
1. 벡터와 행렬과 텐서
- 벡터: 크기와 방향을 가진 양
숫자가 나열된 형상
파이썬) 1차원 배열 또는 리스트로 표현 - 행렬: 행과 열을 가지는 2차원 형상을 가진 구조
파이썬) 2차원 배열로 표현
가로줄을 행(row), 세로줄을 열(column)이라고 함 - 텐서: 3차원 이상의 배열
2. 텐서(Tensor)
인공 신경망: 복잡한 모델 내의 연산을 주로 행렬 연산을 통해 해결
텐서의 크기(shape): 각 축을 따라서 얼마나 많은 차원이 있는지를 나타낸 값
1) 0차원 텐서(스칼라)
- 스칼라: 하나의 실수값으로 이루어진 데이터
d = np.array(5)
# ndim을 출력했을 때 나오는 값을 축(axis)의 개수 또는 텐서의 차원이라고 부름
print('텐서의 차원 :',d.ndim)
print('텐서의 크기(shape) :',d.shape)
텐서의 차원 : 0
텐서의 크기(shape) : ()2) 1차원 텐서(벡터)
- 벡터: 숫자를 배열한 것
d = np.array([1, 2, 3, 4])
print('텐서의 차원 :',d.ndim)
print('텐서의 크기(shape) :',d.shape)
텐서의 차원 : 1
# 벡터의 차원: 하나의 축에 놓인 원소의 개수
텐서의 크기(shape) : (4,)3) 2차원 텐서(행렬)
- 행렬: 행과 열이 존재하는 벡터의 배열 (matrix)
# 3행 4열의 행렬
d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
print('텐서의 차원 :',d.ndim)
print('텐서의 크기(shape) :',d.shape)
텐서의 차원 : 2
텐서의 크기(shape) : (3, 4)4) 3차원 텐서(다차원 배열)
- 3차원 텐서: 행렬 또는 2차원 텐서를 단위로 한 번 더 배열 (본격적으로 텐서라고 부름)
d = np.array([
[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [10, 11, 12, 13, 14]],
[[15, 16, 17, 18, 19], [19, 20, 21, 22, 23], [23, 24, 25, 26, 27]]
])
print('텐서의 차원 :',d.ndim)
print('텐서의 크기(shape) :',d.shape)
텐서의 차원 : 3
텐서의 크기(shape) : (2, 3, 5)자연어 처리에서 자주 사용 (시퀀스 데이터(ex. 문장, 뉴스 등)를 표현할 때 자주 사용)
ㄴ 3D 텐서: samples, timesteps, word_dim, batch_size
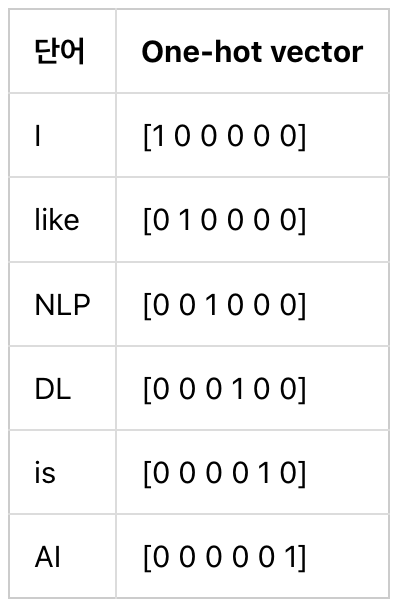
[[[1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0]],
[[1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0]],
[[0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 1]]]
: (3, 3, 6)의 크기를 가지는 3D 텐서
