
1. 아이리스 품종 데이터에 대한 이해 및 전처리
샘플의 개수 : 150
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
0 1 5.1 3.5 1.4 0.2 Iris-setosa
1 2 4.9 3.0 1.4 0.2 Iris-setosa
2 3 4.7 3.2 1.3 0.2 Iris-setosa
3 4 4.6 3.1 1.5 0.2 Iris-setosa
4 5 5.0 3.6 1.4 0.2 Iris-setosasns.set(style="ticks", color_codes=True)
g = sns.pairplot(data, hue="Species", palette="husl")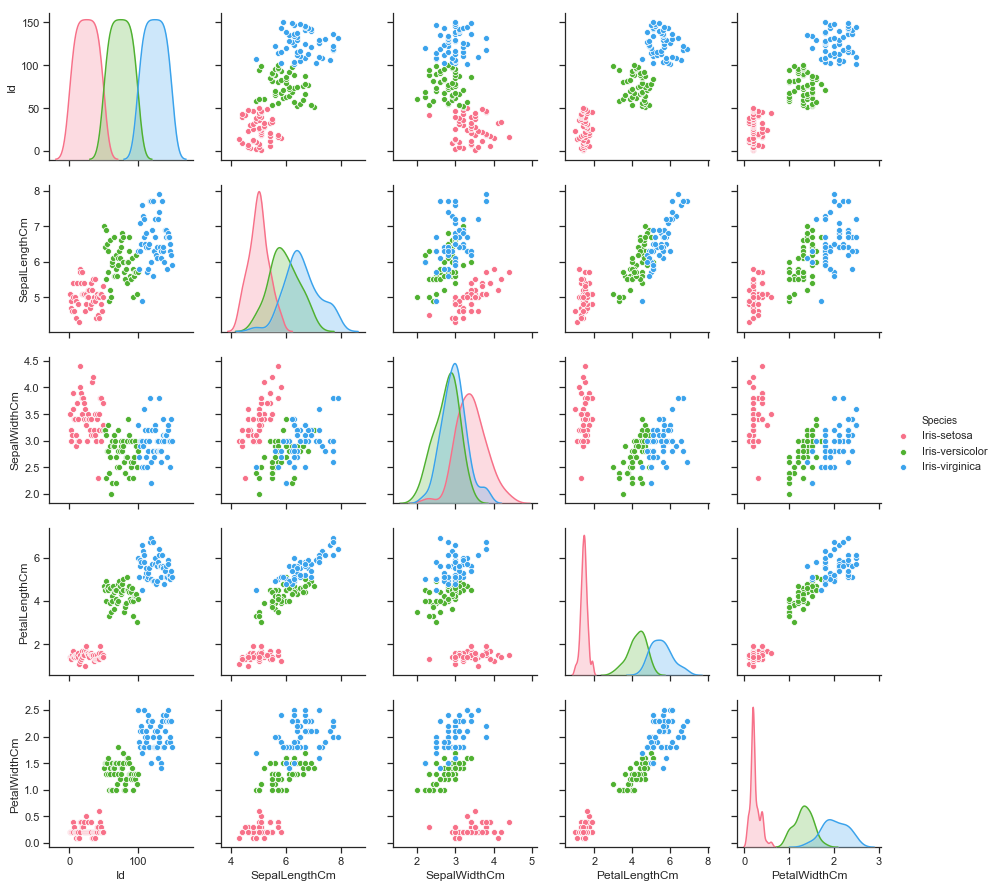
# 원-핫 인코딩 수행 전 정수 인코딩
# Iris-virginica는 0, Iris-setosa는 1, Iris-versicolor는 2가 됨.
data['Species'] = data['Species'].replace(['Iris-virginica','Iris-setosa','Iris-versicolor'],[0,1,2])
# 종속 변수와 독립 변수 데이터로 분리
# X 데이터, 특성은 총 4개
data_X = data[['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm']].values
# Y 데이터, 예측 대상
data_y = data['Species'].values
# 훈련 데이터와 테스트 데이터를 8:2로 분리
(X_train, X_test, y_train, y_test) = train_test_split(data_X, data_y, train_size=0.8, random_state=1)
# 원-핫 인코딩
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)2. 소프트맥스 회귀
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(3, input_dim=4, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 옵티마이저는 경사 하강법의 일종인 아담(adam) 사용
history = model.fit(X_train, y_train, epochs=200, batch_size=1, validation_data=(X_test, y_test))
# accuracy: 훈련 데이터에 대한 정확도
# val_accuracy: 테스트 데이터에 대한 정확도
# 한 번 에포크에 따른 정확도
epochs = range(1, len(history.history['accuracy']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()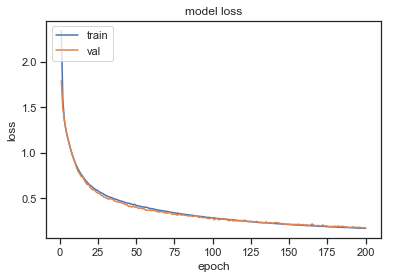
ㄴ 에포크가 증가함에 따라 오차(loss)가 점차적으로 줄어듦
print("\n 테스트 정확도: %.4f" % (model.evaluate(X_test, y_test)[1]))
# 테스트 정확도: 0.9667
connecting the dots