개요
이전 글에선 핫스팟 JVM이 사용하는 기반 알고리즘들에 대해서 알아보았다. 이번에는 이러한 알고리즘을 활용하여 구현된 Garbage Collector들에 대해서 알아보려고 한다.
JDK11까지의 컬렉터들
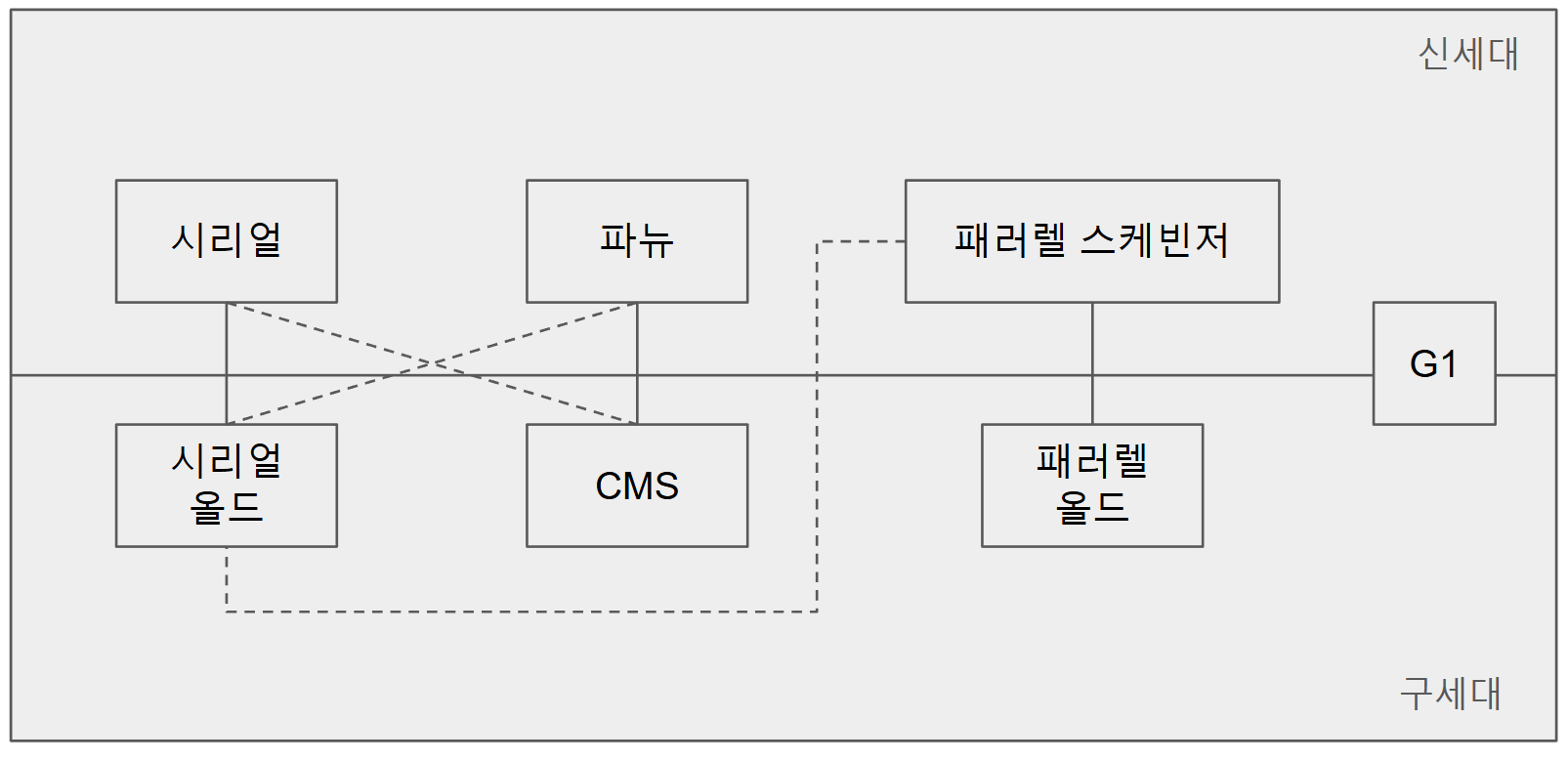
JDK 11까진 신세대 영역과 구세대 영역을 담당하는 컬렉터를 구분하고 이를 조합하여 사용한다. 위 그림처럼 연결된 컬렉터끼리 조합하여 사용이 가능하다. 여기서 중요한 점은 각 컬렉터들은 어플리케이션의 특성에 따라 선택을 하는 것이지 어떤 컬렉터가 더 좋다를 알아보는 것이 아니다.
