| 선택정렬 | 삽입정렬 | 버블정렬 | 병합정렬 | 힙정렬 | 퀵정렬 | 트리정렬 | 팀정렬 |
|---|---|---|---|---|---|---|---|
| n^2 | n^2 | n^2 | nlogn | nlogn | nlogn | nlogn | nlogn |
1. 선택정렬
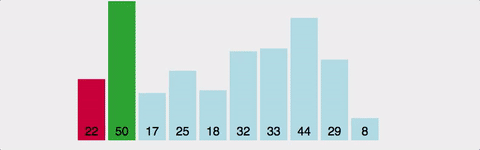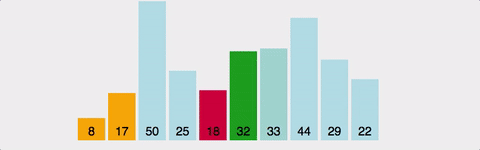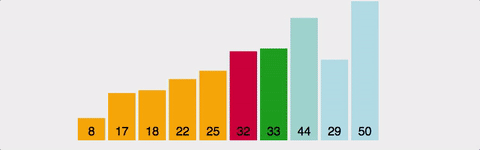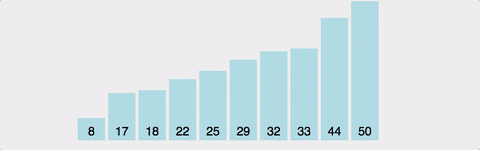
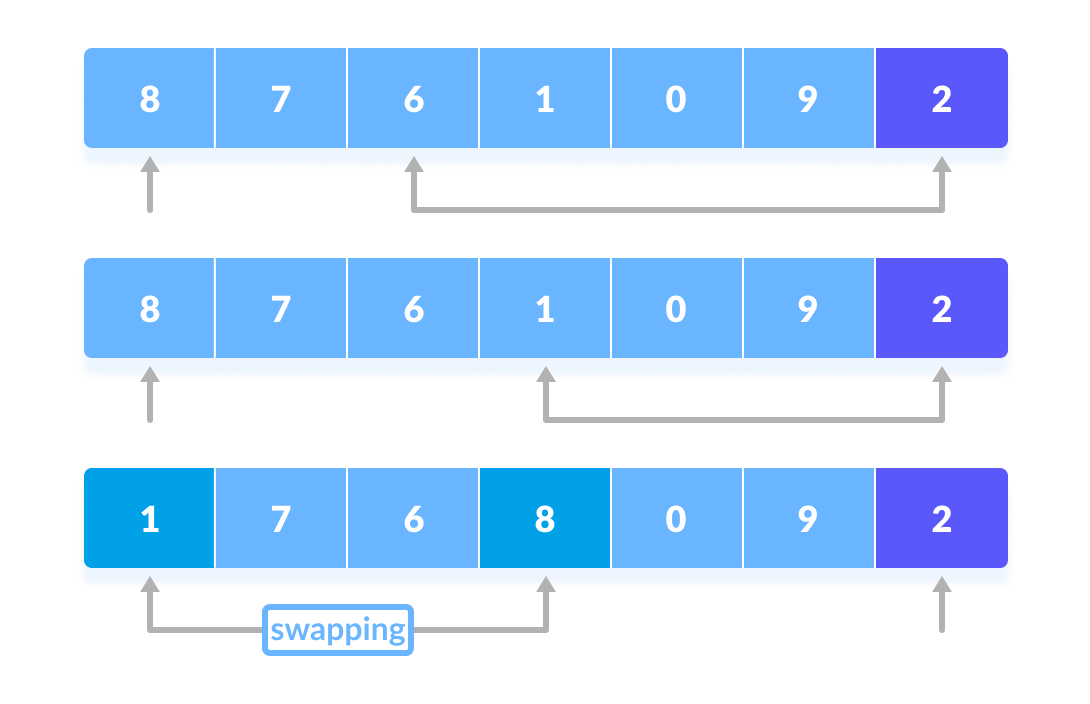
1번째부터 끝까지 훑어서 가장 작은 게 1번째, 2번째부터 끝까지 훑어서 가장 작은 게 2번째... 정렬이 끝날 때까지 반복한다. 이미 정렬되어 있는 자료구조에 삽입/제거 할 때나 배열이 작은 경우에는 매우 효율적이다.
