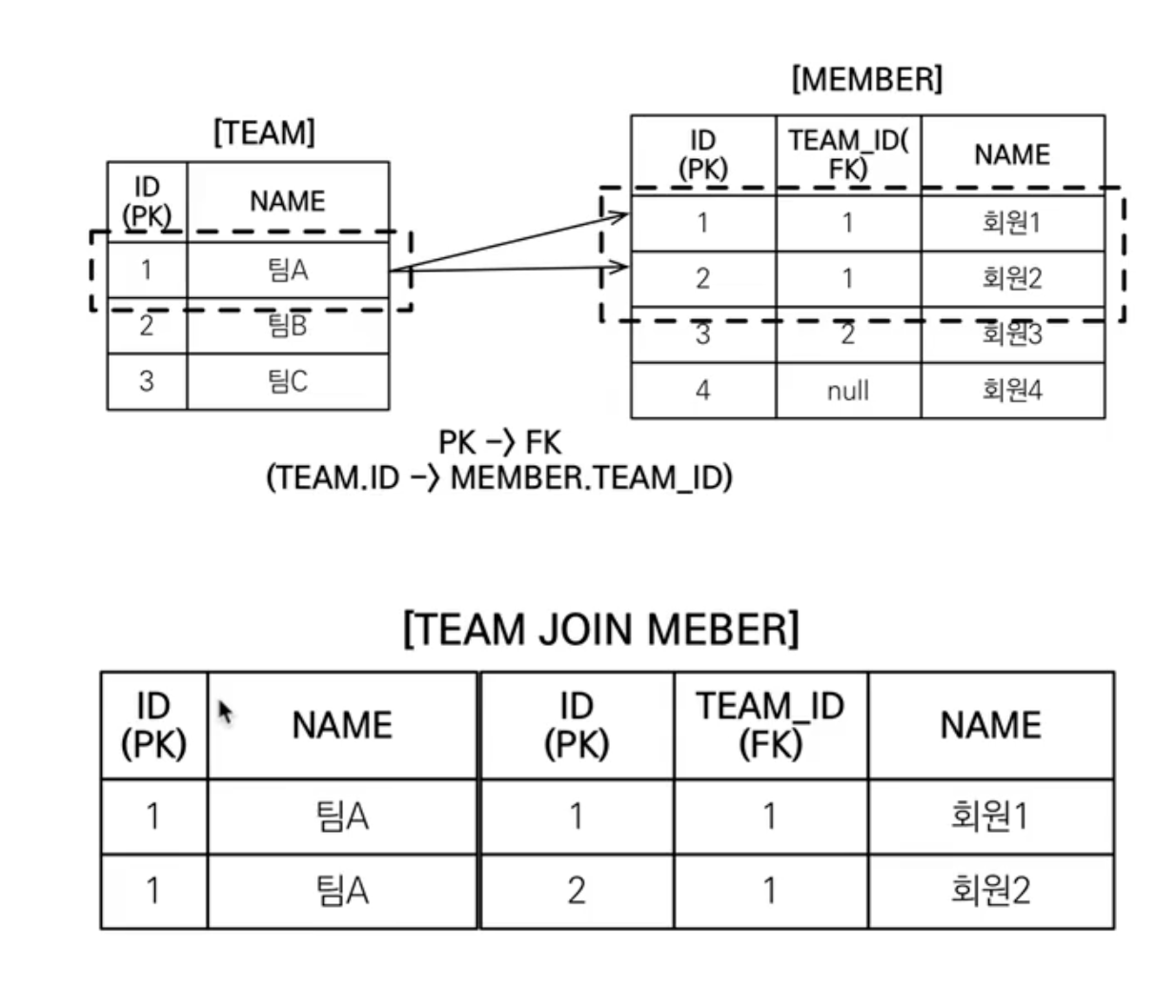
이럴 때 Distinct keyword를 사용하면 됩니다.
JPQL의 Distinct
- Application에서 Entity 중복 제거
- SQL에 Distinct 추가
정리
- JPQL은 결과를 반환할 때 연관관계 고려 X
- SELECT절에 지정한 Entity만 조회
- Fetch Join은 사실상 즉시 로딩을 사용하는 것
- 모든 것을 Fetch Join으로 해결 불가
- 객체 그래프를 유지할 때 효과적
- 여러 테이블을 조인해서 원하는 형태로 결과를 조회해야할 때는
일반 조인 + dto 사용하기
Fetch Join의 한계
- 페치 조인 대상에는 별칭을 줄 수 없다.
- 둘 이상의 컬렉션은 페치 조인 불가
- 컬렉션을 페치 조인하면 페이징 API 사용 불가
a. 1:1, N:1 연관 필드는 페치 조인해도 페이징 가능
b. batch size 사용하기
c. hibernate는 경고 로그를 남기고 memory에서 페이징 (위험)
d. 객체 그래프 탐색에 위배된다.
JPA 서브 쿼리
JPA 표준 스펙에서는 Where, Having절에서만 서브 쿼리 사용 가능하지만
Hibernate 구현체를 사용하면 Select절에서도 사용이 가능합니다.
마지막으로 From절에서의 서브 쿼리가 불가능합니다.
대신 Join으로 풀어야 합니다.
JPQL 타입 표현
문자: 'Hello', 'She''s'
숫자: 10L(Long), 10D(Double), 10F(Float)
Boolean: TRUE, FALSE
ENUM: 패키지명을 포함한 클래스 이름, com.hello.IAmEnum
엔티티 타입: TYPE(m) = Member, 상속 관계에서 사용 가능
기타
SQL과 문법이 비슷
EXISTS, IN, AND, LIKE..
경로 표현식
.(점)을 찍어 객체 그래프를 탐색하는 것
select m.username -> 상태 필드
from Member m
join m.team t -> 단일 값 연관 필드
join m.orders o. > 컬렉션 값 연관 필드
where t.name = '팀A'
1. 상태 필드:
- 단순히 값을 저장하기 위한 필드
- 경로 탐색의 끝, 탐색 X
2. 연관 필드: 연관관계를 위한 필드
단일 값 연관 필드:
- @?ToOne, 대상이 엔티티
- 묵시적 내부 조인 발생, 탐색O
- 쿼리 튜닝이 어렵다.
컬렉션 값 연관 필드:
- @?ToMany, 대상이 컬렉션
- 묵시적 내부 조인, 탐색X
- 명시적으로 Join을 해야 탐색이 가능
- 'size'정도는 탐색 가능
👍 실무에서는 명시적 조인을 사용하자