시리얼 컬렉터
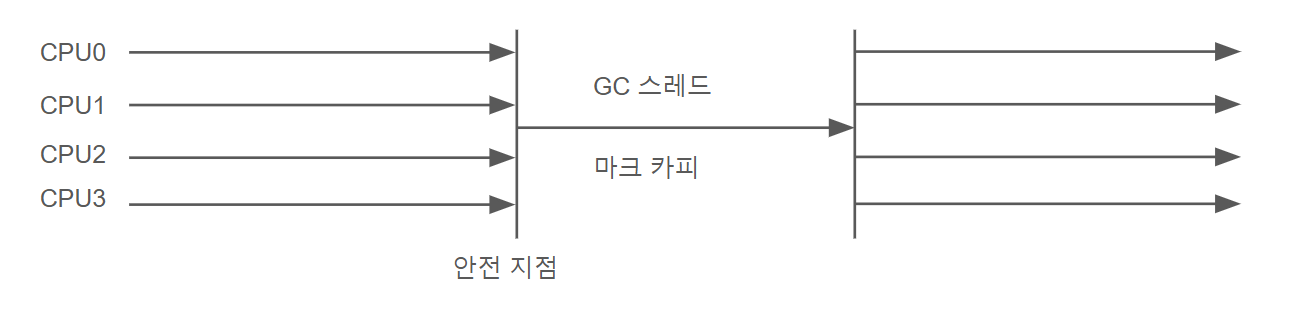
특징: 단일 스레드로 동작하는 GC.
장점: GC 오버헤드가 낮아 작은 애플리케이션이나 단일 스레드 환경에서 유리.
단점: 멀티코어 환경에서는 성능 저하.
사용 사례: 클라이언트 애플리케이션, 테스트용.이름만으로도 누구나 동작 방식을 예상할 수 있는 이 컬렉터는 단일 스레드에서 동작한다. 여기서 단일 스레드 란 단순히 GC 스레드가 하나인 것이 아닌 GC를 하는 동안 GC 스레드만 동작한다는 것이다. 즉 GC를 수행하게 되면 모든 작업 스레드가 멈추는 스탑 더 월드가 발생한다.
파뉴 컬렉터
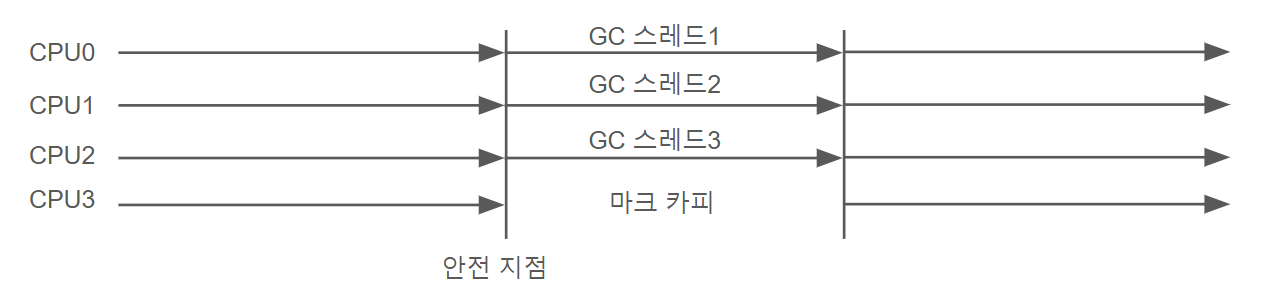
특징: 시리얼 컬렉터의 멀티스레드 버전으로, 신세대를 멀티스레드로 GC.
장점: 멀티코어 CPU를 활용하여 병렬 처리.
단점: 구세대 컬렉터와 호환성 문제로 제한적.
사용 사례: CMS 컬렉터와 함께 사용할 때 효과적.파뉴는 시리얼 컬렉터의 병렬화한 버전으로 회수에 멀티스레드를 사용한다는 점만 제외하면 시리얼 컬렉터와 방식은 완전히 동일하다. 이 컬렉터는 JDK 7전까진 서버 시스템에서 인기가 매우 높았는데 성능적인 부분보단 CMS 컬렉터와 함께 사용할수 있다는 부분에서 인기가 많았다. 이후 이야기 하겠지만 CMS 컬렉터는 핫스팟 역사상 처음으로 진정한 동시성을 지원하는 최초의 컬렉터다.
패러렐 스케빈저 컬렉터
특징: 신세대의 병렬 GC에 중점을 둠.
