
문서 단어 행렬(Document-Term Matrix, DTM)
: 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것 (서로 다른 문서들의 BoW들을 결합)
ㄴ 서로 다른 문서들 비교 가능
1. 문서 단어 행렬(Document-Term Matrix, DTM)의 표기법
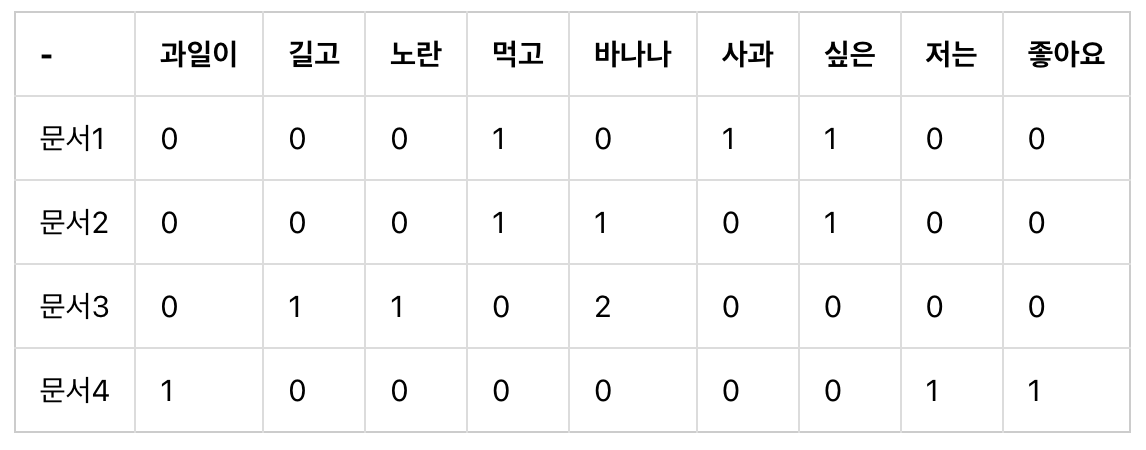
2. 문서 단어 행렬(Document-Term Matrix)의 한계
1) 희소 표현(Sparse representation)
ㄴ 각 문서 벡터의 차원은 전체 단어 집합의 크기
ㄴ 방대한 데이터 -> 문서 벡터의 차원이 굉장히 커짐 -> 대부분의 값이 0
- 희소 벡터(sparse vector) or 희소 행렬(sparse matrix)
: 대부분의 값이 0인 표현
ㄴ 많은 양의 저장 공간, 높은 계산 복잡도 요구
ㄴ 전처리를 사용해 구두점, 빈도수가 낮은 단어, 불용어 제거, 단어 정규화
2) 단순 빈도 수 기반 접근
문서 간 유사도를 판단할 때 빈도 수를 기반으로 하면 오류가 있을 수 있음 (불용어)
불용어와 중요한 단어에 대해 가중치를 주는 방법 -> TF-IDF

connecting the dots