- 코드
oid selectionSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
int minIdx = i;
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < arr[minIdx]) {
minIdx = j;
}
}
swap(arr, i, minIdx);
}
}- 시간 복잡도
- Avg: O(n^2)
- Worst: O(n^2)
- Best: O(n^2)
2. 삽입정렬
k번째 원소를 1부터 k-1까지와 비교해 적절한 위치에 끼워넣고 그 뒤의 자료를 한 칸씩 뒤로 밀어내는 방식이다.
- 코드
void insertionSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int tmp = arr[i];
int j = i - 1;
while (j >= 0 && tmp < arr[j]) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = tmp;
}
}- 시간 복잡도
- Avg: O(n^2)
- Worst: O(n^2)
- Best: O(n)
3. 버블정렬
시간 복잡도가 안좋지만 코드가 단순하다. 원소의 이동이 거품이 수면으로 올라오는 듯한 모습을 보이기 대문에 지어진 이름이다.
- 코드
void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
swap(arr, j, j + 1);
}
}
}
}-
시간 복잡도
- Avg: O(n^2)
- Worst: O(n^2)
- Best: O(n)
4. 병합정렬
배열의 길이가 1이 될 때까지 2개의 부분 배열로 분할한다.
그 후, 2개의 부분 배열을 합병하고 정렬한다. 모든 부분 배열이 합병될 때까지 반복한다.
부분 배열을 위한 추가적인 메모리 공간이 필요하다는 단점이 있다.
- 코드
void insertionSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int tmp = arr[i];
int j = i - 1;
while (j >= 0 && tmp < arr[j]) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = tmp;
}
}- 시간 복잡도
- Avg: O(nlogn)
- Worst: O(nlogn)
- Best: O(nlogn)
5. 힙정렬
선택 정렬과 거의 같지만, 힙을 사용해서 가장 큰 원소를 찾는다는 차이점이 있다.
트리 기반으로 최대 힙 트리(내림차순), 최소 힙 트리(오름차순)을 구성해 정렬한다.
항상 nlogn의 성능을 발휘해 가장 안정적인 성능을 보인다.
다만, 실제로는 퀵정렬이 일반적으로 빠르다.
- 힙이란?
완전 이진 트리의 일종으로 우선순위 큐를 위해 만들어진 자료구조이다. 여러 값 중 최댓값/최솟값을 빠르게 찾도록 만들어진 자료구조이다.- 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 존재한다. (일종의 반정렬상태)
- 이진 탐색 트리와 달리 중복된 값을 허용한다.
- 코드
void heapSort(int[] arr) {
for (int i = arr.length / 2 - 1; i < arr.length; i++) {
heapify(arr, i, arr.length - 1);
}
for (int i = arr.length - 1; i >= 0; i--) {
swap(arr, 0, i);
heapify(arr, 0, i - 1);
}
}
void heapify(int[] arr, int parentIdx, int lastIdx) {
int leftChildIdx;
int rightChildIdx;
int largestIdx;
while (parentIdx * 2 + 1 <= lastIdx) {
leftChildIdx = (parentIdx * 2) + 1;
rightChildIdx = (parentIdx * 2) + 2;
largestIdx = parentIdx;
if (arr[leftChildIdx] > arr[largestIdx]) {
largestIdx = leftChildIdx;
}
if (rightChildIdx <= lastIdx && arr[rightChildIdx] > arr[largestIdx]) {
largestIdx = rightChildIdx;
}
if (largestIdx != parentIdx) {
swap(arr, parentIdx, largestIdx);
parentIdx = largestIdx;
} else {
break;
}
}
}heapify(): parentIdx를 알맞은 자리에 들어가게 하여 최대 힙을 만들어주는 함수이다. 부모노드를 왼쪽 자식, 오른쪽 자식 중 더 큰 자식과 swap을 한다.- 동작 과정
- 배열을 힙 트리로 만든다.
- 배열의 최상단 부모 노드를(0번째) 마지막 인덱스와 교환한다.