훈련 데이터를 다수 묶어 입력으로 사용하는 것 -> 딥 러닝에서 배치(Batch)라고 함
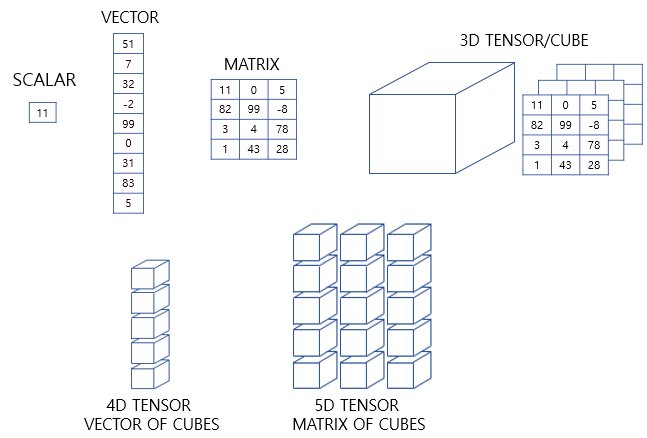
5) 그 이상의 텐서
- 3차원 텐서를 배열로 합치면 4차원 텐서
- 4차원 텐서를 배열로 합치면 5차원 텐서
6) 케라스에서의 텐서
- input_shape: 신경망의 층에 입력의 크기(shape)를 인자로 줄 때 사용
인자: (input_length, input_dim)
3. 벡터와 행렬의 연산
1) 벡터와 행렬의 덧셈과 뺄셈
같은 크기의 두 개의 벡터나 행렬 -> 덧셈, 뺄셈 가능
같은 위치의 원소끼리 연산: 요소별(element-wise) 연산
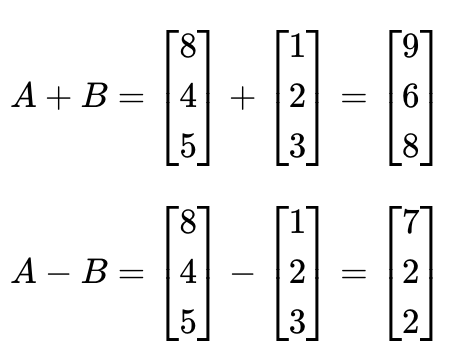
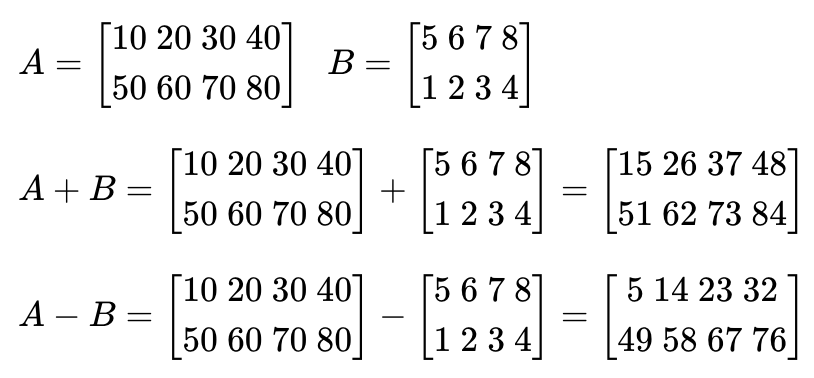
2) 벡터의 내적과 행렬의 곱셈
- 벡터의 내적: 연산을 점(dot)으로 표현 (a・b)
성립 요건) 두 벡터의 차원이 같아야 하며, 두 벡터 중 앞의 벡터가 행벡터(가로 방향 벡터)이고 뒤의 벡터가 열벡터(세로 방향 벡터)여야 함
벡터의 내적 결과) 스칼라
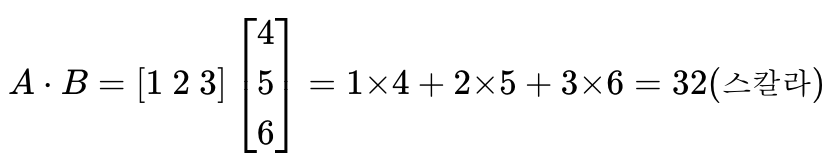
A = np.array([1, 2, 3])
B = np.array([4, 5, 6])
print('두 벡터의 내적 :',np.dot(A, B))
두 벡터의 내적 : 32- 행렬의 곱셈: 왼쪽 행렬의 행벡터와 오른쪽 행렬의 열벡터의 내적(대응하는 원소들의 곱의 합)
성립 요건)
두 행렬의 곱 AXB가 성립되기 위해서는 행렬 A의 열의 개수와 행렬 B의 행의 개수는 같아야 함
두 행렬의 곱 AXB의 결과로 나온 행렬 AB의 크기는 A의 행의 개수와 B의 열의 개수를 가짐
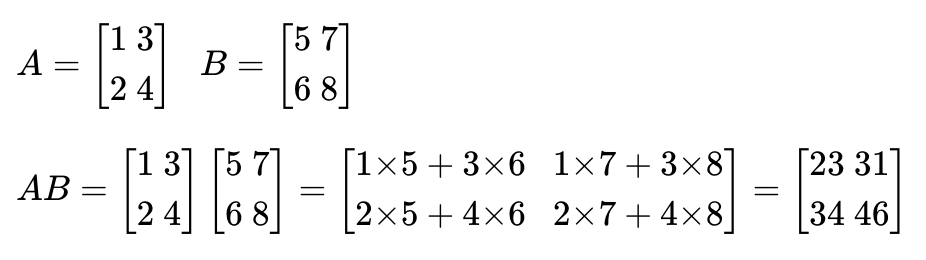
A = np.array([[1, 3],[2, 4]])
B = np.array([[5, 7],[6, 8]])
print('두 행렬의 행렬곱 :')
print(np.matmul(A, B))
두 행렬의 행렬곱 :
[[23 31]
[34 46]]4. 다중 선형 회귀 행렬 연산으로 이해하기
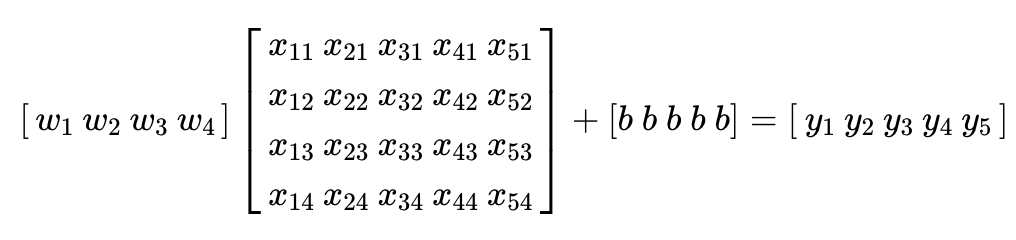
입력 행렬 X는 5행 4열, 출력 벡터 Y는 5행 1열 -> 가중치 벡터 W의 크기는 4행 1열을 가져야 함
5. 샘플(Sample)과 특성(Feature)
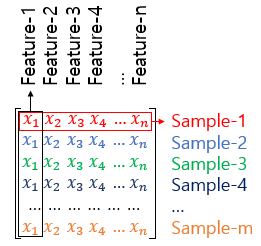
6. 가중치와 편향 행렬의 크기 결정
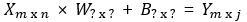
- 행렬의 덧셈에 해당되는 B(편향)행렬: Y행렬의 크기에 영향 X (같음)
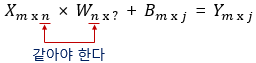
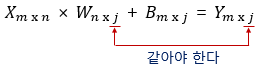
- 입력 행렬(X)과 출력 행렬(Y)의 크기로부터 가중치 행렬과 편향 행렬의 크기를 추정할 수 있다면, 딥 러닝 모델을 구현하였을 때 해당 모델에 존재하는 총 매개변수의 개수를 계산하기 쉬움

connecting the dots