장점: 전체 처리량 최적화.
단점: 멈춤 시간이 길어질 수 있음.
사용 사례: CPU 리소스를 최대한 활용하는 고처리량 환경.패러렐 스케빈저 컬렉터는 처리량에 최적화된 컬렉터로 사용자 경험보단 CPU의 처리량을 극대화 시킬수 있도록 구현된 컬렉터이다. 이를 위해서 매개변수로 최대 정지 시간과 GC 수행 시간 비율을 제공한다.
이 컬렉터의 특이한 점은 -XX+UseAdaptiveSizePolicy 라는 스위치 매개 변수를 제공하는데 해당 변수를 켜면 신세대의 크기, 에덴과 생존자 공간의 비율 등을 가상 머신이 어플리케이션을 실행하는 동안 정보를 수집하여 최적의 정지 시간과 최대의 처리량을 제공할 수 있도록 동적으로 값을 조율해준다.
시리얼 올드 컬렉터
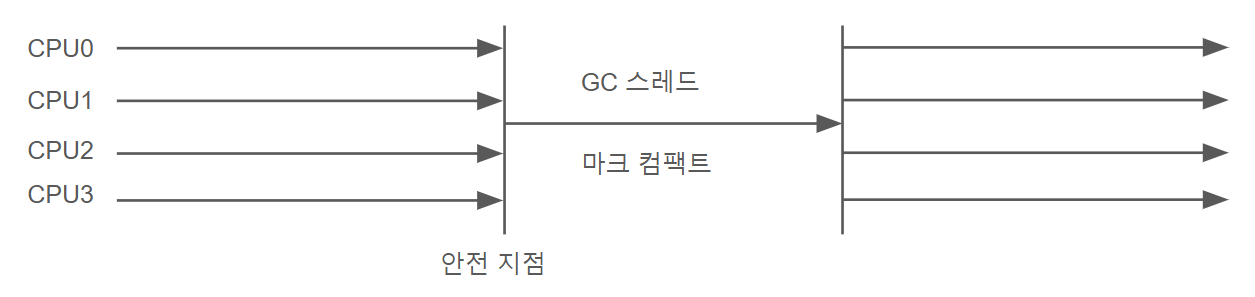
특징: 구세대를 단일 스레드로 처리.
장점: 단순한 구조로 메모리가 적은 환경에 적합.
단점: 멀티코어 환경에서 성능이 제한적.
사용 사례: 시리얼 컬렉터와 함께 사용.시리얼 올드 컬렉터는 시리얼 컬렉터의 구세대용 버전이다. CMS 컬렉터가 실패한 경우 실행되기도 한다. 시리얼 컬렉터와 다른점이라면 시리얼 컬렉터는 마크-카피 알고리즘을 사용하지만 시리얼 올드 컬렉터는 마크 컴팩트 알고리즘을 사용한다.
패러렐 올드 컬렉터
특징: 구세대의 병렬 GC를 지원.
장점: 전체 처리량 최적화.
단점: 멈춤 시간이 길어질 수 있음.
사용 사례: CPU 리소스를 최대한 활용하는 고처리량 환경.패러렐 스케빈저 컬렉터의 구세대용 버전이다. 처리량이 중요하다면 일반적으로 페러렐 스케빈저와 페러렐 올드 조합을 사용한다.
CMS 컬렉터

특징: Stop-the-World 시간을 줄이기 위해 구세대를 병렬로 수집.
장점: 짧은 지연 시간(Low Latency).
단점: 메모리 단편화가 발생할 수 있으며, CPU 리소스를 많이 사용.
사용 사례: 사용자 대기 시간이 중요한 웹 애플리케이션.CMS 컬렉터의 가장 큰 특징은 일부 GC 동작을 사용자 스레드와 동시에 수행하는 최초의 컬렉터라는 점이다. 이름 처럼 마크-스윕 알고리즘을 기반으로 구현되었고 기존에 마크와 스윕 2가지 단계만 수행하던 컬렉터들과 달리 아래의 4단계를 거치게 된다.
- 최초 표시
- 동시 표시
- 재표시
- 동시 쓸기
이 중 1.최초 표시, 3.재표시 단계는 여전히 작업 스레드를 정지시키고 수행된다. 이전 글에서 잠깐 언급했던 동시 접근 가능성 분석이 재표시 단계에서 사용된다. 과거 작업 스레드를 정지시키고 GC를 수행하던 컬렉터와 달리 GC와 작업 스레드가 동시에 수행되기 때문에 작업 스레드에서 참조 관계를 변경한 객체들에 대한 처리가 필요해지기 때문이다.