- 바뀐 최상단 부모 노드보다 자식의 노드(왼쪽, 오른쪽 중 큰 노드)가 크다면 자식과 위치를 바꾼다. 이를 반복하여 노드의 올바른 위치를 찾는다.
- 2~3번 과정을 반복한다.
- 시간 복잡도
- Avg: O(nlogn)
- Worst: O(nlogn)
- Best: O(nlogn)
6. 퀵정렬
데이터 집합 내에 임의 기준(피벗)값을 정하고, 집합을 해당 피벗을 기준으로 두 개의 부분 집합으로 나눈다. 한 쪽 집합에는 피벗보다 작은 값을, 나머지 한 쪽 집합에는 피벗보다 큰 값을 넣는다. 더 이상 쪼갤 부분 집합이 없을 때까지 위 과정을 반복한다.
- 코드
void quickSort(int[] arr) {
quickSort(arr, 0, arr.length - 1);
}
void quickSort(int[] arr, int left, int right) {
int part = partition(arr, left, right);
if (left < part - 1) {
quickSort(arr, left, part - 1);
}
if (part < right) {
quickSort(arr, part, right);
}
}
int partition(int[] arr, int left, int right) {
int pivot = arr[(left + right) / 2];
while (left <= right) { // 해당 부분 배열에 대해 반복
while (arr[left] < pivot) { //피벗보다 큰 left를 찾음
left++;
}
while (arr[right] > pivot) { //피벗보다 작은 right를 찾음
right--;
}
if (left <= right) { //left가 right보다 왼쪽에 있으면 둘이 자리 바꿈
swap(arr, left, right);
left++;
right--;
}
}
return left;
}- 위 코드에서는
left을 해당 배열의 첫 인덱스,rigth를 마지막 인덱스,pivot을 중간 인덱스 값으로 지정했다. - 동작 과정
- 피벗보다 큰 left를 찾음
- 피벗보다 작은 right를 찾음
- left이 right보다 왼쪽에 있으면 둘이 자리바꾸고 left++, right--
- 1~3번 과정을 해당 배열의 나머지에 대해서 반복
- 집합을 왼쪽 부분 집합, 오른쪽 부분 집합에 대해서 1~4번 과정을 반복
- 단점
- 피벗을 계속 최댓값/최솟값으로 잘못 잡으면 최악의 결과를 초래한다.
- 단점의 해결 방법
- 피벗을 랜덤으로 잡는 것
- 피벗을 배열의 중간 혹은 중간값으로 잡는 것
- 시간 복잡도
- Avg: O(nlogn)
- Worst: O(n^2)
- Best: O(nlogn)
7. 트리정렬

이진 탐색 트리를 만들어 정렬하는 방식이다. 추가될 값이 기존 노드 값보다 작으면 왼쪽 자식으로, 크거나 같으면 오른쪽 자식 위치로 간다. 모든 값이 노드로 추가되었으면 해당 트리를 중위 순회 방식으로 순회하여 값을 정렬한다.
- 시간 복잡도
- Avg: O(nlogn)
- Worst: O(n)
- Best: O(nlogn)
7. 팀정렬
병합+삽입 정렬로 안정적이며 추가 메모리를 사용하지만 병합 정렬에 비해 적은 추가 메모리를 사용해서 다른 알고리즘의 단점을 최대한 극복했다. 파이썬, Java SE 7, 안드로이드, chrome, swift까지 많은 프로그래밍 표준 정렬 알고리즘으로 채택되어 사용되고 있다.
자바의 Collections.sort()는 합병정렬과 팀정렬을 사용한다.
하지만, 자바의 Arrays.sort()는 듀얼피봇 퀵정렬을 사용하고 있다.
* 듀얼피봇 퀵정렬: 피봇 2개를 두고 3개의 구간을 만드는 퀵정렬
- 시간 복잡도
- Avg: O(nlogn)
- Worst: O(n)
- Best: O(nlogn)
그 외의 정렬들
- 칵테일 정렬
- 기수 정렬
- 셀 정렬
- etc...
참조

팀 정렬... 영상 보는데 왜케 힐링되지...