
1. 유클리드 거리(Euclidean distance)
: 다차원 공간에서 두개의 점 p와 q가 각각 p=(p{1}, p{2}, p{3}, ... , p{n})과 q=(q{1}, q{2}, q{3}, ..., q{n})의 좌표를 가질 때 두 점 사이의 거리 계산
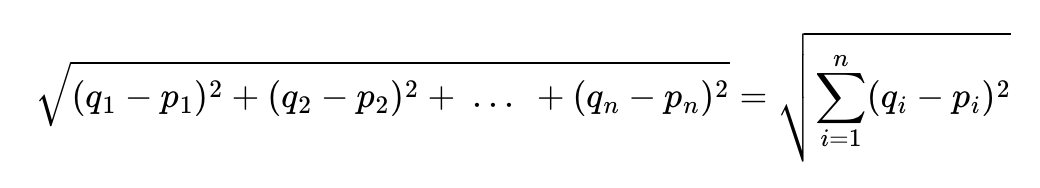

ㄴ 2차원 좌표 평면 상에서 두 점 p와 q사이의 직선 거리를 구하는 문제 (피타고라스 정리)
ㄴ 문서의 유사도: 2차원을 단어의 총 개수만큼의 차원으로 확장하는 것
import numpy as np
def dist(x,y):
return np.sqrt(np.sum((x-y)**2))
doc1 = np.array((2,3,0,1))
doc2 = np.array((1,2,3,1))
doc3 = np.array((2,1,2,2))
docQ = np.array((1,1,0,1))
print('문서1과 문서Q의 거리 :',dist(doc1,docQ))
print('문서2과 문서Q의 거리 :',dist(doc2,docQ))
print('문서3과 문서Q의 거리 :',dist(doc3,docQ))
# 유클리드 거리 값이 작을수록 문서간 유사도가 높음
문서1과 문서Q의 거리 : 2.23606797749979
문서2과 문서Q의 거리 : 3.1622776601683795
문서3과 문서Q의 거리 : 2.4494897427831782. 자카드 유사도(Jaccard similarity)
: 합집합에서 교집합의 비율, 0과 1사이의 값 (동일: 1, 공통 원소 X: 0)
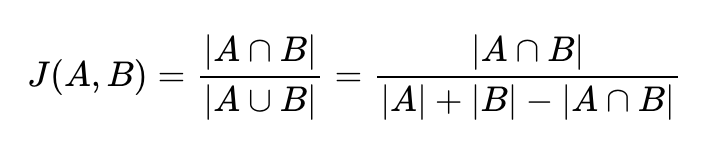
ㄴ 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값
doc1 = "apple banana everyone like likey watch card holder"
doc2 = "apple banana coupon passport love you"
# 토큰화
tokenized_doc1 = doc1.split()
tokenized_doc2 = doc2.split()
print('문서1 :',tokenized_doc1)
print('문서2 :',tokenized_doc2)
# 문서1 : ['apple', 'banana', 'everyone', 'like', 'likey', 'watch', 'card', 'holder']
# 문서2 : ['apple', 'banana', 'coupon', 'passport', 'love', 'you']
union = set(tokenized_doc1).union(set(tokenized_doc2))
print('문서1과 문서2의 합집합 :',union)
# 문서1과 문서2의 합집합 : {'you', 'passport', 'watch', 'card', 'love', 'everyone', 'apple', 'likey', 'like', 'banana', 'holder', 'coupon'}
intersection = set(tokenized_doc1).intersection(set(tokenized_doc2))
print('문서1과 문서2의 교집합 :',intersection)
# 문서1과 문서2의 교집합 : {'apple', 'banana'}
print('자카드 유사도 :',len(intersection)/len(union))
# 자카드 유사도 : 0.16666666666666666
connecting the dots
정리 감사합니다 👍