다만 CMS 컬렉터는 JDK 9에서 deprecated 되고 JDK 14에서 완전히 제거가 된다.
현재의 컬렉터들
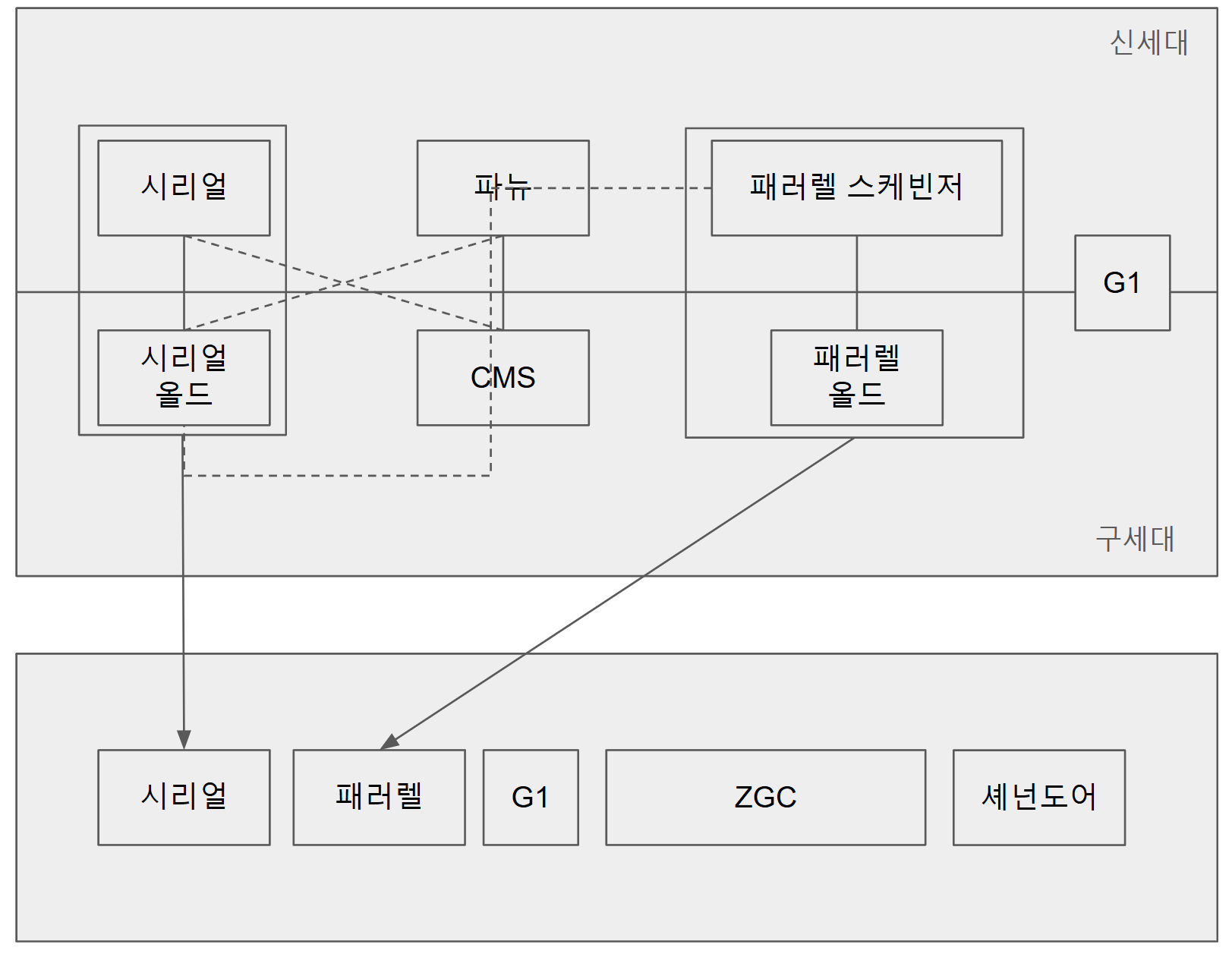
많은 컬렉터들을 살펴보았지만 현재는 많은 컬렉터들이 통폐합되어 위 그림과 같이 남아있다. 더 이상 구세대와 신세대 구분하여 선택하지 않고 하나로 합쳐져서 구성된다. CMS의 경우 G1에게 자리를 완전히 내주었다.
G1 컬렉터
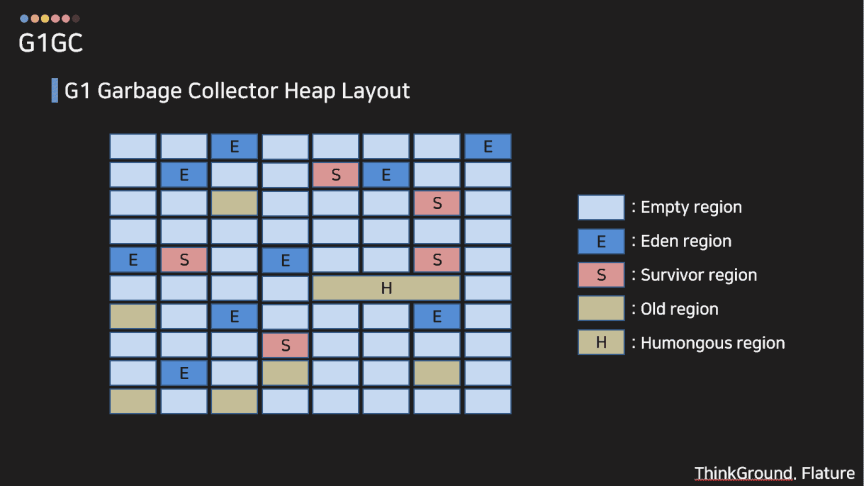
특징: 힙(Heap)을 작은 영역으로 나누어 관리하며, 필요한 영역만 수집.
장점: 예측 가능한 지연 시간(Predictable Pause Time).
단점: 설정이 복잡할 수 있음.
사용 사례: 대규모 애플리케이션, 서버 환경.G1은 그림과 같이 힙을 리전으로 분할하여 관리한다. G1도 기존 컬렉터와 동일하게 세대이론을 따르지만 각 리전들이 동적으로 신세대(에덴, 생존자), 구세대로 변경된다. G1은 제거대상을 리전 단위로 선택하는데 살아남은 객체를 다른 리전 영역으로 복사하고(마크-카피) 기존 리전은 제거한다(마크-컴팩트). 또한 지연 시간을 예측할 수 있도록 하기 위해 사용자가 설정한 예측 시간 내에서 정리할 수 있는 최적의 리전들을 선택하여 작업을 수행한다.
이러한 컨셉을 구현하기 위해 G1에서 해결한 3가지 문제와 사용된 기술을 간략하게 소개한다.
리전 간 참조 문제
기존의 컬렉터들은 신세대와 구세대 간 관계를 확인하기 위한 기억 집합과 카드 테이블을 사용한다. G1도 마찬가지로 리전 간 객체의 참조 여부 확인을 위해 동일한 기술을 사용하는데 리전이 많다보니 전통적인 컬렉터들 보다 메모리를 많이 사용한다.
동시 표기 단계에서 동시성 문제
G1은 동시 표기 단계 수행을 위해 TAMS라는 두 개의 포인터를 설계했다. 리전의 공간 일부가 동시 회수 프로세스를 수행하는 동안 새로운 객체가 할당될 수 있는 공간과 동시 회수가 진행하는 공간을 나눈다. 새로 생성되는 객체의 주소는 이 두 개의 포인터 보다 무조건 위의 공간에 생성된다. 하지만 객체를 생성하는 속도를 메모리 회수 속도가 따라가지 못한다면 긴 스톱 더 월드를 경험해야 한다.
신뢰 할 수 있는 정지 시간 예측 모델
G1은 회수할 리전을 선택하기 위해 감소 평균이라는 이론을 기반으로한 예측 모델을 사용한다. 리전별 회수 시간, 기업 집합에서 더렵혀진 카드의 수 등 측정할 수 있는 각 단계의 소요 시간을 기록한다. 그리고 이 정보로 부터 평균, 표준 편차, 신뢰도 같은 통계를 분석하여 최근의 평균적인 상태를 통해 어떤 리전을 회수하면 사용자가 설정한 정지 시간 내에 가장 큰 효과를 거둘지 예측하는 것이다.
세넌도어와 ZGC
이 두개의 컬렉터는 거의 모든 과정이 동시에 수행하여 작업스레드의 중지가 발생하는 시간을 극한으로 줄인 컬렉터로 일시 정지가 10밀리초를 넘지 않는다. 이 컬렉터들은 작업 스레드와 대부분의 동작이 동시에 동작하며 세대구분이 없다.(ZGC는 JDK21에서 세대 구분이 추가됨) 이 두개의 컬렉터에 대해선 아직 이해가 부족하여 차 후 시간이 될 때 다시 정리를 해보려고 한다.
